爬取美女壁纸
疲惫的生活我们需要些许的温柔
我会带大家进行美女壁纸的爬取,来给生活增添色彩,生活需要有理想和爱人或者说是相互扶持的人,生活才有温度。因为爱生活才会有希望。
壁纸案例
- 疲惫的生活我们需要些许的温柔
- 前言
- 一、requests是什么?
- 二、使用步骤
-
- 1.引入库
- 2.请求数据
- 3.解析数据
- 4.保存数据
- 5.本地展示
- 6.全部代码实现
- 总结
前言
例如:随着大数据的不断发展,爬虫技术也越来越重要,很多人都开启了学习爬虫,本文就介绍了爬虫的使用。以下是本篇文章正文内容
一、requests是什么?
Requests 是一个 Python 的 HTTP 客户端库,我们可以用它得到HTML源码
二、使用步骤
1.引入库
代码如下:
本次我们采用的分别是requests请求库,os文件操作库,lxml解析库,和re正则库
import requests
import os
from lxml import etree
import re
2.请求数据
代码如下:
# 获取网页源码
def get_url(url):
# 进行头部伪装
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36",
}
res=requests.get(url,headers=headers)
res.encoding=res.apparent_encoding
html=res.text
# 返回HTML页面
return html
该处使用的url网络请求的数据。
3.解析数据
代码如下:
def parse_html(html):
# 采用正则进行匹配我们所需要的文本
ul=re.findall(r'(.*?)
',html,re.S)[0]
e=etree.HTML(ul)
src=e.xpath("//li//a/img/@src")
title=e.xpath("//li//a/b/text()")
for i,z in zip(src,title):
json={
"src":i,
"title":z
}
# 字典类型的传参
save(json['src'],json['title'])
该处是进行数据的解析与处理。
4.保存数据
代码如下:
def save(src,name):
src="http://pic.netbian.com/"+src
print("正在保存"+name)
resonse =requests.get(src)
# 创建路径进行文件的保存
path = 'E:\\lianxi\\test'
if not os.path.isdir(path):
os.makedirs(path) # 判断没有此路径则创建
# 二进制保存图片
with open('E:\\lianxi\\test\\'+name+'.jpg', 'wb') as f:
f.write(resonse.content)
该处是进行文件的保存。
5.本地展示
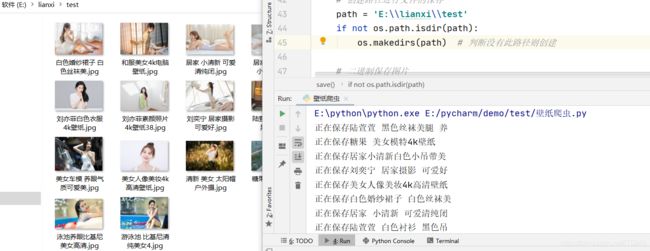
该处是进行展示。
6.全部代码实现
#!/usr/bin/python3
# --coding:utf-8--
# @Author:陈同学
import requests
import os
from lxml import etree
import re
# 获取网页源码
def get_url(url):
# 进行头部伪装
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36",
}
res=requests.get(url,headers=headers)
res.encoding=res.apparent_encoding
html=res.text
# 返回HTML页面
return html
# 解析网页
def parse_html(html):
# 采用正则进行匹配我们所需要的文本
ul=re.findall(r'(.*?)
',html,re.S)[0]
e=etree.HTML(ul)
src=e.xpath("//li//a/img/@src")
title=e.xpath("//li//a/b/text()")
for i,z in zip(src,title):
json={
"src":i,
"title":z
}
# 字典类型的传参
save(json['src'],json['title'])
# 保存函数
def save(src,name):
src="http://pic.netbian.com/"+src
print("正在保存"+name)
resonse =requests.get(src)
# 创建路径进行文件的保存
path = 'E:\\lianxi\\test'
if not os.path.isdir(path):
os.makedirs(path) # 判断没有此路径则创建
# 二进制保存图片
with open('E:\\lianxi\\test\\'+name+'.jpg', 'wb') as f:
f.write(resonse.content)
if __name__ == '__main__':
html=get_url('http://pic.netbian.com/4kmeinv/index.html')
parse_html(html)