树莓派4b控制机械手臂_如何将PaddleDetection模型在树莓派4B上部署?

【飞桨开发者说】侯继旭,海南师范大学本三自动化专业在读,人工智能开发爱好者,曾获2019中国高校计算机大赛-人工智能创意赛海南省一等奖、2019年度海南省高等学校科学研究“人工智能”优秀成果奖

本项目以ssd_mobilenet_v1_voc算法为例,详细介绍了从准备数据集、到模型训练,并将模型部署到树莓派的全过程。缺训练数据的痛苦,相信做过模型训练的小伙伴们都深有感触。为了便于大家实战操作,训练数据统统提供!无需任何准备工作就可以体验全流程哈。
项目用到的开源工具包括百度的深度学习平台飞桨以及模型开发套件PaddleDetection、端侧部署工具Paddle Lite、百度一站式AI开发平台AI Studio和树莓派4B。可通过以下方式进行在线或者本地体验:
在线体验:
项目已在AI Studio上公开,包括数据集在内已经打包上传,代码可在线跑通,欢迎Fork!链接:https://aistudio.baidu.com/aistudio/projectdetail/331209
本地体验:
项目涉及的全部资料也都打包放在百度网盘(PaddleDetection、Paddle Lite Demo、Paddle Lite、opt),可下载到本地体验。
链接:https://pan.baidu.com/s/1IKT-ByVN9BaVxfqQC1VaMw 提取码:mdd1
数据集准备
本项目用的数据集格式是VOC格式,标注工具为labelimg,图像数据是手动拍摄获取。
 数据标注:
数据标注:
- 点击Open Dir,打开文件夹,载入图片
- 点击Create RectBox,即可在图像上画框标注
- 输入标签,点击OK
- 点击Save保存,保存下来的是XML文件
 XML文件内容如下
XML文件内容如下
 整理成VOC格式的数据集:
整理成VOC格式的数据集:
创建三个文件夹:Annotations、ImageSets、JPEGImages
 将标注生成的XML文件存入Annotations,图片存入JPEGImages,训练集、测试集、验证集的划分情况存入ImageSets。
将标注生成的XML文件存入Annotations,图片存入JPEGImages,训练集、测试集、验证集的划分情况存入ImageSets。
在ImageSets下创建一个Main文件夹,并且在Mian文件夹下建立labellist.txt,里面存入标注的标签。
此labellist.txt文件复制一份与Annotations、ImageSets、JPEGImages同级位置放置。
其内容如下:
 运行该代码将会生成trainval.txt、train.txt、val.txt、test.txt,将我们标注的600张图像按照训练集、验证集、测试集的形式做一个划分。
运行该代码将会生成trainval.txt、train.txt、val.txt、test.txt,将我们标注的600张图像按照训练集、验证集、测试集的形式做一个划分。
import os
import random
trainval_percent = 0.95 #训练集验证集总占比
train_percent = 0.9 #训练集在trainval_percent里的train占比
xmlfilepath = 'F:/Cola/Annotations'
txtsavepath = 'F:/Cola/ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('F:/Cola/ImageSets/Main/trainval.txt', 'w')
ftest = open('F:/Cola/ImageSets/Main/test.txt', 'w')
ftrain = open('F:/Cola/ImageSets/Main/train.txt', 'w')
fval = open('F:/Cola/ImageSets/Main/val.txt', 'w')for i in list:
name=total_xml[i][:-4]+'\n'if i in trainval:
ftrainval.write(name)if i in train:
ftrain.write(name)else:
fval.write(name)else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()import os
import re
import random
devkit_dir = './'
output_dir = './'
def get_dir(devkit_dir, type):return os.path.join(devkit_dir, type)
def walk_dir(devkit_dir):
filelist_dir = get_dir(devkit_dir, 'ImageSets/Main')
annotation_dir = get_dir(devkit_dir, 'Annotations')
img_dir = get_dir(devkit_dir, 'JPEGImages')
trainval_list = []
train_list = []
val_list = []
