array python 交集_Python数据分析常用知识

此文总结了一些个人在学习python、利用python进行数据分析时用到的一些知识点,主要记录关键语句,便于日后复习与查询用,根据学习进度,持续修改更新,不足之处望见谅。
1、二元运算符

2、用tuple可以将任意序列或迭代器转换成元组
In [5]: tuple([4, 0, 2])
Out[5]: (4, 0, 2)
In [6]: tup = tuple('string')
In [7]: tup
Out[7]: ('s', 't', 'r', 'i', 'n', 'g')3、拆分元组
(1)如果你想将元组赋值给类似元组的变量,Python会试图拆分等号右边的值:
In [15]: tup = (4, 5, 6)
In [16]: a, b, c = tup
In [17]: b
Out[17]: 5(2)Python最近新增了更多高级的元组拆分功能,允许从元组的开头“摘取”几个元素。它使用了特殊的语法*rest,这也用在函数签名中以抓取任意长度列表的位置参数:
In [29]: values = 1, 2, 3, 4, 5
In [30]: a, b, *rest = values
In [31]: a, b
Out[31]: (1, 2)
In [32]: rest
Out[32]: [3, 4, 5]4、列表
(1)用list或[ ]生成列表
(2)添加与删除元素【append、remove、insert、pop】
append在列表末尾添加元素
insert可以在特定的位置插入元素:b_list.insert(1, 'red')
insert的逆运算是pop,它移除并返回指定位置的元素:
In [49]: b_list.pop(2)
Out[49]: 'peekaboo'
In [50]: b_list
Out[50]: ['foo', 'red', 'baz', 'dwarf']in与not in 测试某个元素是否在列表中
(3)串联和组合列表
可以用加号将两个列表串联起来:
In [57]: [4, None, 'foo'] + [7, 8, (2, 3)]
Out[57]: [4, None, 'foo', 7, 8, (2, 3)]如果已经定义了一个列表,用extend方法可以追加多个元素:
In [58]: x = [4, None, 'foo']
In [59]: x.extend([7, 8, (2, 3)])
In [60]: x
Out[60]: [4, None, 'foo', 7, 8, (2, 3)]通过加法将列表串联的计算量较大,因为要新建一个列表,并且要复制对象。用extend追加元素,尤其是到一个大列表中,更为可取。
(4)排序
sort函数将一个列表原地排序
In [61]: a = [7, 2, 5, 1, 3]
In [62]: a.sort()
In [63]: a
Out[63]: [1, 2, 3, 5, 7] sort有一些选项,有时会很好用。其中之一是二级排序key,可以用这个key进行排序。例如,我们可以按长度对字符串进行排序:
In [64]: b = ['saw', 'small', 'He', 'foxes', 'six']
In [65]: b.sort(key=len)
In [66]: b
Out[66]: ['He', 'saw', 'six', 'small', 'foxes'](5)切片
用切边可以选取大多数序列类型的一部分,切片的基本形式是在方括号中使用start:stop
In [73]: seq = [7, 2, 3, 7, 5, 6, 0, 1]
In [74]: seq[1:5]
Out[74]: [2, 3, 7, 5]切片也可以被序列赋值
In [75]: seq[3:4] = [6, 3]
In [76]: seq
Out[76]: [7, 2, 3, 6, 3, 5, 6, 0, 1]5、序列函数
(1)enumerate
Python内建了一个enumerate函数,可以返回(i, value)元组序列
for i, value in enumerate(collection):
(2)zip函数
In [89]: seq1 = ['foo', 'bar', 'baz']
In [90]: seq2 = ['one', 'two', 'three']
In [91]: zipped = zip(seq1, seq2)
In [92]: list(zipped)
Out[92]: [('foo', 'one'), ('bar', 'two'), ('baz', 'three')](3)reversed函数
reversed可以从后向前迭代一个序列
In [100]: list(reversed(range(10)))
Out[100]: [9, 8, 7, 6, 5, 4, 3, 2, 1, 0](4)可以用del关键字或pop方法(返回值的同时删除键)删除值:
6、用序列创建字典
常常,你可能想将两个序列配对组合成字典。
mapping = {}
for key, value in zip(key_list, value_list):
mapping[key] = value7、集合
集合是无序的不可重复的元素的集合。你可以把它当做字典,但是只有键没有值。可以用两种方式创建集合:通过set函数或使用尖括号set语句:
In [133]: set([2, 2, 2, 1, 3, 3])
Out[133]: {1, 2, 3}
In [134]: {2, 2, 2, 1, 3, 3}
Out[134]: {1, 2, 3}集合支持合并、交集、差分和对称差等数学集合运算。考虑两个示例集合:
In [135]: a = {1, 2, 3, 4, 5}
In [136]: b = {3, 4, 5, 6, 7, 8}合并是取两个集合中不重复的元素。可以用union方法,或者|运算符:
In [137]: a.union(b)
Out[137]: {1, 2, 3, 4, 5, 6, 7, 8}
In [138]: a | b
Out[138]: {1, 2, 3, 4, 5, 6, 7, 8}交集的元素包含在两个集合中。可以用intersection或&运算符:
In [139]: a.intersection(b)
Out[139]: {3, 4, 5}
In [140]: a & b
Out[140]: {3, 4, 5}集合常用方法
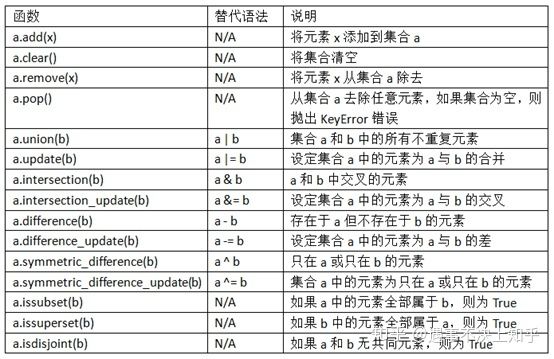
你还可以检测一个集合是否是另一个集合的子集或父集:
In [150]: a_set = {1, 2, 3, 4, 5}
In [151]: {1, 2, 3}.issubset(a_set)
Out[151]: True
In [152]: a_set.issuperset({1, 2, 3})
Out[152]: True集合的内容相同时,集合才对等:
In [153]: {1, 2, 3} == {3, 2, 1}
Out[153]: True8、列表、集合和字典推导式
列表推导式是Python最受喜爱的特性之一。它允许用户方便的从一个集合过滤元素,形成列表,在传递参数的过程中还可以修改元素。形式如下:
[expr for val in collection if condition]
dict_comp = {key-expr : value-expr for value in collection if condition}
set_comp = {expr for value in collection if condition}
In [154]: strings = ['a', 'as', 'bat', 'car', 'dove', 'python']
In [155]: [x.upper() for x in strings if len(x) > 2]
Out[155]: ['BAT', 'CAR', 'DOVE', 'PYTHON']9、生成器表达式
(1)生成器
生成器(generator)是构造新的可迭代对象的一种简单方式。一般的函数执行之后只会返回单个值,而生成器则是以延迟的方式返回一个值序列,即每返回一个值之后暂停,直到下一个值被请求时再继续。要创建一个生成器,只需将函数中的return替换为yeild即可:
def squares(n=10):
print('Generating squares from 1 to {0}'.format(n ** 2))
for i in range(1, n + 1):
yield i ** 2(2)生成器表达式
其创建方式为,把列表推导式两端的方括号改成圆括号:
In [189]: gen = (x ** 2 for x in range(100))
In [190]: gen
Out[190]: at 0x7fbbd5ab29e8> 10、NumPy的ndarray:一种多维数组对象
创建数组最简单的办法就是使用array函数。它接受一切序列型的对象(包括其他数组),然后产生一个新的含有传入数据的NumPy数组。以一个列表的转换为例:
In [19]: data1 = [6, 7.5, 8, 0, 1]
In [20]: arr1 = np.array(data1)
In [21]: arr1
Out[21]: array([ 6. , 7.5, 8. , 0. , 1. ])11、NumPy数组的运算
数组很重要,因为它使你不用编写循环即可对数据执行批量运算。NumPy用户称其为矢量化(vectorization)。大小相等的数组之间的任何算术运算都会将运算应用到元素级:
(1)一元ufunc


(2)二元ufunc


(3)将条件逻辑表述为数组运算
numpy.where函数是三元表达式x if condition else y的矢量化版本
In [165]: xarr = np.array([1.1, 1.2, 1.3, 1.4, 1.5])
In [166]: yarr = np.array([2.1, 2.2, 2.3, 2.4, 2.5])
In [167]: cond = np.array([True, False, True, True, False])假设我们想要根据cond中的值选取xarr和yarr的值:当cond中的值为True时,选取xarr的值,否则从yarr中选取。列表推导式的写法应该如下所示:
In [168]: result = [(x if c else y)
.....: for x, y, c in zip(xarr, yarr, cond)]这有几个问题。第一,它对大数组的处理速度不是很快(因为所有工作都是由纯Python完成的)。第二,无法用于多维数组。若使用np.where,则可以将该功能写得非常简洁:
In [170]: result = np.where(cond, xarr, yarr)
In [171]: result
Out[171]: array([ 1.1, 2.2, 1.3, 1.4, 2.5])(4)基本数组统计方法


(5)数组的集合运算

(6)线性代数

(7)numpy.random中的部分函数


12、pandas的数据结构介绍
要使用pandas,你首先就得熟悉它的两个主要数据结构:Series和DataFrame。虽然它们并不能解决所有问题,但它们为大多数应用提供了一种可靠的、易于使用的基础。
eries是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据即可产生最简单的Series:
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。DataFrame中的数据是以一个或多个二维块存放的(而不是列表、字典或别的一维数据结构)。有关DataFrame内部的技术细节远远超出了本书所讨论的范围。
(1)创建DataFrame
最常用的一种是直接传入一个由等长列表或NumPy数组组成的字典:
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002, 2003],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]}
frame = pd.DataFrame(data)如果指定了列序列,则DataFrame的列就会按照指定顺序进行排列:
In [47]: pd.DataFrame(data, columns=['year', 'state', 'pop'])
你也可以使用类似NumPy数组的方法,对DataFrame进行转置(交换行和列):
In [68]: frame3.T
Out[68]:
2000 2001 2002
Nevada NaN 2.4 2.9
Ohio 1.5 1.7 3.6(2)dataframe索引
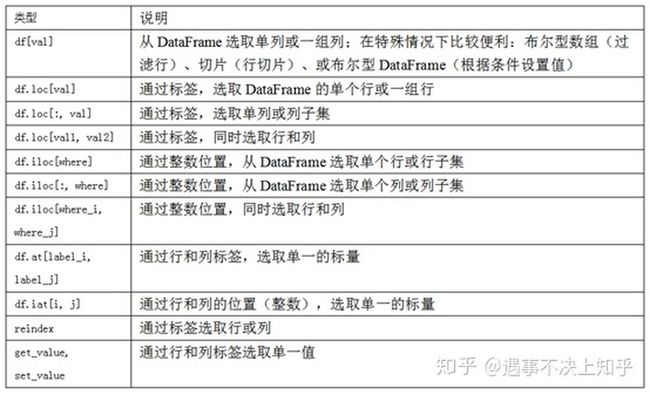
(3)描述和汇总统计

(4)相关系数与协方差
(5)唯一值、值计数以及成员资格

13、数据清洗和准备
