python(numpy,pandas10)——pandas 合并数据 concat,append
文章目录
- 前言
- concat
-
- 参数axis,ignore_index
- 参数join
- append
-
- append添加一个数据索引不同的数列
前言
根据 莫烦Python的教程 总结写成,以便自己复习和使用,这里我就不哟林地挂原创了。
concat
参数axis,ignore_index
df1 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1,columns=['a','b','c','d'])
df3 = pd.DataFrame(np.ones((3,4))*2,columns=['a','b','c','d'])
res = pd.concat([df1,df2,df3],axis=0,ignore_index=True)# 0:行方向;1:列方向,默认是0; ignore_index 重新排列行的序列,默认是False
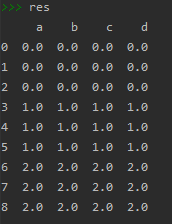
res = pd.concat([df1,df2,df3],axis=0,ignore_index=False) # 不重新排列行的序号
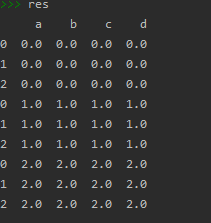
参数join
处理合并的时候索引不同的情况
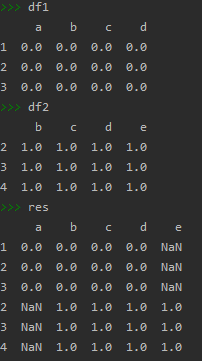
df1 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'],index=[1,2,3])
df2 = pd.DataFrame(np.ones((3,4))*1,columns=['b','c','d','e'],index=[2,3,4])
res = pd.concat([df1,df2],join='inner') # join为‘inner’:将不同的索引数据忽略掉;join默认是outer:用nan补充
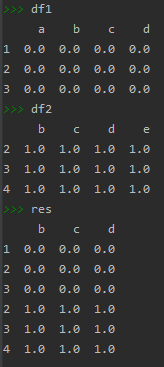
join默认是outer:用nan补充
pd.concat([df1,df2],join='inner')
append
df1 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1,columns=['a','b','c','d'])
df3 = pd.DataFrame(np.ones((3,4))*1,columns=['a','b','c','d'])
res = df1.append([df2,df3],ignore_index=True)
append添加一个数据索引不同的数列
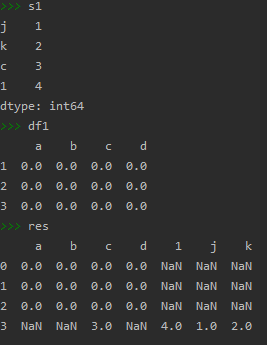
s1 = pd.Series([1,2,3,4],index=['j','k','c','d'])# Series产生的是一个带有字典的数列,这里只有index,这里的index就是一个key,而不像DataFrame中行号
res = df1.append(s1,ignore_index=True)# 这里的append是将s1并到列上