大数据平台Hadoop的分布式集群环境搭建
1 概述
本文章介绍大数据平台Hadoop的分布式环境搭建、以下为Hadoop节点的部署图,将NameNode部署在master1,SecondaryNameNode部署在master2,slave1、slave2、slave3中分别部署一个DataNode节点
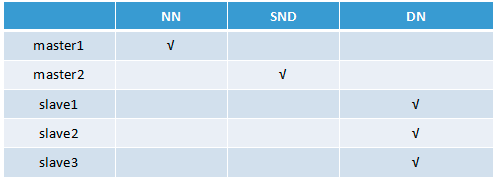
NN=NameNode(名称节点)
SND=SecondaryNameNode(NameNode的辅助节点)
DN=DataNode(数据节点)
2 前期准备
(1)准备五台服务器
如:master1、master2、slave1、slave2、slave3
(2)关闭所有服务器的防火墙
$ systemctl stop firewalld$ systemctldisablefirewalld
(3)分别修改各服务器的/etc/hosts文件,内容如下:
192.168.56.132 master1
192.168.56.133 master2
192.168.56.134 slave1
192.168.56.135 slave2
192.168.56.136 slave3
注:对应修改个服务器的/etc/hostname文件,分别为 master1、master2、slave1、slave2、slave3
(4)分别在各台服务器创建一个普通用户与组
$ groupadd hadoop#增加新用户组$ useradd hadoop -m -g hadoop#增加新用户$ passwd hadoop#修改hadoop用户的密码
切换至hadoop用户:su hadoop
(5)各服务器间的免密码登录配置,分别在各自服务中执行一次
$ ssh-keygen -t rsa#一直按回车,会生成公私钥$ ssh-copy-id hadoop@master1#拷贝公钥到master1服务器$ ssh-copy-id hadoop@master2#拷贝公钥到master2服务器$ ssh-copy-id hadoop@slave1#拷贝公钥到slave1服务器$ ssh-copy-id hadoop@slave2#拷贝公钥到slave2服务器$ ssh-copy-id hadoop@slave3#拷贝公钥到slave3服务器。如果你对大数据挖掘感兴趣,想系统学习大数据的话,可以加入大数据技术学习交流扣扣群:458数字345数字782,欢迎添加,了解课程介绍,获取学习资源
注:以上操作需要登录到hadoop用户操作
(6)下载hadoop包,hadoop-2.7.5.tar.gz
官网地址:https://archive.apache.org/dist/hadoop/common/hadoop-2.7.5/
3 开始安装部署
(1)创建hadoop安装目录
$ mkdir -p /home/hadoop/app/hadoop/{tmp,hdfs/{data,name}}
(2)将安装包解压至/home/hadoop/app/hadoop下
$tarzxf tar -zxf hadoop-2.7.5.tar.gz -C /home/hadoop/app/hadoop
(3)配置hadoop的环境变量,修改/etc/profile
JAVA_HOME=/usr/java/jdk1.8.0_131JRE_HOME=/usr/java/jdk1.8.0_131/jreHADOOP_HOME=/home/hadoop/app/hadoop/hadoop-2.7.5PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbinexportPATH
(4)刷新环境变量
$source/etc/profile
4 配置Hadoop
(1)配置core-site.xml
$ vi /home/hadoop/app/hadoop/hadoop-2.7.5/etc/hadoop/core-site.xml
默认配置地址:http://hadoop.apache.org/docs/r2.7.5/hadoop-project-dist/hadoop-common/core-default.xml
(2)配置hdfs-site.xml
$ vi /home/hadoop/app/hadoop/hadoop-2.7.5/etc/hadoop/hdfs-site.xml
