Python开发之list中的多重嵌套合并去重
Python开发之list中的多重嵌套合并去重
- (一)list的一般去重问题
-
- 1.set去重
- 2.fromskey去重
- 3.遍历去重
- (二)list中的字典去重
- (三)list中的多重嵌套合并去重问题
前言:做数据处理这一块,少不了得数据去重这一块,今天趁此机会,总结一下list常用的去重,第三个是重点全网独此一分,还希望大家多给给关注!
(一)list的一般去重问题
1.set去重
代码:
if __name__ == '__main__':
list1 = [11, 22, 11, 22, 33, 44, 55, 55, 66]
new_list1 = list(set(list1))
print(list1)
print(new_list1)
输出:

2.fromskey去重
代码:
if __name__ == '__main__':
name_list = ["fly1","fly2","fly3","fly1","fly2","fly3","fly1","fly2","fly3"]
new_name_list = list({
}.fromkeys(name_list).keys())
print(name_list)
print(new_name_list)
输出:

3.遍历去重
代码:
if __name__ == '__main__':
list1 = ["fly1","fly2","fly3","fly1","fly2","fly3","fly1","fly2","fly3"]
list2 = []
for i in list1:
if i not in list2:
list2.append(i)
print(list1)
print(list2)
输出:

(二)list中的字典去重
实现原理:借助functools里面的reduce函数,然后利用lambda函数实现list中的字典去重。
代码:
from functools import reduce
if __name__ == '__main__':
data_list = [{
"a": "123", "b": "321"}, {
"a": "123", "b": "321"}, {
"b": "321", "a": "123"}]
new_data_list = reduce(lambda x, y: x if y in x else x + [y], [[], ] + data_list)
print(data_list)
print(new_data_list)
(三)list中的多重嵌套合并去重问题

请看上图,我们需要处理的结果是把两个list合并成一个list,并且里面的字典重复的只需要保留一个,name一样的需要进一步判断info集合里面的数据是不是一样,一样的话才是重复数据,不一样的话,追加到info集合中去。
list1的数据集合是:
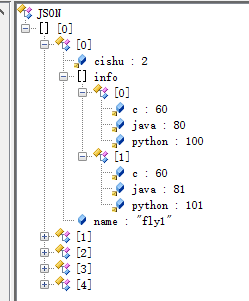
list2的数据集合是:
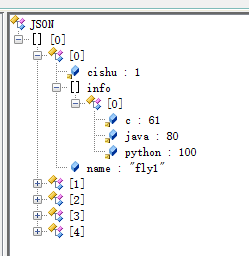
两个集合合并去重之后的是:

代码:
import json
def get_data1_list():
data_list = [{
"name": "fly1", "cishu": 2, "info": [{
"java": 80, "python": 100, "c": 60},{
"java": 81, "python": 101, "c": 60}]},
{
"name": "fly2", "cishu": 1, "info": [{
"java": 81, "python": 101, "c": 61}]},
{
"name": "fly3", "cishu": 1, "info": [{
"java": 82, "python": 102, "c": 62}]},
{
"name": "fly4", "cishu": 1, "info": [{
"java": 80, "python": 103, "c": 63}]},
{
"name": "fly5", "cishu": 1, "info": [{
"java": 83, "python": 104, "c": 64}]}]
return data_list
def get_data2_list():
data_list = [{
"name": "fly1", "cishu": 1, "info": [{
"java": 80, "python": 100, "c": 61}]},
{
"name": "fly2", "cishu": 1, "info": [{
"java": 81, "python": 101, "c": 61}]},
{
"name": "fly3", "cishu": 1, "info": [{
"java": 82, "python": 102, "c": 62}]},
{
"name": "fly7", "cishu": 1, "info": [{
"java": 87, "python": 103, "c": 67}]},
{
"name": "fly8", "cishu": 1, "info": [{
"java": 88, "python": 104, "c": 68}]}]
return data_list
if __name__ == '__main__':
data_list = get_data1_list()+get_data2_list()
name_list = []
for data in data_list:
name = data["name"]
name_list.append(name)
print("合并之前的长度",len(name_list))
new_name_list = list({
}.fromkeys(name_list).keys())
print("合并之后的长度",len(new_name_list))
ll = []
for new_company in new_name_list:
new_list = []
for data in data_list:
if data["name"] == new_company:
d = [False for c in data["info"] if c not in new_list]
if d:
new_list += data["info"]
print('{} not in new_list'.format(data["info"]))
else:
print('{} in new_list'.format(data["info"]))
dict = {
"name":new_company,"cishu":len(new_list),"info":new_list}
new_list = []
ll.append(dict)
print(json.dumps(ll,ensure_ascii=False,indent=2))
深夜写博客,不容易还望大家给个关注!!!