首期 Go 开源说实录:Excelize 开源背后的故事
首期主题:Excelize
在 Go 中国社区的首期 Go 开源说线上活动中,开源项目 Excelize 的作者续日带来了《Excelize 开源背后的故事》主题分享。
作者介绍
续日,软件工程师,专注于 Go 语言实践、中间件研发与大规模数据处理。目前就职于阿里巴巴,曾就职于百度、奇虎 360 等公司,前百度 Go 语言编程委员会成员,在百度期间从事内部 Go 语言开发框架和代码规范的相关工作。他热爱开源,会把一些开源项目发布在他的 GitHub 上:https://github.com/xuri
内容提要
本次分享内容主要包括四个部分:Excelize 项目初衷与发展历程、实现过程、设计理念与实践应用。

关于 Excelize
Excelize 是 Go 语言编写的用于操作 Office Excel 文档基础库,基于 ECMA-376,ISO/IEC 29500 国际标准。可以使用它来读取、写入由 Microsoft Excel™ 2007 及以上版本创建的电子表格文档。支持 XLSX / XLSM / XLTM 等多种文档格式,高度兼容带有样式、图片(表)、透视表、切片器等复杂组件的文档,并提供流式读写 API,用于处理包含大规模数据的工作簿。可应用于各类报表平台、云计算、边缘计算等系统。
入选 2020 Gopher China - Go 领域明星开源项目 (GSP)、2018 年开源中国码云最有价值开源项目 (Gitee Most Valuable Project)。
GitHub:https://github.com/xuri/excelize
项目初衷
提起电子表格大家都比较熟悉,以 Excel 为代表的经典电子表格已经应用在各行各业当中,根据相关研究机构的估算数据,办公文档产生的数量每年至少以数十亿的规模增长。电子表格文档作为一种数据承载的重要载体,在很多领域都有应用。作为开发者,一些情况下需要用编程的方式操作这些电子表格文档,起初为了满足从报表系统中导出数据的需要,Excelize 的作者续日调研了市面上多个主流语言的相关基础库,希望能够找到一个高性能、支持复杂样式并且还能够跨平台的解决方案,可是经过一番寻找并没有找到能够满足业务复杂需要的开源实现,就这样他决定从文档格式标准开始入手,从零开始使用 Go 语言实现一个兼顾性能和兼容性的电子表格文档基础库。总结发起 Excelize 项目的初衷可以归结为以下 6 点:
电子表格办公文档有着广泛的应用
自动化电子表格文档处理系统与云计算、边缘计算场景融合
开发者需要通过编程方式处理 Excel 文档
对复杂或包含大规模数据的 Excel 文档进行操作的需求
文档格式领域难以完全实现的复杂技术标准
开源领域、Go 语言缺少具备良好兼容性的基础库
发展历程
在 Excelize 开源之前就在公司内部和多个线上产品中有了应用实践,2016 年 9 月正式开源时已经能够满足很多常用的 Excel 文档操作需求,除了基本的工作簿、工作表和单元格操作,还具备插入图片、图表和合并单元格等能力。历经四年多的发展,截至目前已经发布了 14 个版本。我们来回顾一下 Excelize 的发展历程,下面例举了每个版本中有代表性的部分功能(Excelize 在 GitHub 的 Release 页面和文档网站上有更为详细的发布记录):
v1.0.0 (2016-09-19) 首次发布:支持插入图片、图表、合并单元格等