test_list = []
added = set()for _, _, files in os.walk(filelist_dir):for fname in files:print(fname)
img_ann_list = []if re.match('trainval.txt', fname):
img_ann_list = trainval_list
elif re.match('train.txt', fname):
img_ann_list = train_list
elif re.match('val.txt', fname):
img_ann_list = val_list
elif re.match('test.txt', fname):
img_ann_list = test_listelse:
continue
fpath = os.path.join(filelist_dir, fname)for line in open(fpath):
name_prefix = line.strip().split()[0]print(name_prefix)
added.add(name_prefix)
#ann_path = os.path.join(annotation_dir, name_prefix + '.xml')
ann_path = annotation_dir + '/' + name_prefix + '.xml'print(ann_path)
#img_path = os.path.join(img_dir, name_prefix + '.jpg')
img_path = img_dir + '/' + name_prefix + '.jpg'assert os.path.isfile(ann_path), 'file %s not found.' % ann_pathassert os.path.isfile(img_path), 'file %s not found.' % img_path
img_ann_list.append((img_path, ann_path))print(img_ann_list)return trainval_list, train_list, val_list, test_list
def prepare_filelist(devkit_dir, output_dir):
trainval_list = []
train_list = []
val_list = []
test_list = []
trainval, train, val, test = walk_dir(devkit_dir)
trainval_list.extend(trainval)
train_list.extend(train)
val_list.extend(val)
test_list.extend(test)
#print(trainval)
with open(os.path.join(output_dir, 'trainval.txt'), 'w') as ftrainval:for item in trainval_list:
ftrainval.write(item[0] + ' ' + item[1] + '\n')
with open(os.path.join(output_dir, 'train.txt'), 'w') as ftrain:for item in train_list:
ftrain.write(item[0] + ' ' + item[1] + '\n')
with open(os.path.join(output_dir, 'val.txt'), 'w') as fval:for item in val_list:
fval.write(item[0] + ' ' + item[1] + '\n')
with open(os.path.join(output_dir, 'test.txt'), 'w') as ftest:for item in test_list:
ftest.write(item[0] + ' ' + item[1] + '\n')if __name__ == '__main__':
prepare_filelist(devkit_dir, output_dir) 将整个文件拷贝至 ./PaddleDetection/dataset/voc 下 以上全部完成后,还需要修改两个地方,ssd
mobilenetv1_voc源码中是以20类目标为准设计的,本项目的目标仅为两类 1. 找到 ./PaddleDetection/configs/ssd/ssd
mobilenetv1
voc.yml文件,修改第12行的numclasses,3代表2个标签加一个背景
将整个文件拷贝至 ./PaddleDetection/dataset/voc 下 以上全部完成后,还需要修改两个地方,ssd
mobilenetv1_voc源码中是以20类目标为准设计的,本项目的目标仅为两类 1. 找到 ./PaddleDetection/configs/ssd/ssd
mobilenetv1
voc.yml文件,修改第12行的numclasses,3代表2个标签加一个背景
num_classes: 3def pascalvoc_label(with_background=True):