在数据分析和建模的过程中,相当多的时间要用在数据准备上:加载、清理、转换以及重塑。这些工作会占到分析师时间的80%或更多。
(1)缺失数据

14、利用函数或映射进行数据转化
对于许多数据集,你可能希望根据数组、Series或DataFrame列中的值来实现转换工作
data = pd.DataFrame({'food': ['bacon', 'pulled pork', 'bacon',
....: 'Pastrami', 'corned beef', 'Bacon',
....: 'pastrami', 'honey ham', 'nova lox'],
....: 'ounces': [4, 3, 12, 6, 7.5, 8, 3, 5, 6]})假设你想要添加一列表示该肉类食物来源的动物类型。我们先编写一个不同肉类到动物的映射:
meat_to_animal = {
'bacon': 'pig',
'pulled pork': 'pig',
'pastrami': 'cow',
'corned beef': 'cow',
'honey ham': 'pig',
'nova lox': 'salmon'
}Series的map方法可以接受一个函数或含有映射关系的字典型对象,但是这里有一个小问题,即有些肉类的首字母大写了,而另一些则没有。因此,我们还需要使用Series的str.lower方法,将各个值转换为小写:
(1)food列转换为小写
lowercased = data['food'].str.lower()(2)新生成animal列
data['animal'] = lowercased.map(meat_to_animal)(3)对原有food列进行修改
data['food'].map(lambda x: meat_to_animal[x.lower()])使用map是一种实现元素级转换以及其他数据清理工作的便捷方式。
15、替换值(fillna、replace)
利用fillna方法填充缺失数据可以看做值替换的一种特殊情况。前面已经看到,map可用于修改对象的数据子集,而replace则提供了一种实现该功能的更简单、更灵活的方式
data = pd.Series([1., -999., 2., -999., -1000., 3.])
data.replace(-999, np.nan)如果你希望一次性替换多个值,可以传入一个由待替换值组成的列表以及一个替换值:
data.replace([-999, -1000], np.nan)要让每个值有不同的替换值,可以传递一个替换列表:
data.replace([-999, -1000], [np.nan, 0])传入的参数也可以是字典:
data.replace({-999: np.nan, -1000: 0})16、轴索引重命名
跟Series中的值一样,轴标签也可以通过函数或映射进行转换,从而得到一个新的不同标签的对象。轴还可以被就地修改,而无需新建一个数据结构。
In [66]: data = pd.DataFrame(np.arange(12).reshape((3, 4)),
....: index=['Ohio', 'Colorado', 'New York'],
....: columns=['one', 'two', 'three', 'four'])如果想要创建数据集的转换版(而不是修改原始数据),比较实用的方法是rename:
data.rename(index=str.title, columns=str.upper)17、离散化和面元划分
为了便于分析,连续数据常常被离散化或拆分为“面元”(bin)。假设有一组人员数据,而你希望将它们划分为不同的年龄组:
ages = [20, 22, 25, 27, 21, 23, 37, 31, 61, 45, 41, 32]接下来将这些数据划分为“18到25”、“26到35”、“35到60”以及“60以上”几个面元。要实现该功能,你需要使用pandas的cut函数:
bins = [18, 25, 35, 60, 100]
cats = pd.cut(ages, bins)
pd.value_counts(cats)
Out[81]:
(18, 25] 5
(35, 60] 3
(25, 35] 3
(60, 100] 1
dtype: int64跟“区间”的数学符号一样,圆括号表示开端,而方括号则表示闭端(包括)。哪边是闭端可以通过right=False进行修改:
pd.cut(ages, [18, 26, 36, 61, 100], right=False)你可 以通过传递一个列表或数组到labels,设置自己的面元名称:
In [83]: group_names = ['Youth', 'YoungAdult', 'MiddleAged', 'Senior']
In [84]: pd.cut(ages, bins, labels=group_names)
Out[84]:
[Youth, Youth, Youth, YoungAdult, Youth, ..., YoungAdult, Senior, MiddleAged, Mid
dleAged, YoungAdult]
Length: 12
Categories (4, object): [Youth < YoungAdult < MiddleAged < Senior]18、检测和过滤异常值
data = pd.DataFrame(np.random.randn(1000, 4))
data.describe() #查勘数据的概要统计指标
col = data[2]
col[np.abs(col) > 3]
data[(np.abs(data) > 3).any(1)]根据数据的值是正还是负,np.sign(data)可以生成1和-1:
data[np.abs(data) > 3] = np.sign(data) * 3any&all扩展补充知识:
一个总的原则就是“any”意味着一行或者一列有一个为真(这里一般指不为0)则返回真,一行或者一列全部为假(一般指0)才为假,”all“意味着一行或者一列所有为真才为真(均不等于0),一行或者一列有一个为假则为假。
DataFrame.all(axis=None, bool_only=None, skipna=None, level=None, **kwargs) 返回的是在给定的轴上,是否有元素为真
参数:
1、axis,0/1,默认为0轴
2、skipna,布尔值,默认为True,若整行或整列为NA则返回NA
3、level,整数,默认为空,当层次化索引时使用
4、bool_only,只考虑布尔值,默认为False
