爬取小鸟高清美女壁纸
有装了360安全软件的小伙伴对小鸟壁纸相信都会比较熟悉,里面拥有非常丰富的壁纸,包括动态壁纸和视频壁纸。今天我们就来利用python来爬取一下其中的高清美女壁纸吧。
百度搜索小鸟壁纸,进入官网后我们发现,这里只有一个下载客户端的按钮,那么很显然不能通过网页来抓取,这时很自然想到我们的抓包工具,这里使用Fliddler抓包工具进行分析。
首先在电脑上面打开小鸟壁纸,点击其中的静态壁纸然后点击下方的美女栏目,同时打开Fliddler抓包工具,
当图片加载出来之后,这是注意观察Fliddler中的信息,这时会看到加载出了很多的图片,
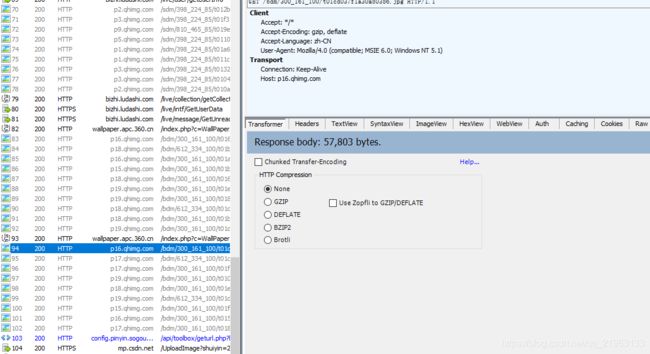
点击左边的图片地址,会看到在右边成功的显示了图片

这时我们需要注意,在图片加载时请求的这个json的地址信息
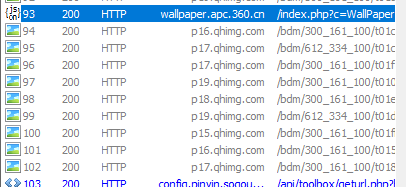
点击这个json请求,通过它的头信息,我们可以很明确的知道它的请求地址为
http://wallpaper.apc.360.cn/index.php?c=WallPaper&a=getAppsByCategory&cid=6&start=0&count=10
GET http://wallpaper.apc.360.cn/index.php?c=WallPaper&a=getAppsByCategory&cid=6&start=0&count=10 HTTP/1.1
Accept: */*
Accept-Language: zh-CN
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)
Host: wallpaper.apc.360.cn
Connection: Keep-Alive
在浏览器中打开这个地址我们就会发现,它返回的json文件中,包含了我们所需要的图片地址
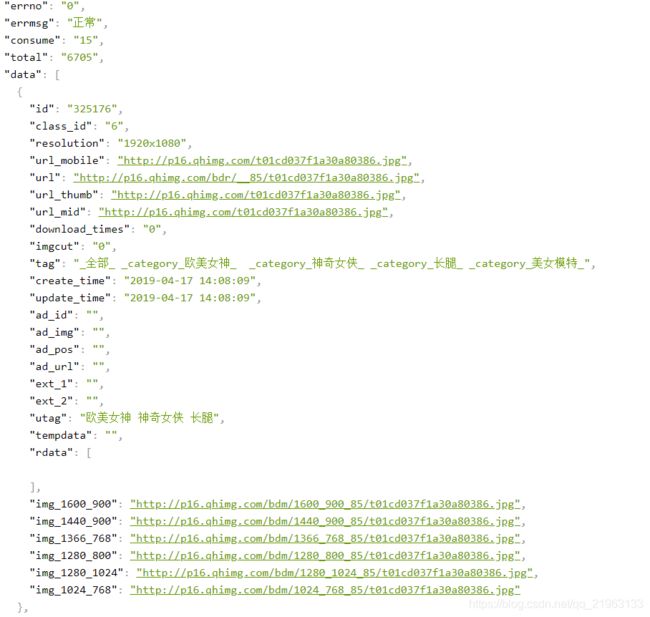
通过观察我们发现,这里它的图片地址会有很多种,下面的地址很容易理解,应该是为了适应相应的分辨率而返回的图片地址,上面的地址我们可以依次打开来看看,
通过对比可以发现,url的大小比url_mobile要小很多,它应该是原图的一个简化版,下面两个跟url_mobile的地址一样,这里我们先不管,原图的地址就是url_mobile的地址,最下面是为了适应各种分辨率而匹配出来的地址。
通过对url的分析,其中的start应该是每页的开始的条目,而count就是每页显示的总条目。这时我们只需要找到总共的条目数那么就可以将图片全部下载下来了,通过对url返回信息的查看我们知道,这里的total:6705就是总条数,我们可以来验证一下是否真的是这个,在壁纸中我们将下拉条拉至最底端,观察Fliddler的最后的地址。
这时我们打开最后的这个json可以看到他的url地址为:
http://wallpaper.apc.360.cn/index.php?c=WallPaper&a=getAppsByCategory&cid=6&start=6700&count=10
显示最后一页开始为6700,而且只有5张壁纸,进而验证了我们的猜想。为了防止大家在下载的时候会漏掉一些图片,这里将下载时可能会遇到的坑先说明一下,不是每个url中都会有url_mobile这个地址,当url_mobile为空字符串时,我们需要将下载的地址换成url

下面就是代码的编写。
from urllib import request
import math
import re
base_url = 'http://wallpaper.apc.360.cn/index.php?c=WallPaper&a=getAppsByCategory&cid=6&count=10&start='
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36'
}
#保存到本地的路径地址
base_filepath = 'E:/wallpaper/'
total = 6705
count = 10
totalPage = math.ceil(total / count)
for i in range(0, totalPage):
try:
print("======开始下载第"+str(i+1)+"页的图片======")
url = base_url + str(i * 10)
req = request.Request(url, headers=header)
resp = request.urlopen(req).read().decode('utf-8')
pat = 'url_mobile":"(.*?)",'
pat1 = '"url":"(.*?)",'
pat2 = 'utag":"(.*?)",'
url_mobile_list = re.compile(pat).findall(resp)
url__list = re.compile(pat1).findall(resp)
#utag_list = re.compile(pat2).findall(resp)
for j in range(0, len(url_mobile_list)):
download_url = url_mobile_list[j]
#当url_mobile_list的地址为""时,采用url的地址
if (download_url == ""):
download_url = url__list[j]
#将\/转换成/
reurl = download_url.replace('\/', '/')
#将Unicode中文编码转换成中文汉字,并利用这个ustag作为文件的名字
#utag = utag_list[j].encode('utf-8').decode('unicode_escape')
#request.urlretrieve(reurl, base_filepath + utag + '.jpg')
# 使用数字作为图片名字
request.urlretrieve(reurl, base_filepath + str(i+1) + str(j) + '.jpg')
print("======第" + str(i + 1) + "页的图片下载完成======")
except Exception as err:
print(err)