labels_map = {
'PepsiCola': 1,'CocaCola': 2
}if not with_background:
labels_map = {k: v - 1 for k, v in labels_map.items()}return labels_map创建项目
进入AI Studio创建项目
 确认创建项目前,需要将数据集添加进去,点击创建数据集,将第一步做好的“PaddleDetection”整个文件夹压缩打包上传。
确认创建项目前,需要将数据集添加进去,点击创建数据集,将第一步做好的“PaddleDetection”整个文件夹压缩打包上传。

 至此,创建项目完成。
至此,创建项目完成。
环境配置
#安装Python依赖库
!pip install -r requirements.txt#测试项目环境
!export PYTHONPATH=`pwd`:$PYTHONPATH
!python ppdet/modeling/tests/test_architectures.py 出现 No module named 'ppdet' 是环境配置的问题,有两种解决办法:
出现 No module named 'ppdet' 是环境配置的问题,有两种解决办法:
1. 设置环境变量
%env PYTHONPATH=/home/aistudio/PaddleDetection
2. 找到报错的文件添加以下代码
import sys
DIR = '/home/aistudio/PaddleDetection'
sys.path.append(DIR)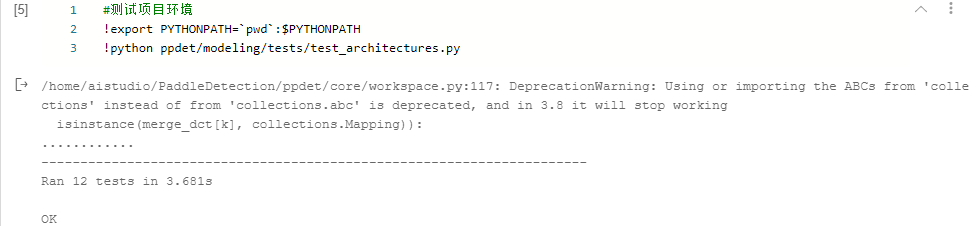 测试环境通过后,就可以开始训练了
测试环境通过后,就可以开始训练了
开始训练
训练命令如下:
%cd home/aistudio/PaddleDetection/
!python -u tools/train.py -c configs/ssd/ssd_mobilenet_v1_voc.yml --use_tb=True --eval#测试,查看模型效果
%cd home/aistudio/PaddleDetection/
!python tools/infer.py -c configs/ssd/ssd_mobilenet_v1_voc.yml --infer_img=/home/aistudio/2001.jpg#infer_img输入需要预测图片的路径,看一下效果模型转换
接下来,需要将原生模型转化为预测模型
!python -u tools/export_model.py -c configs/ssd/ssd_mobilenet_v1_voc.yml --output_dir=./inference_model_final%cd /home/aistudio/#复制opt文件到相应目录下
!cp opt /home/aistudio/PaddleDetection/inference_model_final/ssd_mobilenet_v1_voc#进入预测模型文件夹%cd /home/aistudio/PaddleDetection/inference_model_final/ssd_mobilenet_v1_voc#下载opt文件#!wget https://github.com/PaddlePaddle/Paddle-Lite/releases/download/v2.3.0/opt#给opt加上可执行权限
!chmod +x opt#使用opt进行模型转化,将__model__和__params__转化为model.nb
!./opt --model_file=__model__ --param_file=__params__ --optimize_out_type=naive_buffer --optimize_out=./model
!ls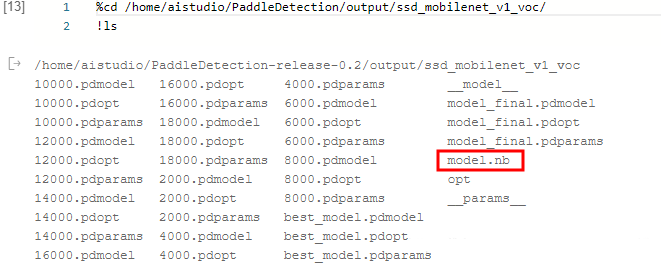 到目前为止,在AI Studio上的所有内容已经完成,生成了这个model.nb文件,就可将其部署在树莓派4B上使用。
到目前为止,在AI Studio上的所有内容已经完成,生成了这个model.nb文件,就可将其部署在树莓派4B上使用。
预测库编译
Paddle Lite目前支持三种编译的环境:
- Docker 容器环境
- Linux(推荐 Ubuntu 16.04)环境
- 树莓派(推荐在树莓派上直接编译)
cmake(建议使用3.10或以上版本) 官方安装流程如下:
# 1. Install basic software
apt update
apt-get install -y --no-install-recomends \
gcc g++ make wget python unzip# 2. install cmake 3.10 or above
wget https://www.cmake.org/files/v3.10/cmake-3.10.3.tar.gz
tar -zxvf cmake-3.10.3.tar.gz
cd cmake-3.10.3
./configure
make