dfs.replication 3 dfs.namenode.name.dir /home/hadoop/app/hadoop/hdfs/name dfs.datanode.data.dir /home/hadoop/app/hadoop/hdfs/data dfs.permissions.enabled false dfs.namenode.secondary.http-address master2:50090
默认配置地址:http://hadoop.apache.org/docs/r2.7.5/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
(3)配置mapred-site.xml
$ cp /home/hadoop/app/hadoop/hadoop-2.7.5/etc/hadoop/mapred-site.xml.template /home/hadoop/app/hadoop/hadoop-2.7.5/etc/hadoop/mapred-site.xml
$ vi /home/hadoop/app/hadoop/hadoop-2.7.5/etc/hadoop/mapred-site.xml
默认配置地址:http://hadoop.apache.org/docs/r2.7.5/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
(4)配置yarn-site.xml
$ vi /home/hadoop/app/hadoop/hadoop-2.7.5/etc/hadoop/yarn-site.xml
默认配置地址:http://hadoop.apache.org/docs/r2.7.5/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
(5)配置slaves
$ vi /home/hadoop/app/hadoop/hadoop-2.7.5/etc/hadoop/slaves
slave1
slave2
slave3
slaves文件中配置的是DataNode的所在节点服务
(6)配置hadoop-env
修改hadoop-env.sh文件的JAVA_HOME环境变量,操作如下:
$ vi /home/hadoop/app/hadoop/hadoop-2.7.5/etc/hadoop/hadoop-env.sh
exportJAVA_HOME=/usr/java/jdk1.8.0_131
(7)配置yarn-env
修改yarn-env.sh文件的JAVA_HOME环境变量,操作如下:
$ vi /home/hadoop/app/hadoop/hadoop-2.7.5/etc/hadoop/yarn-env.sh
exportJAVA_HOME=/usr/java/jdk1.8.0_131
(8)配置mapred-env
修改mapred-env.sh文件的JAVA_HOME环境变量,操作如下:
$ vi /home/hadoop/app/hadoop/hadoop-2.7.5/etc/hadoop/mapred-env.sh
exportJAVA_HOME=/usr/java/jdk1.8.0_131
(9)将master1中配置好的hadoop分别远程拷贝至maser2、slave1 、slave2、slave3服务器中
$ scp -r /home/hadoop/app/hadoop hadoop@master2:/home/hadoop/app/
$ scp -r /home/hadoop/app/hadoop hadoop@slave1:/home/hadoop/app/
$ scp -r /home/hadoop/app/hadoop hadoop@slave2:/home/hadoop/app/
$ scp -r /home/hadoop/app/hadoop hadoop@slave3:/home/hadoop/app/
5 启动测试
(1)在master1节点中初始化Hadoop集群
$ hadoop namenode -format
(2)启动Hadoop集群
$ start-dfs.sh
$ start-yarn.sh
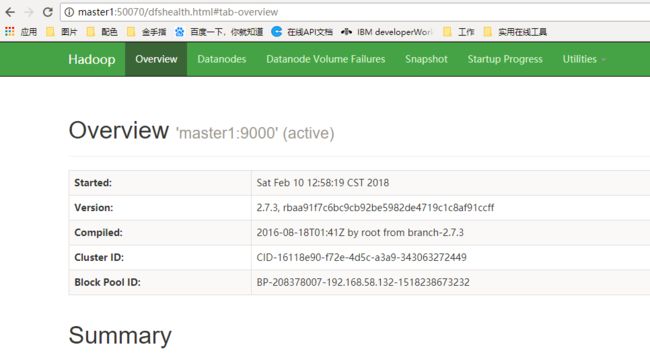
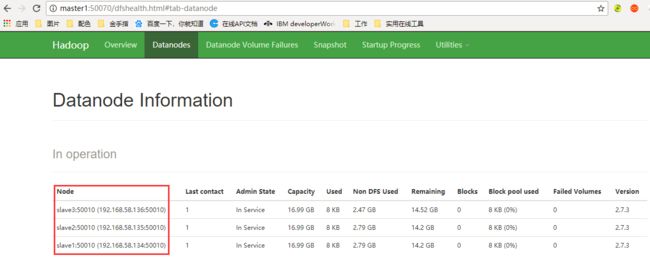
(3)验证集群是否成功
浏览器中访问50070的端口,如下证明集群部署成功