19、排列和随机采样
利用numpy.random.permutation函数可以轻松实现对Series或DataFrame的列的排列工作(permuting,随机重排序)。通过需要排列的轴的长度调用permutation,可产生一个表示新顺序的整数数组:
20、计算指标、哑变量
另一种常用于统计建模或机器学习的转换方式是:将分类变量(categorical variable)转换为“哑变量”或“指标矩阵”。
如果DataFrame的某一列中含有k个不同的值,则可以派生出一个k列矩阵或DataFrame(其值全为1和0)。pandas有一个get_dummies函数可以实现该功能(其实自己动手做一个也不难)。使用之前的一个DataFrame例子:
In [109]: df = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'b'],
.....: 'data1': range(6)})
In [110]: pd.get_dummies(df['key'])
Out[110]:
a b c
0 0 1 0
1 0 1 0
2 1 0 0
3 0 0 1
4 1 0 0
5 0 1 021、字符串操作
(1)以逗号分隔的字符串可以用split拆分成数段
In [134]: val = 'a,b, guido'
In [135]: val.split(',')
Out[135]: ['a', 'b', 'guido'](2)split常常与strip一起使用,以去除空白符(包括换行符)
(3)Python内置字符串方法


22、python矢量化字符串函数
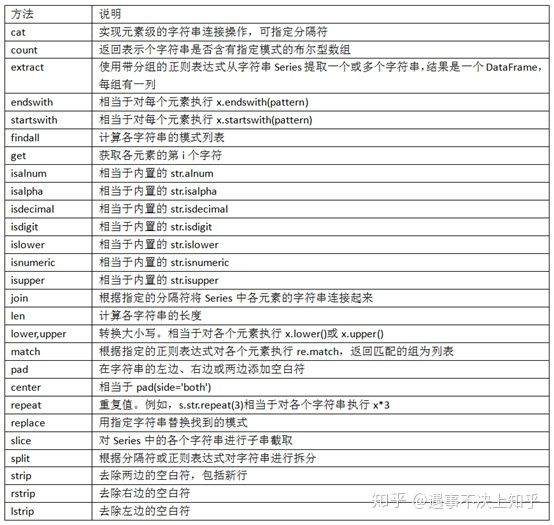
23、层次化索引
层次化索引(hierarchical indexing)是pandas的一项重要功能,它使你能在一个轴上拥有多个(两个以上)索引级别。抽象点说,它使你能以低维度形式处理高维度数据。我们先来看一个简单的例子:创建一个Series,并用一个由列表或数组组成的列表作为索引:
data = pd.Series(np.random.randn(9),
index=[['a', 'a', 'a', 'b', 'b', 'c', 'c', 'd', 'd'],
[1, 2, 3, 1, 3, 1, 2, 2, 3]])
In [10]: data
Out[10]:
a 1 -0.204708
2 0.478943
3 -0.519439
b 1 -0.555730
3 1.965781
c 1 1.393406
2 0.092908
d 2 0.281746
3 0.769023
dtype: float64对于一个层次化索引的对象,可以使用所谓的部分索引,使用它选取数据子集的操作更简单:
In [12]: data['b']
Out[12]:
1 -0.555730
3 1.965781
dtype: float64
In [13]: data['b':'c']
Out[13]:
b 1 -0.555730
3 1.965781
c 1 1.393406
2 0.092908
dtype: float64
In [14]: data.loc[['b', 'd']]
Out[14]:
b 1 -0.555730
3 1.965781
d 2 0.281746
3 0.769023
dtype: float64有时甚至还可以在“内层”中进行选取:
In [15]: data.loc[:, 2]
Out[15]:
a 0.478943
c 0.092908
d 0.281746
dtype: float64层次化索引在数据重塑和基于分组的操作(如透视表生成)中扮演着重要的角色。例如,可以通过unstack方法将这段数据重新安排到一个DataFrame中:
data.unstack()
Out[16]:
1 2 3
a -0.204708 0.478943 -0.519439
b -0.555730 NaN 1.965781
c 1.393406 0.092908 NaN
d NaN 0.281746 0.769023unstack的逆运算是stack:
In [17]: data.unstack().stack()
Out[17]:
a 1 -0.204708
2 0.478943
3 -0.519439
b 1 -0.555730
3 1.965781
c 1 1.393406
2 0.092908
d 2 0.281746
3 0.769023
dtype: float64对于一个DataFrame,每条轴都可以有分层索引:
In [18]: frame = pd.DataFrame(np.arange(12).reshape((4, 3)),
....: index=[['a', 'a', 'b', 'b'], [1, 2, 1, 2]],
....: columns=[['Ohio', 'Ohio', 'Colorado'],
....: ['Green', 'Red', 'Green']])
In [19]: frame
Out[19]:
Ohio Colorado
Green Red Green
a 1 0 1 2
2 3 4 5
b 1 6 7 8
2 9 10 1124、创建DataFrame的几种方式
(1)使用numpy创建
df=pd.DataFrame(np.arange(16).reshape((4,4)),
index=list('abcd'),
columns=['one','two','three','four'])(2)由Series组成的字典
df3 = pd.DataFrame({'one':pd.Series([0,1,2,3]),
'two':pd.Series([4,5,6,7]),
'three':pd.Series([8,9,10,11]),
'four':pd.Series([12,13,14,15])},
columns=['one','two','three','four'])自定义行索引
df4 = pd.DataFrame({'one':pd.Series([0,1,2,3],index=list('abcd')),
'two':pd.Series([4,5,6,7],index=list('abcd')),
'three':pd.Series([8,9,10,11],index=list('abcd')),
'four':pd.Series([12,13,14,15],index=list('fjkg'))},
