一、Hadoop集群环境搭建配置
1、前言
Hadoop的搭建分为三种形式:单机模式、伪分布模式、完全分布模式,只要掌握了完全分布模式,也就是集群模式的搭建,剩下的两种模式自然而然就会用了,一般前两种模式一般用在开发或测试环境下,Hadoop最大的优势就是分布式集群计算,所以在生产环境下都是搭建的最后一种模式:完全分布模式。
2、硬件选择
须知:
- 分布式环境中一个服务器就是一个节点
- 节点越多带来的是集群性能的提升
- 一个Hadoop集群环境中,NameNode,SecondaryNameNode和DataNode是需要分配不同的节点上,也就需要三台服务器
- 在Hadoop运行作业完成时,History Server来记录历史程序的运行情况,需要独立一台服务器
- 第一台:记录所有的数据分布情况,运行进程:NameNode
第二台:备份所有数据分布情况,因为当前面的那台服务器宕机(日常所说的死机)时,可通过该服务器来恢复数据。所以,该服务器运行的程序就是:SecondaryNameNode
第三台:存储实际数据,运行的进程就是;DataNode
第四台:记录应用程序历史的运行状况。运行的程序就是:History Server。(可选)
所以说,至少三台。
3、集群环境各个服务配置
- 在Hadoop集群环境中,最重要的就是NameNode运行的服务器是整个集群的调度和协调工作,还有一个很重要的进程是资源管理(真正的协调整个集群中每个节点的运行),所以配置要高于其他节点。

4、软件选择
关于Hadoop集群环境软件的选择,无非就是围绕这个几个软件产品去选择:OS操作系统,Hadoop版本,JDK版本,Hive版本、MySQL版本等。
5、节点配置信息的分配

提前规划出四台服务器用来搭建Hadoop集群,然后分别为其分配了机器名称、IP,IP需要设置为统一网段,可根据使用的情况,进行动态调整的。
另外说明:搭建了两台Ubuntu的服务器来单独安装MySQLServer,搭建了一个主从模式,Ubuntu是一个界面友好的操作系统,这里和Hadoop集群分离的目的是因为Mysql数据库是比较占内存资源的,所以我们单独机器来安装,当然,MySQL并不是Hadoop集群所需要的,两者没有必然的关系,这里搭建它的目的就为了后续安装Hive来分析数据应用的,并且我们可以在这个机器里进行开发调试,当然Window平台也可以,毕竟我们使用Windows平台是最熟练的。(hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。)
二、Hadoop集群环境安装
安装前需明了:
- 将Hadoop集群中的主节点分配2GB内存,然后剩余的三个节点都是1GB配置。
- 所有的节点存储都设置为50GB
1、安装流程
- 首先需要在VMWare中创建一个新的计算机,然后指定CentOS的镜像路径和用户名和密码。
- 指定当前虚拟机操作系统的存储大小(50GB)和内存大小(2GB)。
- 完成安装
- 至此,我们已经成功的安装上了CentOS操作系统,然后安装的过程中顺便创建了一个新用户Hadoop,这个账户就是我们后面安装Hadoop集群环境所使用的账号。
- 我们登录到CentOS操作系统,然后为了后续节点识别,要改计算机名。Master.Hadoop,然后重启。(不知理解是否有误)
(1)、切换到root用户
(2)、编辑/etc/sysconfig/network文件:vi /etc/sysconfig/network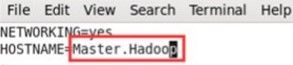
(3)、保存该文件,重启计算机(reboot)