v1.1.0 (2017-08-19) 支持条件格式、复制工作表
v1.2.0 (2017-12-01) 兼容 Go 1.9,支持堆积图表
v1.3.0 (2018-05-11) 行列分组、单元格批量赋值
v1.4.0 (2018-08-14) 支持数据验证、色值转换
v1.4.1 (2019-01-01) 搜索单元格、保护工作表
v2.0.0 (2019-05-02) 引入流式读写,性能进一步提升
v2.0.1 (2019-07-01) 页眉页脚、文档属性设置
v2.0.2 (2019-10-09) 嵌入 VBA 工程、数据透视表
v2.1.0 (2020-02-10) 支持非 UTF-8 编码文档
v2.2.0 (2020-05-11) 支持图表工作表、富文本、分页
v2.3.0 (2020-08-06) 新增工作表视图属性设置
v2.3.1 (2020-09-23) 兼容 Go 1.15,支持读加密 Excel
v2.3.2 (2021-01-04) 图表、数据透视表功能增强,更好的兼容性与更快的流式读写
实现过程
调研市面上主流的技术实现
在设计 Excelize 之初,续日调研了主流编程语言的开源和商业解决方案、对开源领域相关基础库的设计和源代码做了分析,并阅读了电子表格文档格式国际标准。使用过 Office 软件的朋友可能知道,同一份文档在不同的办公软件中打开可能会出现还原不一致的问题,比如存在样式细节的差异;开发者使用编程的方式借助第三方基础库操作电子表格文档,尤其是处理包含复杂样式的文档时可能会出现保存后的文档无法被 Office 正确打开,提示“文档已损坏”或部分数据丢失等问题,导致这些问题的原因通常是由于这些办公应用或基础库对文档格式标准的实现不一致、不完整或者存在某些缺陷导致的,如果要避免这个问题就需要深入理解复杂的文档格式标准,这也是实现电子表格基础库的难点和挑战之一。
理解相关技术标准 ECMA-376,ISO/IEC 29500,MS-OFFCRYPTO
ECMA-376,ISO/IEC 29500 是 Office 办公文档的国际标准(以下简称技术标准),对应了我们熟知的 Word、Excel、PowerPoint 三大办公应用产生的文档,它是一套十分庞大、复杂的技术标准,其官方文档有超过 7000 页内容,而 Excel 文档相关的部分也有 2000 余页之多。除此之外 Excel 中的部分功能还涉及厂商技术标准,例如对加密文档的支持需要实现 MS-OFFCRYPTO 技术标准,这里就不详细展开了,接下来主要会介绍一下 ECMA-376,ISO/IEC 29500 标准的主要内容。
使用 Go 语言编写代码实现功能
在了解完相关技术标准后,就开始使用 Go 语言来实现该技术标准了。续日在 2019 年 12 月的 Gopher Meetup 上曾做过一次题为《Go 语言国际电子表格文档格式标准实践》的技术分享,详细介绍了该国际标准的特点以及使用 Go 语言实现该标准相关的实践,有兴趣的朋友可以看一下 GoCN 社区中相关的文章。
数据结构代码生成器的设计
操作电子表格文档离不开对其内部数据结构的处理,由于电子表格文档内部涉及到的数据结构非常多,手工方式编写代码耗时耗力且容易出错,那么能否通过标准文档中给定的数据结构描述自动化生成 Go 语言的结构体代码呢,由此续日设计了一个数据结构代码生成器。
公式词法 / 语法分析、计算框架
