深度学习 - 序列问题-电影评论实例(二分类问题)
这里是自定义目录标题
- 数据的引入和处理
- 构建模型
-
- Embedding层,将整数转化为向量
- 数据扁平化层
- Dense全连接层和Dropout层(抑制过拟合)
- 构建优化器
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
数据的引入和处理
这里是用的是Keras中的 IMDB 电影评论情感分类数据集(官方网站)
- 数据集来自 IMDB 的 25,000 条电影评论,以情绪(正面/负面)标记。评论已经过预处理,并编码为词索引(整数)的序列表示。为了方便起见,将词按数据集中出现的频率进行索引,例如整数 3 编码数据中第三个最频繁的词。这允许快速筛选操作,例如:「只考虑前 10,000 个最常用的词,但排除前 20 个最常见的词」。
data = keras.datasets.imdb
(x_train, y_train), (x_test, y_test) = data.load_data(num_words=10000)
可以看出,数据集并不是我们想象的由单词组成的评论语句,而是一个由数字组成的list,而其中每一个数字都代表一个单词(key)在字典data.get_word_index()中所对应的value
# 其中每一个数字都代表一个单词(key)在字典data.get_word_index()中所对应的value
x_train[:1]
>>>array([list([1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32])],
dtype=object)
以数据集的第1条评论为例,将其恢复为原始文本
imdb.get_word_index()方法,它返回单词索引字典,
如 {‘create’:984,‘make’:94,…}
word_index = data.get_word_index()
print('单词个数:', len(word_index))
>>>单词个数: 88584
为了方便对评论进行还原,需要将key和value变换位置,
得到形如 {34701: ‘fawn’, 52006: ‘tsukino’, 52007: ‘nunnery’, …}
index_word = {
v:k for k,v in word_index.items()}
通过index_word,可以轻松的还原第一条评论
' '.join(index_word.get(w) for w in x_train[0])
# 第1条评论的转换结果
>>>"the as you with out themselves powerful lets loves their becomes reaching had journalist of lot from anyone to have after out atmosphere never more room and it so heart shows to years of every never going and help moments or of every chest visual movie except her was several of enough more with is now current film as you of mine potentially unfortunately of you than him that with out themselves her get for was camp of you movie sometimes movie that with scary but and to story wonderful that in seeing in character to of 70s musicians with heart had shadows they of here that with her serious to have does when from why what have critics they is you that isn't one will very to as itself with other and in of seen over landed for anyone of and br show's to whether from than out themselves history he name half some br of and odd was two most of mean for 1 any an boat she he should is thought frog but of script you not while history he heart to real at barrel but when from one bit then have two of script their with her nobody most that with wasn't to with armed acting watch an for with heartfelt film want an"
通过观察x_train.shape和y_train.shape可以看出每条评论长度不同
print('属性集:{}\n标签集:{}'.format(x_train.shape, y_train.shape))
# 这里发现属性集的第2个维度的值是空的,它表示每一条评论由多少单次构成,有可能因为每条评论长度不同所以导致没有数值
>>>属性集:(25000,)
标签集:(25000,)
word_num = [len(i) for i in x_train]
print(word_num[:5])
print('最长评论单词个数:', max(word_num))
# 可以看出来每一条评论的长度是不同的
>>>[218, 189, 141, 550, 147]
最长评论单词个数: 2494
则我们可以使用keras.preprocessing.sequence.pad_sequences()方法统一每一条评论的长度(官方网站)
则使用该方法,将训练集和测试集中所有的评论数据均统一为长度为500的数据
x_train = keras.preprocessing.sequence.pad_sequences(x_train, 500)
x_test = keras.preprocessing.sequence.pad_sequences(x_test, 500)
可以和上边对比发现,此时的x_train.shape和y_train.shape的第二个维度,不再是None,而是500.
x_train.shape
# 通过上述操作,可以看出第2维度为500(表示每条评论均只有500个单词)
>>>(25000, 500)
至此,所有数据处理✅
构建模型
逐层添加构架模型
model = keras.models.Sequential(name='model_for_IMDB')
Embedding层,将整数转化为向量
Embedding层(详解)-- ⚠️ Embedding层只能作为模型的第一层
Embedding层的作用:
将正整数转换为具有固定大小的向量,如 [ [4], [20] ] ==> [ [0.25, 0.1], [0.6, -0.2] ]
具体操作:对每条评论中的500个单词(int),将每个单词转化为长度为50的向量
model.add(layers.Embedding(input_dim=len(word_index), output_dim=50,
input_length=x_train.shape[1]))
通过model.output_shape记录,数据经过这一层后的输出维度
Embedding_outshape = model.output_shape
print('原始数据维度:', x_train.shape)
print('Embedding层输出维度:', Embedding_outshape)
>>>原始数据维度: (25000, 500)
Embedding层输出维度: (None, 500, 50)
数据扁平化层
可以使用layers.Flatten()进行数据扁平化,从而和全连接层进行对接
建议看一下:官方网站
model.add(layers.Flatten())
Flatten_outshape = model.output_shape
print('Embedding层输出维度:', Embedding_outshape)
print('Flatten层输出维度:', Flatten_outshape)
# 进行扁平化后,就可以使用全连接层了
>>>Embedding层输出维度: (None, 500, 50)
Flatten层输出维度: (None, 25000)
也可以使用GlobalAveragePooling1D层代替Flatten层
而相比Flatten层,可以缩小参数个数,提高正确率,所以更推荐使用GlobalAveragePooling1D层
(建议看看)说明:链接
model.add(layers.GlobalAveragePooling1D())
Dense全连接层和Dropout层(抑制过拟合)
激活函数的选择activation:几种激活函数的比较
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))
最终的输出结果为(None, 1)
model.output_shape
>>> (None, 1)
构建优化器
优化器的选择optimizer:【深度学习】常用优化器总结
损失函数的选择loss:深度学习 -优化器中的损失函数总结
# 二分类损失函数使用 binary_crossentropy
model.compile(optimizer=keras.optimizers.Adam(learning_rate=0.001),
loss='binary_crossentropy',
metrics=['acc'])
它将通过将数据切片为大小为“batch_size”的片段来训练模型,并在给定数量的“epoch”中重复遍历整个数据集。(参考:谈谈深度学习中的 Batch_Size)
history = model.fit(x_train, y_train, epochs=15, batch_size=256,
validation_data=(x_test, y_test))
>>>Train on 25000 samples, validate on 25000 samples
Epoch 1/15
25000/25000 [==============================] - 9s 361us/sample - loss: 0.6574 - acc: 0.6060 - val_loss: 0.4703 - val_acc: 0.8127
Epoch 2/15
25000/25000 [==============================] - 8s 328us/sample - loss: 0.2666 - acc: 0.8934 - val_loss: 0.2801 - val_acc: 0.8830
...
plt.plot(history.epoch, history.history.get('acc'), label='acc')
plt.plot(history.epoch, history.history.get('val_acc'), label='val_acc')
plt.legend()
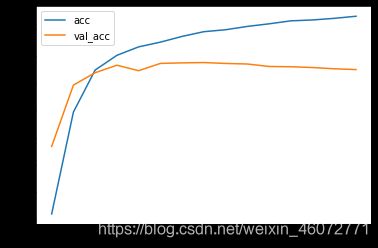
模型构建与训练✅
可以使用model.predict()方法进行预测,但注意传入的预测数据要与训练数据维度相同,哪怕只是对一条数据进行预测,我们也需要先将他转化为只有一条数据的数据集。