columns=['one','two','three','four'])由Series组成的字典,创建Dataframe, columns为字典key, index为Series的标签(如果
Series没有指定标签,则默认数字标签)
(3)由字典或series组成的列表
data = [{"one":1,"two":2},{"one":5,"two":10,"three":15}]
df6 = pd.DataFrame(data)指定行索引列名
df4 = pd.DataFrame(data, columns = ["one", "two", "three"],index=['a','b'])(4)由字典组成字典
data = {
"Jack":{"math":90, "english":89, "art":78},
"Marry":{"math":82, "english":95, "art":96},
"Tom":{"math":85, "english":94}
}
df4 = pd.DataFrame(data, index = ["art", "math", "english"], columns = ["Jack", "Tom", "Bob"])(5)数组、列表、元祖、组成的字典
df2 = pd.DataFrame({
'one':[0,1,2,3],
'two':[4,5,6,7],
'three':[8,9,10,11],
'four':[12,13,14,15]},
index=list('abcd'),
columns=['one','two','three','four'])25、drop函数
(1)drop() 删除行和列
df.drop([ ],axis=0,inplace=True)drop([]),默认情况下删除某一行;
如果要删除某列,需要axis=1;
参数inplace 默认情况下为False,表示保持原来的数据不变,True 则表示在原来的数据上改变。
(2)drop_duplicates()去重
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
subset : column label or sequence of labels, optional
用来指定特定的列,默认所有列
keep : {‘first’, ‘last’, False}, default ‘first’
删除重复项并保留第一次出现的项
inplace : boolean, default False
是直接在原来数据上修改还是保留一个副本26、python取整的几种方法
(1)向下取整
>>> a = 3.75
>>> int(a)
3(2)四舍五入
>>> round(3.25); round(4.85)
3.0
5.0(3)向上取整
>>> import math
>>> math.ceil(3.25)
4.0
>>> math.ceil(3.75)
4.0
>>> math.ceil(4.85)
5.027、删除 DataFrame表的最后一行的正确方法
df.drop([len(df)-1],inplace=True)注意不要用df.drop([-1],inplace=True),这个写法不对
28、删除与增减行列
(1)删除某行某列
df.drop(index=['Bob', 'Dave', 'Frank'],
columns=['state', 'point'])(2)增加某列
df['new']='12'#向 DataFrame 添加一列,该列为同一值(3)增加某行
loc方法:直接改变原来行的值
df.loc[0] = ['羊', 9]不改变原来行的值,新增一行
df = pd.DataFrame({
'动物' : ['狗','猫','兔'],
'数量' : [ 3, 4, 6]
})
df1 = df.loc[:0]
df2 = df.loc[1:]
df3 = pd.DataFrame({
'动物' : ['羊'],
'数量' : [ 9 ]
})
df = df1.append(df3, ignore_index = True).append(df2, ignore_index = True)(4)列表分块与df分块
列表分块
list[a:b] 根据列表元素索引在相应的位置进行拆分
df分块
按索引进行拆分
df1 = df.loc[:10,:] 拆分成前10行
df2 = df.loc[10:,:] 拆分成除df1外的其他数据
按特征进行拆分
columns=df.columns[:5] #前5列特征
df3=df[columns]
columns1=df.columns[5:] #第六列及以后特征
df4=df[columns1]
总结:列表切片形式为list[a:b];dataframe切片形式为df[a:b,c:d]
29、pivot_table
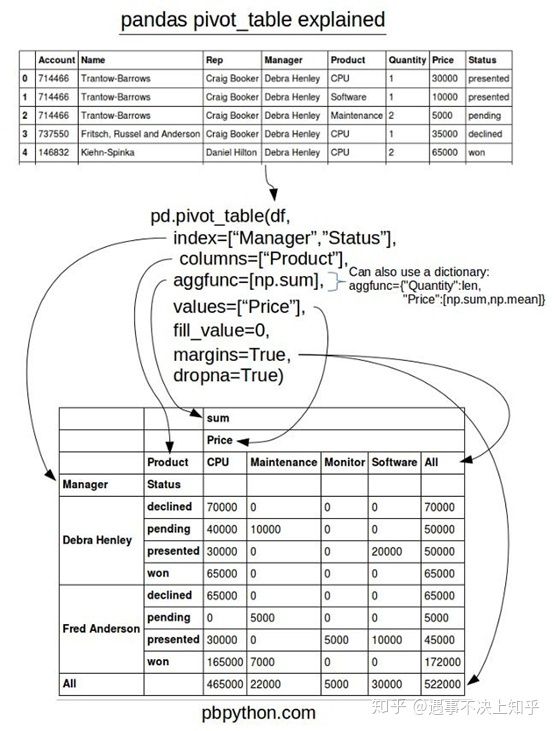
(1)pd.pivot_table(df,index=["Manager","Rep"],values=["Price"],aggfunc=np.sum)
index指定了两个行索引;
values:用于计算的指标值
aggfunc:指标值的计算汇总方式
(2)我认为pivot_table中一个令人困惑的地方是“columns(列)”和“values(值)”的使用。记住,变量“columns(列)”是可选的,它提供一种额外的方法来分割你所关心的实际值。然而,聚合函数aggfunc最后是被应用到了变量“values”中你所列举的项目上。
pd.pivot_table(df,index=["Manager","Rep"],values=["Price"],
columns=["Product"],aggfunc=[np.sum])
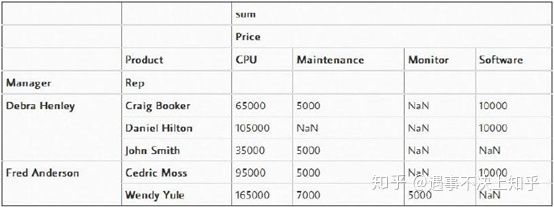
(3)非数值NaN的处理
如果想移除它们,我们可以使用“fill_value”将其设置为0
pd.pivot_table(df,index=["Manager","Rep"],values=["Price"],
columns=["Product"],aggfunc=[np.sum],fill_value=0)

(4)values 包括两个值
pd.pivot_table(df,index=["Manager","Rep"],values=["Price","Quantity"],