公式计算也是电子表格的主要功能之一,若在不依赖电子表格应用的前提下对表格文档中的公式进行求值运算,就需要实现一套计算引擎,其中涉及到 Excel 公式的词法分析和解析等。
技术标准
ECMA-376, ISO/IEC 29500 做为国际文档格式标准是一种基于 XML 和 ZIP 技术的文档格式,大家常见的 DOCX / XLSX / PPTX 等文档文件就遵循该规范。
文档格式标准解读
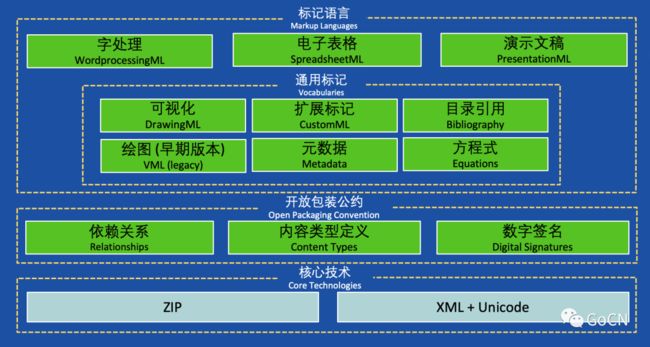
下面介绍一下标准的主要内容,上层是标记语言部分(Markup Language),它由四类标记语言组成:Word 文档对应的标记语言叫 WordprocessingML,电子表格则是 SpreadsheetML,演示文稿对应的是 PresentationML。Excelize 主要实现的是 SpreadsheetML 这个部分,除此之外 Office 文档支持进行跨应用的嵌套,例如:Word 可以嵌套 Excel,Excel 可以嵌套 Word。通用标记是跨应用的文本标记语言:囊括可视化图表、可扩展标记、源数据和目录引用等。中间层叫做开放包装公约(Open Packaging Convention),简称 OPC,定义了文档内部组件之间的关联依赖关系(Relationships)、文内容类型(Content Types)定义和数字签名(Digital Signatures)。底层是机基于 ZIP、XML 和 Unicode 的核心技术。我们可以创建一个 Excel 文档,将其扩展名修改为 zip 再进行解压即可得到一个文件夹,其中包含若干子文件夹和 XML 文档,这种设计有很强的扩展性,相比于二进制类型文档格式也具备更好的兼容性。
电子表格文档格式典型关系
电子表格文档内部的 XML 文件的布局和依赖关系是怎样的呢?这边有一个图来解释:
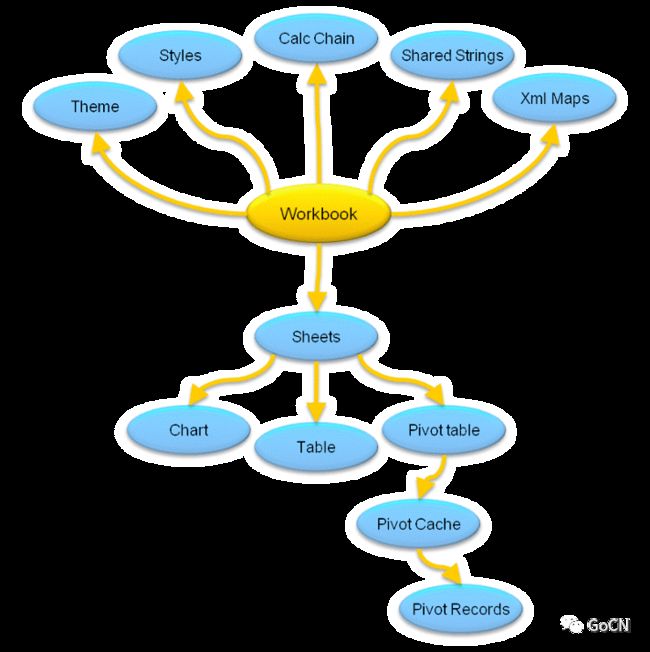
工作簿(Workbook)包含多个工作表(Sheets),工作表包含图表(Chart)、表格(Table)和数据透视表(Pivot table)等,数据透视表又包含数据透视缓存(Pivot Cache)和数据透视记录(Pivot Records)。另外,工作簿还与主题(Theme)、样式(Style)、公式计算链(Calc Chain)以及共享字符表(Shared Strings)等部分有关联关系。要实现该技术标准,需要先对这些关系进行梳理。
数据结构代码生成器
这里引入一个技术名词 —— XSD(XML Schema Definition)它是 W3C(万维网联盟)推出的一个技术规范,用于定义 XML 的模式。XML 文件中理论上可以有无限的标签和属性,XSD 是用于描述 XML 的模式语言。文档格式技术标准中,有以 XSD 来描述的数据结构定义。下图是根据技术标准中 XSD 模式语言对电子表格文档数据结构描述绘制的一个树状结构片段:
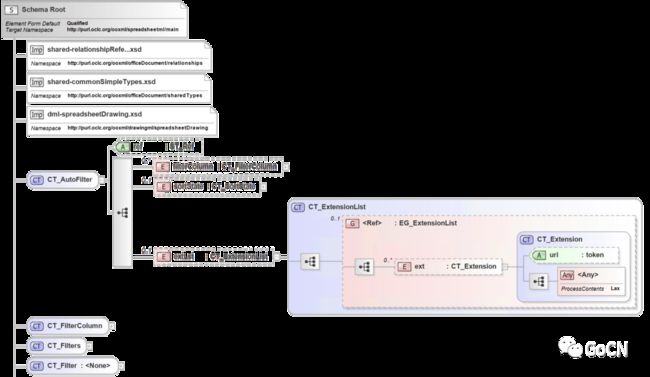
可以看到其中对 XML 标签的根结点、命名空间和 Excel 中自动过滤器(AutoFilter)相关数据结构的定义,以及 XML 中相关节点的嵌套关系、标签属性名称和数据类型的定义。描述 XML 的 XSD 之间也可以互相引用,对 Excel 文档所涉及的主要数据结构定义 XSD 文件进行分析和梳理,绘制出如下依赖关系图:
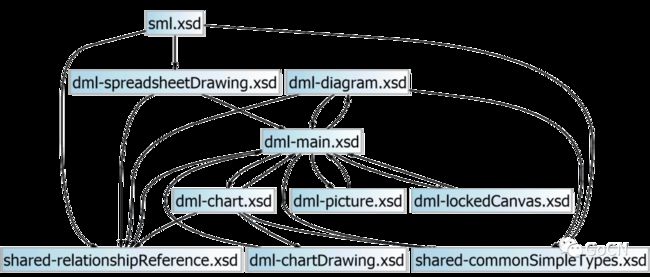