(4)、查看是否生效:hostname - 设置固定IP(验证我们当前虚拟机是否能上网,IP是否能成功配置。),然后配置Host文件(添加集群对应ip与节点名)。(还有要改桥接模式(B):直接连接物理网络。现在用的是虚拟机,但是把它当成物理机一样,也给插上网线,连接到本地的网络中去。当然,如果选择这种方式的前提是要保证局域网的网段和之前规划的IP是一致的,必须都是192.168.1.* 这种网段,这样的目的就是宿主机和我们的虚拟机能够直接通信,那就意味这主机能联网,我们的虚拟机就能联网。)
(1)、固定IP设置:首先配置DNS,对/etc/resolv.conf 文件进行修改或查看
(2)、配置固定IP地址:修改 /etc/sysconfig/network-scripts/ifcfg-eth0 文件
(3)、重启网络:/etc/init.d/network restart或service network restart
修改成功:
(4)、ping通网络。
(5)、修改host文件
(6)、重启服务器 - 下载Hadoop安装包,然后进入Hadoop集群的搭建工作。
把jdk和Hadoop包下载或上传到/home/hadoop/Downloads/下
(1)、jdk的安装与配置:
一般将安装的程序存到/usr目录下,所以创建Java目录:mkdir /usr/java,
然后更改权限chown hadoop:hadoop /usr/java/,
然后查看ll /usr
然后更改系统的环境变量vim /etc/profile
然后添加脚本# set java environment
export JAVA_HOME=/usr/java/jdk1.8.0_121
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
然后将解压好的jdk移到/usr/java目录中:cp -r jdk1.8.0_121 /usr/java/
然后查看版本:java -version
(2)、Hadoop的安装与配置:
与Jdk配置类似,--/usr目录下,创建hadoop目录
mkdir /usr/hadoop
--拷贝解压后的hadoop安装包
cp -r hadoop-2.6.4 /usr/hadoop
--赋权给Hadoop用户
chown hadoop:hadoop /usr/hadoop/
--查看确认
ll /usr/
对几个关键的文件进行配置:
转到目录:cd /usr/hadoop/hadoop-2.6.4/
配置第一个文件vim etc/hadoop/core-site.xml
fs.defaultFS
hdfs://192.168.1.50:9000
io.file.buffer.size
131072
hadoop.tmp.dir
file:/usr/hadoop/hadoop-2.6.4/tmp
Abasefor other temporary directories.
创建目录mkdir tmp
配置第二个文件vim etc/hadoop/hdfs-site.xml
dfs.namenode.secondary.http-address
192.168.1.50:9001
dfs.namenode.name.dir
file:/usr/hadoop/hadoop-2.6.4/dfs/name
dfs.datanode.data.dir
file:/usr/hadoop/hadoop-2.6.4/dfs/data
dfs.replication
1
dfs.webhdfs.enabled
true
文件解释:
创建目录:mkdir dfs
mkdir dfs/name
mkdir dfs/data
配置第三个文件:cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml因为在这里Hadoop已经提供了一个模板,直复制创建,然后修改此文件:vim etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
192.168.1.50:10020
mapreduce.jobhistory.webapp.address
192.168.1.50:19888
配置第四个文件:vim etc/hadoop/yarn-site.xml
配置Hadoop的jdk路径,不指定是不能运行的,hadoop-env.sh 和 yarn-env.sh 在开头添加如下java环境变量:export JAVA_HOME=/usr/java/jdk1.8.0_73 vim etc/hadoop/hadoop-env.sh 
vim etc/hadoop/yarn-env.sh 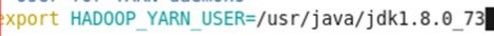
因为所有Hadoop用户都有执行权限,所以: chown -R hadoop:hadoop /usr/hadoop/hadoop-2.6.4/
- Hadoop配置。Hadoop环境的配置分为两步:1、Java环境配置;2、Hadoop配置。因为Hadoop就是Java语言编写的,所以一定要先配置好Java环境。
(1)Java环境的配置
见第7步
(2)Hadoop环境的配置
见第7步 - 然后格式化文件,来启动这个单节点的Hadoop集群
(1)Hadoop 分布式存储系统的HDFS格式化,这个只能在初始化系统的时候用一次,一次就好了,要不执行一次数据就丢失一次。bin/hadoop namenode -format运行结果:
(2)Hadoop 集群进行启动验证:启动HDFS:sbin/start-dfs.sh然后查看jps进程:
然后,查看状态bin/hadoop dfsadmin -report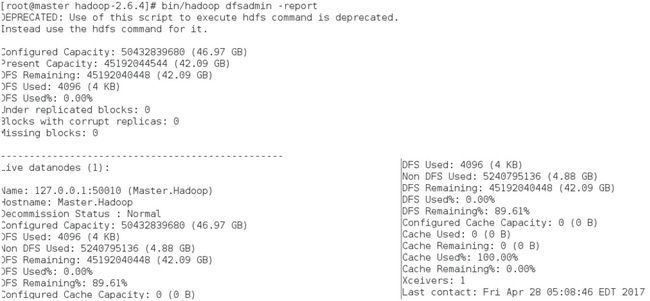
或者直接打开浏览器直接打开浏览器查看:http://192.168.10.87:50070/dfshealth.html#tab-overview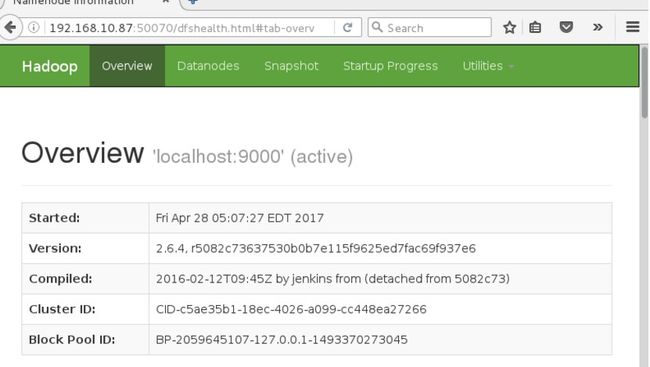
(3)Hadoop 集群启动查看
启动Hadoop集群,然后查看其状态sbin/start-yarn.sh
用浏览器打开:http://192.168.10.87:8088/cluster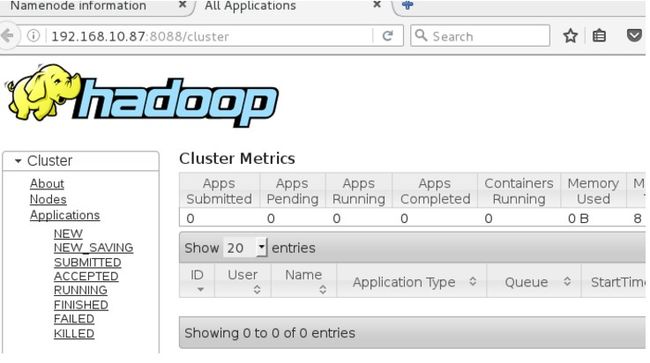
三、Hadoop集群完全分布式坏境搭建
上一部分是单节点的安装,工作已经完成了一半,下面进行的是完全分布式的环境搭建。
为了减少配置时间,我直接对上一节点进行克隆
节点基本信息: 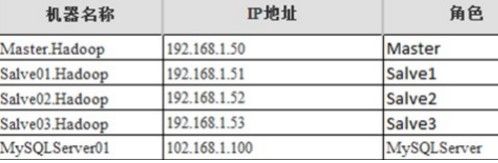
总共需要5台服务器来使用,四台用来搭建Hadoop集群使用,另外一台(可选)作为MySQL等外围管理Hadoop集群来使用。在开发的时候一般也是直接通过连接外围的这台机器来管理Hadoop整个集群
工作大概流程: 
- 首先需要在VMWare中将之前创建的单实例的计算机进行克隆。
注意:在克隆过程中一定要选择克隆一个完整的而不是创建链接克隆,也一定不要选择现有的快照。 - 配置各个Slave节点的机器信息。