sudo make install将 Paddle Lite 和 Paddle Lite Demo 移动至树莓派中,放在自己方便的目录下即可,在这里我的 Paddle Lite 放在了 /home/pi/ 下,将 Paddle Lite Demo 放在了 /home/pi/Desktop/ 下,并且将 /home/pi/Paddle/Paddle-Lite/lite/tools/build.sh 加上执行权限
 所有工作完成后,即可开始编译Paddle Lite
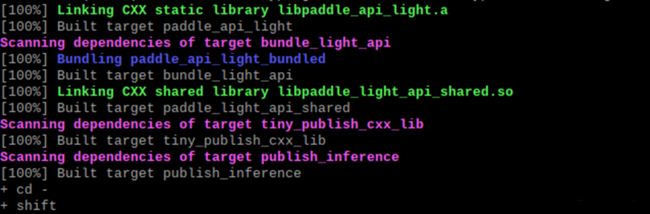
所有工作完成后,即可开始编译Paddle Lite
cd /home/pi/Paddle/Paddle-Lite
sudo ./lite/tools/build.sh \--build_extra=OFF \--arm_os=armlinux \--arm_abi=armv7hf \--arm_lang=gcc \
tiny_publish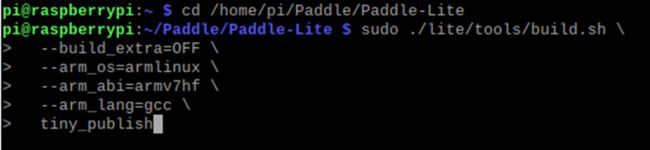 编译结束,结果如下:
编译结束,结果如下:
文件结构搭建
整体文件结构如下:
 1. 打开 /home/pi/Desktop/Paddle-Lite-Demo/PaddleLite-armlinux-demo/object
detectiondemo 文件夹,在此目录下新建 Paddle Lite、code 文件夹。 2. Paddle Lite文件夹下新建 include、libs 文件夹。 3. libs文件夹下新建 armv7hf 文件夹。 4. 将 images、labels、CMakeLists.txt、run.sh、object
detectiondemo.cc 文件移入 code 文件夹下。 对于 Paddle Lite 的编译结果,我们需要使用的东西在 /home/pi/Paddle/Paddle-Lite/build.lite.armlinux.armv7hf.gcc/inference
litelib.armlinux.armv7hf/cxx 文件夹下
1. 打开 /home/pi/Desktop/Paddle-Lite-Demo/PaddleLite-armlinux-demo/object
detectiondemo 文件夹,在此目录下新建 Paddle Lite、code 文件夹。 2. Paddle Lite文件夹下新建 include、libs 文件夹。 3. libs文件夹下新建 armv7hf 文件夹。 4. 将 images、labels、CMakeLists.txt、run.sh、object
detectiondemo.cc 文件移入 code 文件夹下。 对于 Paddle Lite 的编译结果,我们需要使用的东西在 /home/pi/Paddle/Paddle-Lite/build.lite.armlinux.armv7hf.gcc/inference
litelib.armlinux.armv7hf/cxx 文件夹下
 将 include 和 lib 中的头文件和库文件提取出来,分别放入 include 和 armv7hf 文件夹中,至此已做好文件结构的搭建.
将 include 和 lib 中的头文件和库文件提取出来,分别放入 include 和 armv7hf 文件夹中,至此已做好文件结构的搭建.
模型部署
接下来就是最后一步了,将模型放进文件中,稍作修改就大功告成了!
1. 进入 code 文件夹。 2. 修改 labels 文件夹下的 pascalvoclabellist ,内容必须与训练时的 labellist.txt 文件内容一致 (注意 pascalvoclabel_list 是纯文本文档,不是 .txt 文本文档,弄错了预测出来的框选标签会打 unknow 的!)。 3. 将在 PaddlePaddle学习之使用PaddleDetection在树莓派4B进行模型部署(二)----- 深度学习模型训练 得到的 model.nb 放进 models 文件夹。 4. 打开 run.sh 文件,注释掉第四行的 TARGETARCHABI=armv8 ,打开第五行的,取消第5行 TARGETARCHABI=armv7hf 的注释。 5. 修改第六行的 PADDLE LITEDIR 索引到文件中Paddle Lite目录。 6. 修改第十九行的model文件的模型索引目录和预测图片的索引目录。#!/bin/bash# configure#TARGET_ARCH_ABI=armv8 # for RK3399, set to default arch abi
TARGET_ARCH_ABI=armv7hf # for Raspberry Pi 3B
PADDLE_LITE_DIR=/home/pi/Desktop/Paddle-Lite-Demo/PaddleLite-armlinux-demo/object_detection_demo/Paddle-Liteif [ "x$1" != "x" ]; then
TARGET_ARCH_ABI=$1fi# build
rm -rf build
mkdir buildcd build
cmake -DPADDLE_LITE_DIR=${PADDLE_LITE_DIR} -DTARGET_ARCH_ABI=${TARGET_ARCH_ABI} ..