sml.xsd 是 Excel 文档的数据结构定义所使用的主文件,sml.xsd 中对通用标记语言相关的数据结构做了引用,其中包括依赖关系处理和简单数据类型的相关的结构定义。中间比较多的以 dml- 开头的 XSD 文件是与跨应用可视化相关的数据结构定义文件,例如图片、图表、图形和 SmartArt 等相关的数据结构都是在以 dml- 开头的 XSD 文件中定义。大家看到 dml- 开头的 XSD 文件比较多,因为它是跨应用的,里面所涉及的 XML 标签和属性约为 8000 个,而 sml.xsd 中定义的标签和属性也有 2589 个之多。实现 Excelize 过程中需要对大量的 XML 进行处理,需要定义对应的数据结构( struct 结构体),称之为数据模型,由于数据模型的数量繁多且嵌套关系做错综复杂,为了自动化结构体代码生成就衍生出了一个数据结构代码生成器 xgen (XSD generator):
xgen -i /path/to/your/xsd -o /path/to/your/output -l Go
-i 参数指定了输入源(input),可以传入 XSD 目录,-o 参数指定了代码生成的输出路径(output),-l 参数用于指定生成代码的编程语言(language),该工具也开源到了 GitHub 上:https://github.com/xuri/xgen。这样我们就获得了操作数据模型所需要的结构体定义代码了。
架构设计
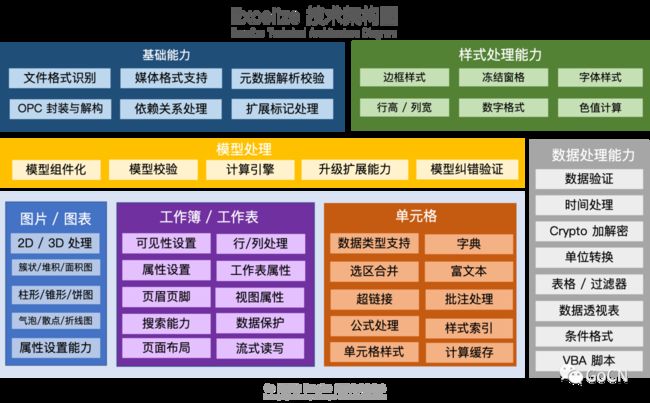
Excelize 技术能力划分为基础能力、样式处理能力、数据处理能力、图片/图表、工作簿/工作表、单元格和模型处理,7 大部分:
基础能力 - 文件格式识别、媒体格式支持、元数据解析校验、OPC 封装与解构、依赖关系处理、扩展标记处理;
样式处理能力 - 边框样式、冻结窗格、字体样式、行高 / 列宽、数字格式、色值计算;
模型处理 - 模型组件化、模型校验、计算引擎、升级扩展能力、模型纠错验证;
图片 / 图表 - 2D / 3D 处理、簇状 / 堆积 / 面积图、柱形 / 锥形 / 棱锥 / 饼图、气泡 / 散点 / 折线图、属性设置能力;
工作簿 / 工作表 - 可见性设置、行 / 列处理、属性设置、工作表属性、页眉页脚、视图属性、搜索能力、数据保护、页面布局和流式读写;
单元格 - 数据类型支持、字典、选区合并、富文本、超链接、批注处理、公式处理、样式索引、单元格样式和计算缓存处理;
数据处理能力 - 数据验证、时间处理、Crypto 加解密、单位转换、表格 / 过滤器、数据透视表、条件格式、VBA 脚本
公式词法分析和解析器
使用 Excelize 提供的 SetCellFormula API 可以方便地为单元格设置公式,设置的公式也可以在不依赖电子表格应用程序的前提下进行读取和求值运算,下面我们通过一个例子来说明 Excelize 内部是如何实现公式求值的。对于这样一个公式(为了便于理解,下面的公式仅包含操作数、操作符和函数,其中的造作数在实际场景中可以替换为单元格的地址,通过引用取值进行运算):
=1+SUM(SUM(1,2*3),4)
Excelize 中对公式的词法、语法分析均使用 Go 语言编写。首先通过基于有限状态机和堆栈令牌生成器的 efp(Excel Formula Parser)对公式文本字符进行词法分析:
import "github.com/xuri/efp"
// ...