columns=["Product"],aggfunc=[np.sum],fill_value=0)有趣的是,你可以将几个项目设置为索引来获得不同的可视化表示。下面的代码中,我们将“Product”从“columns”中移除,并添加到“index”变量中。
pd.pivot_table(df,index=["Manager","Rep","Product"],
values=["Price","Quantity"],aggfunc=[np.sum],fill_value=0)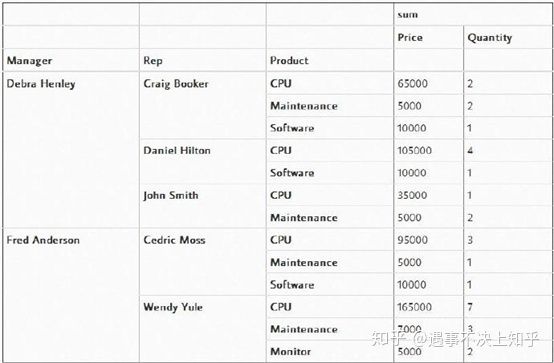
(5)看总和数据
pd.pivot_table(df,index=["Manager","Rep","Product"],
values=["Price","Quantity"],
aggfunc=[np.sum,np.mean],fill_value=0,margins=True)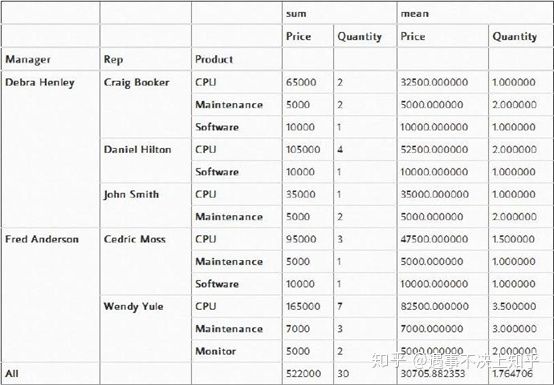
(6)高级透视表过滤
一旦你生成了需要的数据,那么数据将存在于数据帧中。所以,你可以使用自定义的标准数据帧函数来对其进行过滤。
如果你只想查看一个管理者(例如Debra Henley)的数据,可以这样:
table.query('Manager == ["Debra Henley"]')我们可以查看所有的暂停(pending)和成功(won)的交易,代码如下所示:
table.query('Status == ["pending","won"]')图示pivot_table
30、pandas的axis=0或1
使用0值表示沿着每一列或行标签索引值向下执行方法
使用1值表示沿着每一行或者列标签模向执行对应的方法

31、X[:,0]和X[:,1]
X[:,0]就是取所有行的第0个数据, X[:,1] 就是取所有行的第1个数据。
x[:] 冒号左侧表示开始位置,右侧表示结束位置
32、在cmd中查看python版本和安装路径
版本
python -V
安装路径
where python
33、index()方法
index() 函数用于从列表中找出某个值第一个匹配项的索引位置
34、字典及其基本操作
由于字典中的 key 是非常关键的数据,而且程序需要通过 key 来访问 value,因此字典中的 key 不允许重复
(1)创建key-value
scores = {}
scores['数学'] = 93
(2)删除键值对
del scores['数学']
(3)字典方法
clear() 用于清空字典中所有的 key-value 对
get() 方法其实就是根据 key 来获取 value
cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9}
# 获取'BMW'对应的value
print(cars.get('BMW')) # 8.5
update()方法
update() 方法可使用一个字典所包含的 key-value 对来更新己有的字典. 在执行 update() 方法时,如果被更新的字典中己包含对应的 key-value 对,那么原 value 会被覆盖;如果被更新的字典中不包含对应的 key-value 对,则该 key-value 对被添加进去。
cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9}
cars.update({'BMW':4.5, 'PORSCHE': 9.3})
print(cars)items()、keys()、values()
items()、keys()、values() 分别用于获取字典中的所有 key-value 对、所有 key、所有 value。
(4)使用字典格式化字符串
# 字符串模板中使用key
temp = '教程是:%(name)s, 价格是:%(price)010.2f, 出版社是:%(publish)s'
book = {'name':'Python基础教程', 'price': 99, 'publish': 'C语言中文网'}
# 使用字典为字符串模板中的key传入值
print(temp % book)
教程是:Python基础教程, 价格是:0000099.00, 出版社是:C语言中文网
35、Pandas中更改列的数据类型
(1)如果想要将这个操作应用到多个列,依次处理每一列是非常繁琐的,所以可以使用DataFrame.apply处理每一列。
df[['col2','col3']] = df[['col2','col3']].apply(pd.to_numeric)(2)软转换——类型自动推断
版本0.21.0引入了infer_objects()方法,用于将具有对象数据类型的DataFrame的列转换为更具体的类型。
df = df.infer_objects()(3)astype强制转换
df[['two', 'three']] = df[['two', 'three']].astype(float)36、merge、join、concat比较
(1)concat:沿着一条轴,将多个对象堆叠到一起
concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False, copy=True)
objs:需要连接的对象集合,一般是列表或字典;
axis:连接轴向;
join:参数为‘outer’或‘inner’;
join_axes=[]:指定自定义的索引;
keys=[]:创建层次化索引;
ignore_index=True:重建索引pd.concat()只是单纯的把两个表拼接在一起,参数axis是关键,它用于指定是行还是列,axis默认是0。
当axis=0时,pd.concat([obj1, obj2])的效果与obj1.append(obj2)是相同的;
当axis=1时,pd.concat([obj1, obj2], axis=1)的效果与pd.merge(obj1, obj2, left_index=True, right_index=True, how='outer')是相同的。
concat方法不会去重,但是可以使用drop_duplicates方法达到去重的效果。
>>> df1=DataFrame(np.random.randn(3,4),columns=['a','b','c','d'])
>>> df2=DataFrame(np.random.randn(2,3),columns=['b','d','a'])
>>> pd.concat([df1,df2],ignore_index=True) #ignore_index=True 重新生成行索引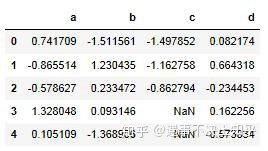
