Echarts(1):Python爬取微博热搜并用Echarts词云展示
Echarts(1):Python爬取微博热搜并用Echarts词云展示
1.思路与实现流程
直接从微博中找不到微博的历史热搜数据的,可以通过这个网站 https://www.weibotop.cn/ 找到微博的历史热搜数据。爬取下来后保存为csv格式的数据,在使用Python pandas库和结巴分词库进行处理,得到分词结果,再对分词结果进行词频计算,得到echarts词云的原数据。
2.Python爬取网页数据
参照了网上大佬的爬虫代码,对 https://www.weibotop.cn/的网页进行爬取。
首先找到数据存在网页那个位置,我们才好进行数据的爬取,打开这个网站,右键检查网页,打开network,刷新一遍可以发现数据在下面的。
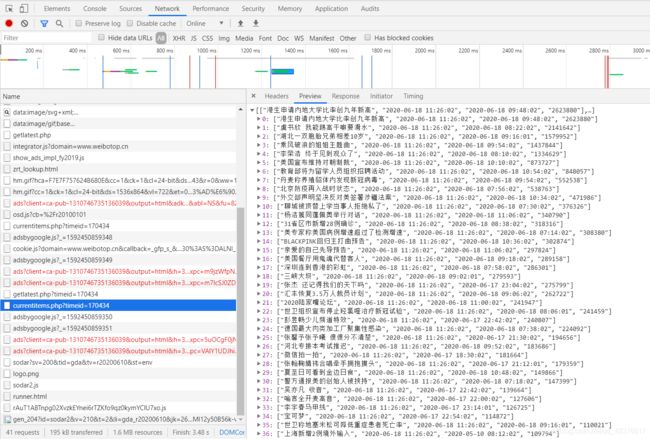
再分析网页链接,可以发现只需要动态更改时间,就可以实现历史热搜数据的爬取。timeid就是更改时间的值。

按照上面分析的,我们对网页进行爬取,动态更改timeid的值,就获取到2020-01-01到今天的所有热搜数据。最后保存到csv文件中。
import json
import requests
import csv
def requests_web_data(url):
try:
headers = {
"User-Agent": "", "Cookie": ""}
r = requests.get(url, headers=headers)
# 判断返回的Response类型状态是不是200。如果是200,他将表示返回的内容是正确的,如果不是200,他就会产生一个HttpError的异常。
r.raise_for_status()
r.encoding = r.apparent_encoding # 编码为网页的编码
except:
print('requests error!')
else:
return r.content
def get_weibo_historical_data():
latest_time_id_url = 'https://www.eecso.com/test/weibo/apis/getlatest.php'
latest_time_id = json.loads(requests_web_data(
latest_time_id_url).decode('utf-8'))[0]
# 筛选获取time_id
time_ids = []
for x in range(48438, int(latest_time_id) + 1, 180): # time_id=48438:2020-01-01
time_id_url = 'https://www.eecso.com/test/weibo/apis/getlatest.php?timeid=' + \
str(x)
time_data = json.loads(requests_web_data(time_id_url).decode('utf-8'))
if time_data is not None:
time = time_data[1].split(' ')[1].split(':')[0]
if time == '00' or time == '12':
time_ids.append(time_data[0])
if time_ids[-1] != latest_time_id:
time_ids.append(latest_time_id)
# 通过筛选的time_id获取一月份的热搜数据
weibo_hot_data = []
for time_id in time_ids:
historical_data_url = 'https://www.eecso.com/test/weibo/apis/currentitems.php?timeid=' + \
str(time_id)
data = json.loads(requests_web_data(
historical_data_url).decode('utf-8'))
weibo_hot_data.append(data)
out = open("数据001.csv", "w", encoding="UTF-8", newline="")
csv_write = csv.writer(out, dialect="excel")
for i in range(0, len(weibo_hot_data)):
csv_write.writerow(weibo_hot_data[i])
return weibo_hot_data
if __name__ == "__main__":
get_weibo_historical_data()
最后我们得到的数据格式为:这个格式数据比较乱,需要对此进行处理。

3.数据处理
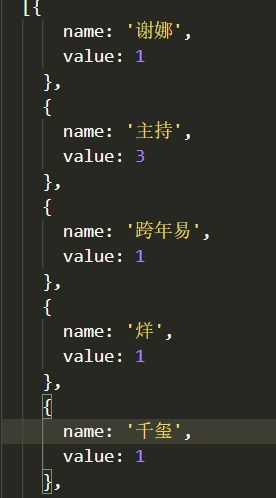
对这个格式的代码进行了几步处理,详细代码就不全部演示了,这是分词去停用词后的数据处理结果。

再根据这个结果计算词频出现的次数,得到如下所示的json对象格式数据。
4.echarts词云图
数据处理完成了,那么就开始画图,画图前要先准备好echarts.js和echarts-wordcloud.js两个库,通过script标签引入即可使用。echarts代码如下所示:
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Documenttitle>
head>
<body>
<script src="echarts.min.js">script>
<script src="echarts-wordcloud.js">script>
<script src="WB.js">script>
<div id="main" style="width: 1400px;height:700px;">div>
<script>
//开始画图
var myChart = echarts.init(document.getElementById('main'));
option = {
baseOption: {
timeline: {
axisType: 'category',
autoPlay: true,
playInterval: 5000,
data: t_data
},
tooltip: {
show: true
},
series: [{
type: "wordCloud",
gridSize: 6,
shape: 'diamond',
sizeRange: [12, 50],
width: 800,
height: 500,
textStyle: {
normal: {
color: function () {
return 'rgb(' + [
Math.round(Math.random() * 160),
Math.round(Math.random() * 160),
Math.round(Math.random() * 160)
].join(',') + ')';
}
},
emphasis: {
shadowBlur: 10,
shadowColor: '#333'
}
},
data: dataset[0]
}],
},
options: [
]
};
for (let i = 0; i < dataset.length; i++) {
option.options.push({
title: {
text: t_data[i]
},
series: [{
type: "wordCloud",
gridSize: 6,
shape: 'diamond',
sizeRange: [12, 50],
width: 800,
height: 500,
textStyle: {
normal: {
color: function () {
return 'rgb(' + [
Math.round(Math.random() * 160),
Math.round(Math.random() * 160),
Math.round(Math.random() * 160)
].join(',') + ')';
}
},
emphasis: {
shadowBlur: 10,
shadowColor: '#333'
}
},
data: dataset[i]
}],
});
}
myChart.setOption(option);
script>
body>
html>
运行这个代码就可以得到词云图了,并且词云和时间轴联系在一起,会自动实现日期的更换和词云的更新。
