训练出一个验证码模型,验证码识别100%?就很棒
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理
以下文章来源于腾讯云 作者:Python进击者
( 想要学习Python?Python学习交流群:1039649593,满足你的需求,资料都已经上传群文件流,可以自行下载!还有海量最新2020python学习资料。 )

1.熟悉项目结构
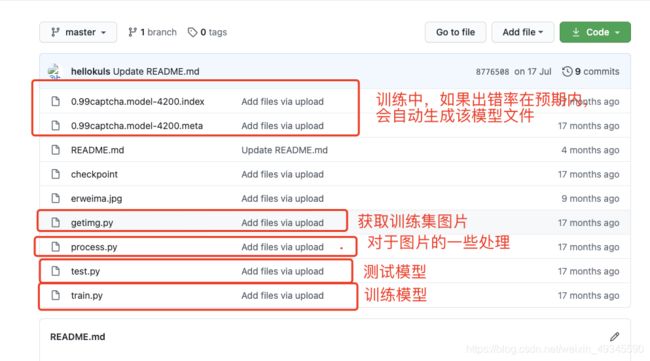
这里我给大家都标识出来了,首先你需要了解每个文件是干什么的,不然你就会像只无头苍蝇。
这里的每一个文件都很重要。
2. 使用前的准备
使用之前是需要你准备好你的数据集,那么怎么准备呢?
如果你是需要爬取A网站,那么你可以通过第三方库生成与A网站相同的验证码图片
你也可以直接爬取它的图片
但是我们需要注意的是,图片的命名中必须要有相对应的字母或者数字。

例如我上面这样
所以最好还是自己去生成对应的验证码。
数量集需要多少呢?
我每次训练都是使用了1万张以上的照片
基本的准备好了,我们如何来使用该项目呢?
3.修改项目
没错,确实需要修改
修改什么?
你的图片路径以及你的命名规则
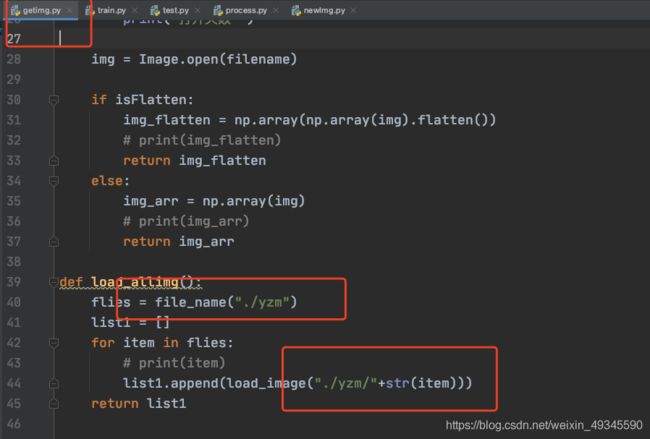
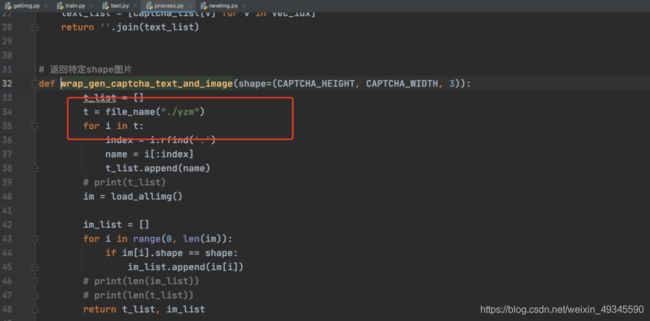
像上图这些地方,肯定是需要修改的。
其次,命名规则在哪里修改?

其中i变量就是该图片的名称(包括后缀),所以自己按照自己命名规则切割一下就行了。
4.开始训练模型
以上的工作都准备好后,我们就可以正式训练模型了。
直接运行train.py文件即可。
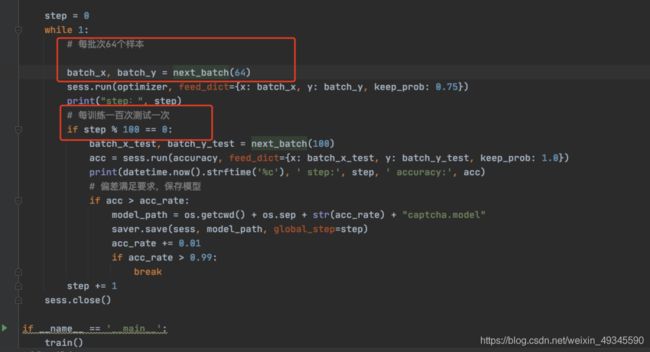
图片中红框内的数据可以按需进行修改

当你跑起来后就是这样的。
5.测试模型
这就非常的简单了

我们直接运行test.py文件即可。
一些问题
1.该项目使用的TensorFlow是版本几?
1.xxx
如果你使用的是2也可以,只需要将
import tensorflow as tf
替换为
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
爆红线也不用管它。
2.训练出来的准确率高吗?
我认为主要看验证码的复杂程度,至少我训练出来的准确率有99%