(2)merge:通过键拼接列
类似于关系型数据库的连接方式,可以根据一个或多个键将不同的DatFrame连接起来。该函数的典型应用场景是,针对同一个主键存在两张不同字段的表,根据主键整合到一张表里面。
merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False)
left和right:两个不同的DataFrame;
how:连接方式,有inner、left、right、outer,默认为inner;
on:指的是用于连接的列索引名称,必须存在于左右两个DataFrame中,如果没有指定且其他参数也没有指定,
则以两个DataFrame列名交集作为连接键;
left_on:左侧DataFrame中用于连接键的列名,这个参数左右列名不同但代表的含义相同时非常的有用;
right_on:右侧DataFrame中用于连接键的列名;
left_index:使用左侧DataFrame中的行索引作为连接键;
right_index:使用右侧DataFrame中的行索引作为连接键;
sort:默认为True,将合并的数据进行排序,设置为False可以提高性能;
suffixes:字符串值组成的元组,用于指定当左右DataFrame存在相同列名时在列名后面附加的后缀名称,
默认为('_x', '_y');
copy:默认为True,总是将数据复制到数据结构中,设置为False可以提高性能;
indicator:显示合并数据中数据的来源情况具体例子省略
(3)join:主要用于索引上的合并
(略)
小结:
(1)concat主要用于结构相同的两张或多张表进行合并,可横向、纵向进行;
(2)merge则相当于excel的vlookup函数,以两张表的各自的某列为基准,进行跨表格的数据查找匹配。
37、代码运行时间
import time
start =time.process_time()
代码块
end = time.process_time()
print('Running time: %s Seconds'%(end-start))38、格式化字符串
转换说明符
%d、%i 转换为带符号的十进制整数
%o 转换为带符号的八进制整数
%x、%X 转换为带符号的十六进制整数
%e 转化为科学计数法表示的浮点数(e 小写)
%E 转化为科学计数法表示的浮点数(E 大写)
%f、%F 转化为十进制浮点数
%g 智能选择使用 %f 或 %e 格式
%G 智能选择使用 %F 或 %E 格式
%c 格式化字符及其 ASCII 码
%r 使用 repr() 函数将表达式转换为字符串
%s 使用 str() 函数将表达式转换为字符串
例1
01.age = 8
02.print("C语言中文网已经%d岁了!" % age)例2
01.name = "C语言中文网"
02.age = 8
03.url = "http://c.biancheng.net/"
04.print("%s已经%d岁了,它的网址是%s。" % (name, age, url))例3
%m.nf
%.nf
01.f = 3.141592653
02.# 最小宽度为8,小数点后保留3位
03.print("%8.3f" % f)
04.# 最小宽度为8,小数点后保留3位,左边补0
05.print("%08.3f" % f)
06.# 最小宽度为8,小数点后保留3位,左边补0,带符号
07.print("%+08.3f" % f)39、join函数
>>> seq1 = ['hello','good','boy','doiido']
>>> print (' '.join(seq1))
hello good boy doiido
>>> print ':'.join(seq1)
hello:good:boy:doiido
#对字符串进行操作
>>> seq2 = "hello good boy doiido"
>>> print ':'.join(seq2)
h:e:l:l:o: :g:o:o:d: :b:o:y: :d:o:i:i:d:o
#对元组进行操作
>>> seq3 = ('hello','good','boy','doiido')
>>> print ':'.join(seq3)
hello:good:boy:doiido
#对字典进行操作
>>> seq4 = {
'hello':1,'good':2,'boy':3,'doiido':4}
>>> print ':'.join(seq4)
boy:good:doiido:hello
#合并目录
>>> import os
>>> os.path.join('/hello/','good/boy/','doiido')
'/hello/good/boy/doiido'40、确实数据处理函数
(1)传入how='all'将只丢弃全为NA的那些行
data.dropna(how='all')(2)用这种方式丢弃列,只需传入axis=1即可
data.dropna(axis=1, how='all')41、将一列由小数转化为百分数
data['人员利用率'] = data['人员利用率'].apply(lambda x: format(x, '.2%'))42、apply函数应用
df['day_change_rate']=df.apply(lambda x:
(x['close_price_1']-x['close_price'])/x['close_price'],axis=1)
当axis=1,表示传入的x为行43、排序
df.sort_values(by=['col2','col3'],ascending=False)
ascending=False表示降序排序
## 参数
sort_index(axis=0, level=None, ascending=True, inplace=False, kind='quicksort', na_position='last', sort_remaining=True, by=None)
#### 参数说明
axis:0按照行名排序;1按照列名排序
level:默认None,否则按照给定的level顺序排列---貌似并不是,文档
ascending:默认True升序排列;False降序排列
inplace:默认False,否则排序之后的数据直接替换原来的数据框
kind:默认quicksort,排序的方法
na_position:缺失值默认排在最后{"first","last"}
by:按照那一列数据进行排序,但是by参数貌似不建议使用