ps := efp.ExcelParser()
ps.Parse("=1+SUM(SUM(1,2*3),4)")
println(ps.PrettyPrint())
得到如下 Token:
1
+ 至此就完成了对公式的词法分析。
公式引擎
在了解完对公式的词法分析后,我们来看一下 Excelize 中的公式引擎设计。对该中缀表达式进行求值计算,其中用到了 5 个栈(OPD:操作数、OPT:操作符、OPF:函数、OPFD:函数操作数、OPFT:函数操作符)和 1 个链表(ARGS:函数参数)来实现,运算过程状态如下图所示:
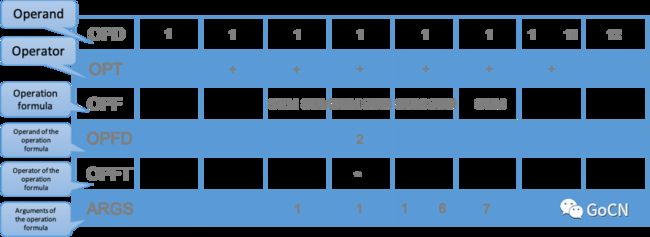
通过上述过程即可实现对公式的求值运算,具体代码可参考 Excelize 源代码 calc.go 文件中的 evalInfoxExp 函数。公式函数的动态调用入口如下:
// call formula function to evaluate
result, err := callFuncByName(&formulaFuncs{},
strings.NewReplacer(
"_xlfn", "", ".", "").Replace(
opfStack.Peek().(efp.Token).TValue),
[]reflect.Value{
reflect.ValueOf(argsList),
})
当执行公式函数调用时,将 OPF(函数栈)栈顶元素类型推断为 Token,元素的值即为函数名,先对函数名称做预处理,然后进行函数调用,其中 callFuncByName 的实现如下面的代码所示,它会根据给定的函数 Receiver、函数名称(name)和函数参数(params)进行函数调用:
// callFuncByName calls the no error or only
// error return function with reflect by given
// receiver, name and parameters.
func callFuncByName(
receiver interface{},
name string, params []reflect.Value) (
result string, err error) {
function := reflect.ValueOf(
receiver).MethodByName(name)
if function.IsValid() {
rt := function.Call(params)
if len(rt) == 0 {
return
}
if !rt[1].IsNil() {
err = rt[1].Interface().(error)
return
}
result = rt[0].Interface().(string)
return
}
err = fmt.Errorf("not support %s function",
name)
return
}
这样仅需实现一些列函数签名与 callFuncByName 形参数据类型相一致的公式函数即可,例如实现求和公式 SUM:
func (fn *formulaFuncs) SUM(argsList *list.List) (result string, err error)
余弦三角函数 COS:
func (fn *formulaFuncs) COS(argsList *list.List) (result string, err error)
中位数函数 MEDIAN:
func (fn *formulaFuncs) MEDIAN(argsList *list.List) (result string, err error)
这样避免了定义公式函数名与函数的映射关系,并具备高度的可扩展性,开发者可以根据此模式继续实现其他公式函数或创建自定义公式函数。
设计理念
使用 Go 语言编写,得益于其跨平台、高性能的优势
选择使用 Go 语言编写,支持并发设置单元格的值,在借助语言性能优势的同时也容易很方便地运行在各种平台上:Linux、macOS、Windows 和嵌入式系统中。