make#run
LD_LIBRARY_PATH=$LD_LIBRARY_PATH:${PADDLE_LITE_DIR}/libs/${TARGET_ARCH_ABI} ./object_detection_demo ../models/model.nb ../labels/pascalvoc_label_list ../images/2001.jpg ./result.jpg/home/pi/Desktop/Paddle-Lite-Demo/PaddleLite-armlinux-demo/object_detection_demo/code
sudo ./run.sh 图片的预测结果就是这样了,虽然一个类别只有300张图,但是总的来说结果还算不错!
图片的预测结果就是这样了,虽然一个类别只有300张图,但是总的来说结果还算不错!
 关于视频流的实时监测,在源代码的主函数中可以看到
关于视频流的实时监测,在源代码的主函数中可以看到
if (argc > 3) {
WARMUP_COUNT = 1;
REPEAT_COUNT = 5;std::string input_image_path = argv[3];std::string output_image_path = argv[4];
cv::Mat input_image = cv::imread(input_image_path);
cv::Mat output_image = process(input_image, word_labels, predictor);
cv::imwrite(output_image_path, output_image);
cv::imshow("Object Detection Demo", output_image);
cv::waitKey(0);
} else {
cv::VideoCapture cap(-1);
cap.set(cv::CAP_PROP_FRAME_WIDTH, 640);
cap.set(cv::CAP_PROP_FRAME_HEIGHT, 480);if (!cap.isOpened()) {
return -1;
}while (1) {
cv::Mat input_image;
cap >> input_image;
cv::Mat output_image = process(input_image, word_labels, predictor);
cv::imshow("Object Detection Demo", output_image);if (cv::waitKey(1) == char('q')) {
break;
}
}
cap.release();
cv::destroyAllWindows();
}#runLD_LIBRARY_PATH=$LD_LIBRARY_PATH:${PADDLE_LITE_DIR}/libs/${TARGET_ARCH_ABI} ./object_detection_demo ../models/ssd_mobilenet_v1_pascalvoc_for_cpu/best.nb ../labels/pascalvoc_label_list #../images/2.jpg ./result.jpg 注:如果有用 Opencv-4.1.0 版本的,可能在编译 object
detectiondemo.cc 时在 267、268 行会报错。
注:如果有用 Opencv-4.1.0 版本的,可能在编译 object
detectiondemo.cc 时在 267、268 行会报错。
源代码如下:
cap.set(CV_CAP_PROP_FRAME_WIDTH, 640);
cap.set(CV_CAP_PROP_FRAME_HEIGHT, 480);cap.set(cv::CAP_PROP_FRAME_WIDTH, 640);cap.set(cv::CAP_PROP_FRAME_HEIGHT, 480);- Paddle Lite官方文档https://paddle-lite.readthedocs.io/zh/latest/index.html
- PaddleDetection官方文档https://github.com/PaddlePaddle/PaddleDetection
- 系列文章:如何利用PaddleDetection做一个完整的项目https://blog.csdn.net/yzl819819/article/details/104336990?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
有奖调研
为了更好的了解您在深度学习领域的需求及对飞桨的建议反馈,希望您可以抽出3分钟的宝贵时间填写问卷,您的建议和反馈,将会支持我们进行产品的迭代和优化!调研结束后,我们将选出5️⃣名最佳贡献者,5️⃣名特别关注者,以及再随机抽取?名用户感恩回馈,送上精选礼品???感谢大家对我们的支持和关注!问卷链接(点击 “阅读原文” 打开): https://iwenjuan.baidu.com/?code=ciynjt 如在使用过程中有问题,可加入飞桨官方QQ群进行交流: 703252161 。 如果您想详细了解更多飞桨的相关内容,请参阅以下文档。 官网地址: https://www.paddlepaddle.org.cn 飞桨开源框架项目地址: GitHub: https://github.com/PaddlePaddle/Paddle Gitee: https://gitee.com/paddlepaddle/PaddleEND