## 对x1列升序排列,x2列升序。处理x1有相同值的情况
import pandas as pd
x = pd.DataFrame({"x1":[1,2,2,3],"x2":[4,3,2,1]})
x.sort_index(by = ["x1","x2"],ascending = [False,True]) 44、保留特定位数小数
x = 3.142222
y = 3.147777
z = 3.2
round(x, 2)
3.14
round(y, 2)
3.15
round(z, 2)
3.245、pandas 排序
df.sort_values(by=['col2','col3'],ascending=False)46、字符串转化为时间
sh_index['日期']=pd.to_datetime(sh_index['日期'], format ='%Y-%m-%d')47、删除list某个值
python中关于删除list中的某个元素,一般有三种方法:remove、pop、del48、删除包含空值的行
df=df.dropna(axis=0,subset = ['签单保费','支付金额','总保额','保单性质'])
备注:axis=0表示行,axis=1表示列49、对列表中某一类值进行修改
profession.loc[profession['职业']=='无','职业'] ='无业'
前为条件,后为选择字段
职业:列名,无:表格原内容,无业:替换无的新内容
df.replace('A',0.1,inplace=True)50、在list中确定某个值的索引
list.index('2020-01-02') #在列表中查找某个值的索引51、用numpy生成时间列表
np.arange('2020-01-01','2020-07-14',dtype=np.datetime64)52、numpy数组差分
>>> x = np.array([1, 2, 4, 7, 0])
>>> np.diff(x)
array([ 1, 2, 3, -7])
>>> np.diff(x, n=2)
array([ 1, 1, -10])
>>> x = np.array([[1, 3, 6, 10], [0, 5, 6, 8]])
>>> np.diff(x)
array([[2, 3, 4],
[5, 1, 2]])
>>> np.diff(x, axis=0)
array([[-1, 2, 0, -2]])
>>> x = np.arange('1066-10-13', '1066-10-16', dtype=np.datetime64)
>>> np.diff(x)
array([1, 1], dtype='timedelta64[D]')53、dataframe中根据某个值求该值的行索引
index = df[df['date']=='2019-12-02'].index.tolist()[0]54、字符串&时间类型相互转化
对dataframe中的整列进行操作
(1)字符串转时间
df['date']中的日期以字符串类型存储;'date'为列名
df['date'] = pd.to_datetime(df['date'], format ='%Y-%m-%d') (2)时间转字符串
df['date']中的日期以时间类型存储;'date'为列名
df['date'] = df['date'].astype(np.str)55、DataFrame修改列名
(1)部分列名修改
df.rename(columns={'原列名' : '新列名'}, inplace=True)
(2)全部列重命名
df.columns = new_columns,可以是列表或元组, 但新旧列名的长度必须一致,否者会不匹配报错。这种改变方式是直接改变了原始数据。
df.columns =['a1','b1','c1','d1'] #'a1','b1','c1','d1'为新的列名
(3)读取文件时重命名
df = pd.read_csv('xxx.csv', names=new_columns, header=0)
56、两列合并成一列
df_20['去重项']=df_20['报案号'].map(str) + df_20['申请调查项目'].map(str)57、从时间序列提取年月日
data['AnalogWriteTime']=pd.to_datetime(data['AnalogWriteTime'])
data['year']=data['AnalogWriteTime'].dt.year
data['day']=data['AnalogWriteTime'].dt.day
data['hour']=data['AnalogWriteTime'].dt.hour
data['minute']=data['AnalogWriteTime'].dt.minute58、判断数据中是否有空值
(1)pandas isnull()函数
df.isnull() #返回df中各元素是否为空的同df大小的数据框
df["A"].isnull() #判断A列中空值情况
df[["A","B"]].isnull() # 指定多列进行空值判断,对于本文实例,下述代码效果同df.isnull() (2)pandas notnull()函数
df.notnull() #判断df中各元素是否 不是 空值
df["A"].notnull() #判断A列中非空值情况
df[["A","B"]].notnull() # 指定多列进行非空值判断,对于本文实例,下述代码效果同df.notnull() (3)numpy np.isnan() 函数
np.isnan(df) # 等同于df.isnull()
np.isnan(df["A"]) # 等同于 df["A"].isnull()
np.isnan(df[["A","B"]]) # 等同于 df[["A","B"]].isnull()(4)根据空值筛选数据
# 筛选出A列为空的所有行
df[df.A.isnull()]
df[df["A"].isnull()]
# 筛选出A列非空的所有行
df[df.A.notnull()]
df[df["A"].notnull()]
# 筛选出df中存在空值的行
df[df.isnull().values==True] (5)查找空值索引
np.where(np.isnan(df)) # df中空值所在的行索引及列索引
np.where(np.isnan(df.A)) # df中A列空值所在的行索引59、jupyter查看历史操作命令
%history