兼容性第一原则,以高保真无损编辑为目标
Excelize 在从创建之初就以保障文档兼容性为第一原则,这要求理解文档内部大量的数据结构,并需要在运行时提供兼容性检查、模型校验和纠错的能力。
简洁明了的 API 设计,遵循最小可用原则,兼顾其他语言开发者
API 的设计力求见名知意,并尽可能做到简洁、一种功能的实现仅可以通过一种方式来实现,避免为开发者在使用过程中埋坑。对新人友好,API 的设计也考虑到其他语言的开发者使用习惯、降低学习成本。
图文并貌的多国语言参考文档 https://xuri.me/excelize
在 2016 年 Excelize 首次发布时 Go 语言的官方文档 godoc 尚未支持插入图片,而电子表格功能复杂多样,很多场景下配合图片说明更利于开发者理解,目前 Excelize 官方文档已经支持 9 种语言。
代码开源,丰富 Go 语言生态
Excelize 在满足业务需要的同时进行了开源,希望通过开源为 Go 语言生态的发展献一份力,帮助到更多的朋友。没有想到项目一开源就得到了许多来自社区的反馈,解决了众多有同样需求开发者的痛点,Excelize 也被应用到了许多不同的应用场景之中。
时刻与开源社区保持积极互动
通过开源收到了许多来自社区的开发者的建议和反馈,在这里要感谢朋友们的支持!与开源社区保持积极互动,使得项目愈加完善,吸引更多的开发者参与进来,通过 Pull Request、Issue、捐赠等各种方式支持开源产品、推动开源项目发展
实践应用
下面通过 4 个典型的使用场景来介绍对 Excelize 的实践应用。
动态度表
通过下面这段代码,打开了一个名为 Book1 的工作簿,并通过 AddChart API 在指定的单元格区域上创建图表,Excelize 目前支持创建 52 种图表,每种图表的枚举值可以在文档网站上查询,图表格式有很多可配置的参数,例如对图例项、折线图的线条宽度和线端类型、气泡图的气泡大小、坐标轴的刻度步长等都可配置。
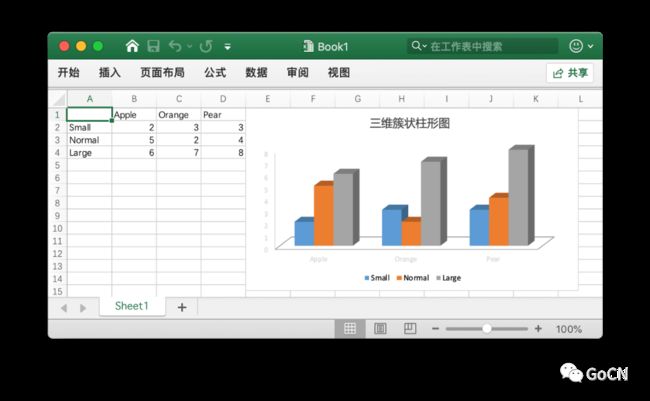
灵活运用这个例子,开发者还可以将创建好的带有个性化设计图表的电子表格文档作为模版,使用 Excelize 打开后通过 API 修改图表引用的数据区域单元格的值,另存为新的文件,这样就实现了自定义基于模版生成电子表格文档。
f, err := excelize.OpenFile("Book1.xlsx")
if err != nil {
fmt.Println(err)
return
}
f.AddChart("Sheet1", "E1", `{
"type": "col3DClustered",
"series": [
{
"name": "Sheet1!$A$2",
"categories": "Sheet1!$B$1:$D$1",
"values": "Sheet1!$B$2:$D$2"
},
{
"name": "Sheet1!$A$3",
"categories": "Sheet1!$B$1:$D$1",
"values": "Sheet1!$B$3:$D$3"
},
{
"name": "Sheet1!$A$4",
"categories": "Sheet1!$B$1:$D$1",
"values": "Sheet1!$B$4:$D$4"
}],
"title": { "name": "三维簇状柱形图" }
}`)
数据透视
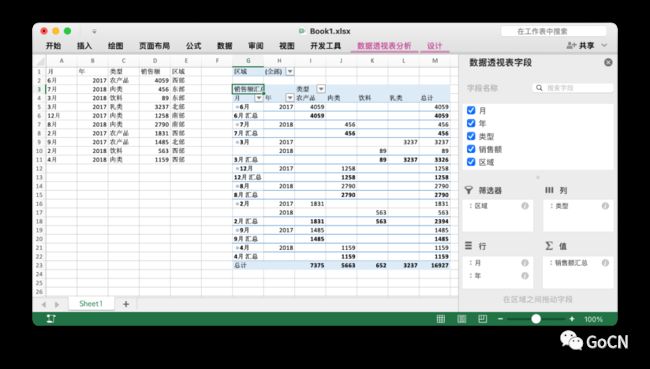
数据透视表是一种交互式的表,是计算、汇总和分析数据的强大工具,可以帮助我们了解数据中的对比情况、模式和趋势。通过 Excelize 提供的 AddPivotTable API 我们在一个包含 5 列源数据的工作表上创建一个数据透视表:
f.AddPivotTable(&excelize.PivotTableOption{
DataRange: "Sheet1!$A$1:$E$31",
PivotTableRange: "Sheet1!$G$2:$M$24",
