selenium实现CSDN自动评论
写在前面
鄙人不才,博客访问数寥寥,仅有的几个评论还几乎都是来捞经验的。于是乎我便写了一个给别人博客评论的脚本,讲究个礼尚往来。
主要的步骤分为:获取博客链接 - 登录 - 评论。
前置操作
需要用到 selenium 和 Beautifulsoup 两个库,通过以下命令安装:
pip install selenium
pip install beautifulsoup4
另外还需要安装 Chromedriver,网上已经说得很详细了,解压后把 .exe 放在 python 目录下即可。
selenium的安装和操作详解
获取博客链接
(我猜测)https://blog.csdn.net 推送的博文应该是每天更新的,于是我们可以从这里获得 url。
注意,通过 chromedriver/requests 启动的访问默认是不带 cookie 的,因此虽然在你的浏览器上每次访问 https://blog.csdn.net 得到的推送不一样,但是通过它们打开的网页始终是一样的。
想要获得全部博文的 url,需要获取一批具有某一特征的标签。F12 找到我们需要的部分,右键,如图。
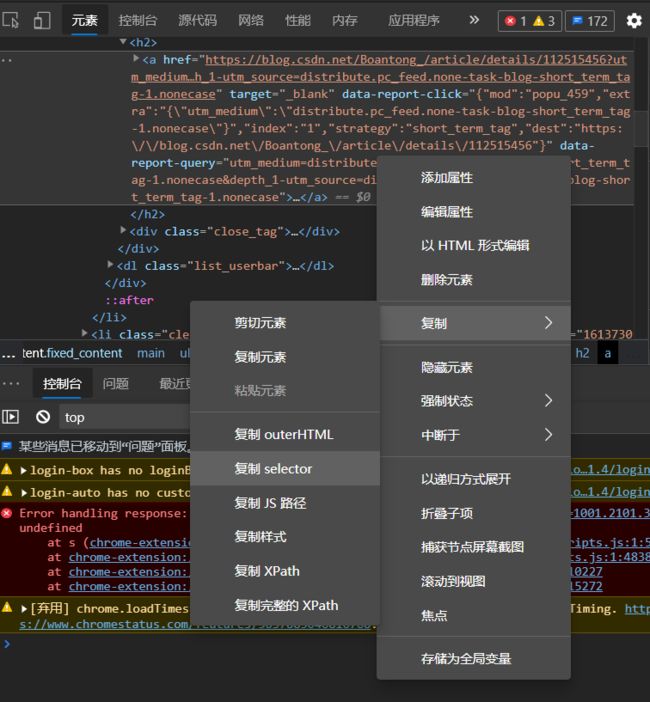
选中赋值 selector 即可得到 #feedlist_id > li:nth-child(1) > div > div > h2 > a,因此这一批标签可以用 selector 描述为:#feedlist_id > li > div > div > h2 > a。调用 soup.select('#feedlist_id > li > div > div > h2 > a') 即可获取。
代码如下:
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.80 Safari/537.36 Edg/86.0.622.48'}
req = requests.get(url = r'https://blog.csdn.net', headers = headers) # 亲测必须要伪装
html = req.text
soup = BeautifulSoup(html, features = "lxml")
hrefs = soup.select('#feedlist_id > li > div > div > h2 > a') # 通过selector选中
hrefs = [u.get('href') for u in hrefs]
登录
想要评论就必须要登录。为了防止直接模拟登陆需要填写验证码,最简单的方法就是通过携带 cookie。
先另写一个程序需要获得登录状态的 cookie:
import time, json
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://passport.csdn.net/login?code=public')
time.sleep(60) # 在这里手操登录
cookiesDict = browser.get_cookies() # 获取list的cookies
cookiesJSON = json.dumps(cookiesDict) # 转换成字符串保存
with open('csdn_cookies.txt', 'w') as fl: # 保存cookies
fl.write(cookiesJSON)
print('cookies have been saved.')
然后读取、添加即可:
browser = webdriver.Chrome()
browser.get(r'https://blog.csdn.net') # 注意要先打开csdn再添加cookie
with open('CSDNremarker/csdn_cookies.txt', 'r') as fl:
list_cookies = json.loads(fl.read())
for cookie in list_cookies:
cookie_dict = {
'domain': '.csdn.net',
'name': cookie.get('name'),
'value': cookie.get('value'),
}
browser.add_cookie(cookie_dict)
browser.refresh() # 刷新网页,cookie生效
评论
for href in hrefs[: 10]:
if not 'marketing' in href: # 过滤广告
browser.get(href)
comment = browser.find_element_by_id('comment_content') # 通过id定位评论框框
comment.send_keys('很牛的啊XD.') # 内容
time.sleep(1) # 太快了不好...
botton = browser.find_element_by_xpath(r'//*[@id="rightBox"]/a/input') # 用xpath定位
botton.click()
time.sleep(2)
完整代码
import time, requests, sys, json
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.80 Safari/537.36 Edg/86.0.622.48'}
req = requests.get(url = r'https://blog.csdn.net', headers = headers)
html = req.text
soup = BeautifulSoup(html, features = "lxml")
hrefs = soup.select('#feedlist_id > li > div > div > h2 > a')
hrefs = [u.get('href') for u in hrefs]
options = webdriver.ChromeOptions()
options.add_argument("--disable-notifications")
browser = webdriver.Chrome(options = options)
browser.get(r'https://blog.csdn.net')
with open('CSDNremarker/csdn_cookies.txt', 'r') as fl:
list_cookies = json.loads(fl.read())
for cookie in list_cookies:
cookie_dict = {
'domain': '.csdn.net',
'name': cookie.get('name'),
'value': cookie.get('value'),
}
browser.add_cookie(cookie_dict)
browser.refresh()
for href in hrefs[: 10]:
if not 'marketing' in href:
browser.get(href)
comment = browser.find_element_by_id('comment_content')
comment.send_keys('很牛的啊XD.')
time.sleep(1)
botton = browser.find_element_by_xpath(r'//*[@id="rightBox"]/a/input')
botton.click()
time.sleep(2)