Rows: []excelize.PivotTableField{
{Data: "月",
DefaultSubtotal: true},
{Data: "年"}},
Filter: []excelize.PivotTableField{
{Data: "区域"}},
Columns: []excelize.PivotTableField{
{Data: "类型",
DefaultSubtotal: true}},
Data: []excelize.PivotTableField{
{Data: "销售额",
Name: "销售额汇总",
Subtotal: "Sum"}},
RowGrandTotals: true,
ColGrandTotals: true,
ShowDrill: true,
ShowRowHeaders: true,
ShowColHeaders: true,
ShowLastColumn: true,
})
PivotTableOption 中可以指定数据透视表中的字段、筛选项、行/列数据、聚合维度等多种分析条件。上面的例子实现了按月对各区域在售的商品销售额进行分类汇总,并支持按销售区域、时间和分类进行筛选。
大规模数据处理
对于处理包含大规模数据的电子表格文档,Excelize 提供了流式处理相关的 API:流式读取可以使用行/列迭代器,生成大文件可以使用流式写入器。下面的例子中我们首先通过 NewStreamWriter API 创建了一个流式写入器,接着创建了字体样式,并按行将数据写入工作表中,与此同时还可以指定单元格的样式,写入结束后调用 Flush 结束流式写入过程,创建了一个包含 102400 行 * 50 列累计 512 万单元格的工作表。对于需要生成大规模数据的场景,流式 API 相比普通写入在耗时和内存占用方面都有明显的优势。
streamWriter, err := file.NewStreamWriter("Sheet1")
if err != nil {
fmt.Println(err)
}
styleID, err := file.NewStyle(
`{"font":{"color":"#777777"}}`)
if err != nil {
fmt.Println(err)
}
if err := streamWriter.SetRow("A1",
[]interface{}{
excelize.Cell{
StyleID: styleID, Value: "Data",
},
}); err != nil {
fmt.Println(err)
}
for rowID := 2; rowID <= 102400; rowID++ {
row := make([]interface{}, 50)
for colID := 0; colID < 50; colID++ {
row[colID] = rand.Intn(640000)
}
cell, _ := excelize.CoordinatesToCellName(1,
rowID)
if err := streamWriter.SetRow(cell,
row); err != nil {
fmt.Println(err)
}
}
streamWriter.Flush()
与 Web 应用集成
Excelize 在离线和在线业务场景中都很容易被集成。下面的例子中,我们创建一个简单的 HTTP 服务器接收上传的电子表格文档,向接收到的电子表格文档添加新工作表,并返回下载响应:
func main() {
http.HandleFunc("/process", process)
http.ListenAndServe(":8090", nil)
}
使用 Excelize 的 OpenReader API 打开数据流,接着在内存中对电子表格进行处理:
func process(w http.ResponseWriter, req *http.Request) {
file, _, err := req.FormFile("file")
if err != nil {
fmt.Fprintf(w, err.Error())
return
}
defer file.Close()
f, err := excelize.OpenReader(file)
if err != nil {
fmt.Fprintf(w, err.Error())
return
}
f.NewSheet("NewSheet")
w.Header().Set("Content-Disposition",
"attachment; filename=Book1.xlsx")
w.Header().Set("Content-Type",
req.Header.Get("Content-Type"))
if _, err := f.WriteTo(w); err != nil {
fmt.Fprintf(w, err.Error())
}
return
}
性能表现
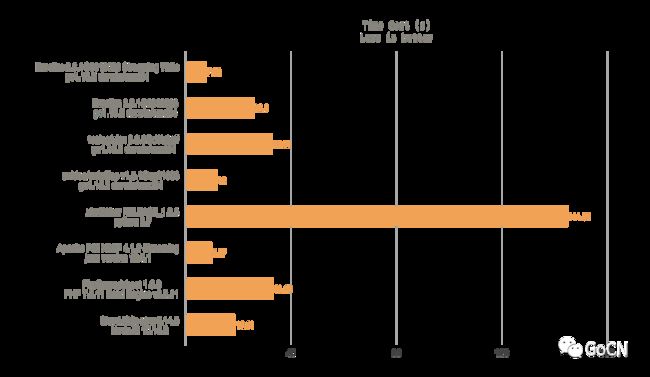
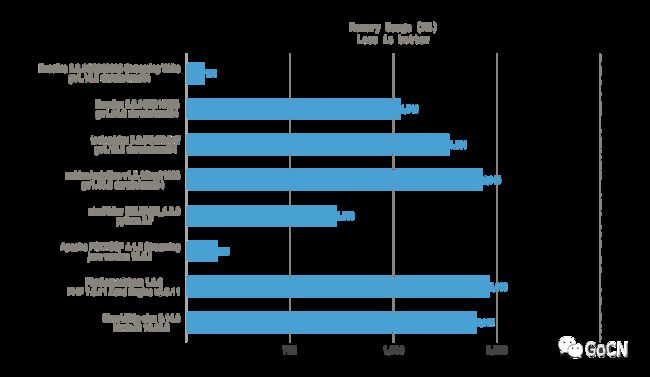
下图展示了主流编程语言中典型电子表格开源基础库,基于普通个人计算机 (OS: macOS Catalina version 10.15.7, CPU: 3.4 GHz Intel Core i5, RAM: 16 GB 2400 MHz DDR4, HDD: 1 TB) 生成 50 列 102400 行纯文本单元格的性能表现:
耗时情况
内存表现
结语
总结今天的话题,本期 Go 开源说首先向大家介绍了开源项目 Excelize 的初衷与发展历程;实现过程中的多项核心技术点:国际电子表格文档格式标准和公式计算引擎的设计;设计理念与典型实践应用场景。Excelize 的开源希望帮助到更多有需要的朋友,未来也将持续完善和优化,同时也欢迎各位 Gopher 通过提交 Issue、Pull Request、Donate、Star 等各种形式参与到开源生态的建设中。
问答环节
Q: Excelize 目前在哪些项目中有应用?
A: 很多企业应用在数据的输入输出链路上都有对电子表格文档自动化处理的需求,比如将电子表格中的数据导入至系统,而为了完成数据闭环一般也会有导出的功能,Excelize 在这些场景已经有了广泛的应用。
Q: Excelize 与 Office Excel 和 WPS 都兼容吗?
A: Excelize 实现了电子表格文档的国际标准,Office Excel、WPS、Apache Office、LibreOffice 和在线 Office 应用:Google Docs、石墨文档等对 XLSX 电子表格文档的支持都遵循同一标准。
Q: 是否可以将打开的文件对象序列化后存入数据库,在读取时进行反序列化?
A: 可以,Excelize 提供了 OpenReader API 打开数据流,WriteTo API 写入数据流。
Q: Excelize 是否有在边缘计算场景的应用?
A: 已经有开发者将 Excelize 应用到了 Android 和其他一些嵌入式系统中了,在本地终端进行电子表格文档操作。
Q: 你觉得做开源项目最难的点是什么?
A: 开源不仅是开放源代码这样简单,需要投入持续的心力,最难的地方在于要有持续的热情,不仅要管“生”还要管“养”。
Q: 做开源项目的过程中有哪些点激励着你做这件事?
A: 来自开源社区和技术交流群里朋友们对项目的支持、在线下的技术分享活动中与使用 Excelize 的开发者交流,也了解到 Excelize 是如何应用到各种业务中的、Go 中国社区组织的开源项目评选的认可等,这些都是项目不断发展的动力。
Q: 做开源的过程中给自己带来了哪些收获?
A: 做开源是一个与社区互动相互促进的过程,同时开源项目价值的被认可也带给我了一些荣誉,更重要的是扩展了我的社交圈、结识了很多朋友,这些都是带给我的收获。
《 Go 开源说 》栏目诚邀开源先锋,如果您有优秀的 Go 开源项目,欢迎点击阅读原文自荐或推荐,Go中国愿意助力您的开源项目推广普及~