(1)主节点Master的CUP处理器设置成多路多核,这里设成4,其他节点设成1
(2)手动更改各个从节点的计算机名和Hosts文件(必须!)vim /etc/sysconfig/network
vim /etc/hosts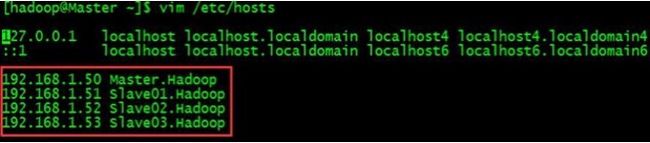
配置完之后,重启完各个机器之后,确保各个节点之间可以ping 通(重点!!!) - 配置SSH无密码配置。
(1-1)、进行sshd的配置文件的修改,去掉默认注释,开启SSH验证功能(以root用户进行操作)vim /etc/ssh/sshd_config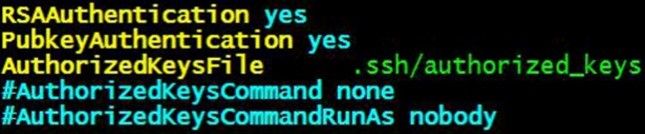
将上面的这三行数据的注释“#”去掉进行,保存。这里记住了!所有的机器都要这么依次进行设置。RSAAuthentication是指开启SSH验证,PubkeyAuthetication是指可以通过公钥进行验证,AuthorizedkeysFile则指的的是公钥存放的位置。
(1-2)、重启该服务:/sbin/service sshd restart
(1-3)、用本机验证一下:ssh localhost这个时候会让你输入密码,是因为没有生成密钥,下面进行设置
(2-1)、加工生成证书公私钥,分发到各个服务器(以Hadoop用户操作)在Master节点上生成Hadoop用户的公钥,然后将这个公钥分发给各个slave节点,然后这样在Master机器上就可以用Hadoop无密码登录到各个salve机器上面了
(2-2)、ssh-keygen -t rsa -P ''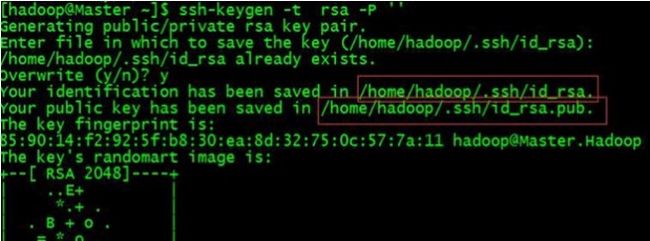 红框勾出的路径就是公钥和私钥生成的默认路径
红框勾出的路径就是公钥和私钥生成的默认路径
(2-3)、下一步就是将这个公钥复制到各个slave节点中去,远程文件的复制:scp ~/.ssh/id_rsa.pub 远程用户名@远程服务器IP:~/复制的公钥文件存在默认的路径“/home/hadoop/.ssh”scp ~/.ssh/id_rsa.pub hadoop@192.168.1.51:~/
(2-4)、登录salve01的机器将刚才生成的公钥加入的本地的权限验证组里面去cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
(2-5)、回到Master机器上面进行,ssh验证SSH <远程IP && 域名>在master机器上登录slave01机器上实验下,看是否还需要进行密码输入ssh slave01.hadoop从Master机器上面无密码的登录到Slave01机器上面,那么说明刚才的配置生效了。
(2-6)、参照上面的步骤将各个Slave节点配置完成
(2-7)、注意:在Master生成密钥只需要生成一次就可以了,不要再次生成!因为每次生成以为着所有的节点都需要重新配置。
(2-8)、参照上面的步骤将各个Slave节点SSH到Master机器(保证各个Slave节点能够无密码登录Master机器,各个Slave子节点干完Master分配的任务之后,需要有权限反馈至Master)
注意:上面的步骤要一定完成验证,要不以后的Hadoop操作会很出现各种诡异的问题!!
(3-1)、配置Hadoop集群配置
将这个单节点的配置成一个真正的分布式集群,充分利用我们刚才搭建的几台Server进行性能的最大发挥
(3-2)、首先进行slaves文件的配置,指定该集群的各个Slave节点的位置(以hadoop用户进行操作)(只需要在Master的机器上面进行就可以了)vim /usr/hadoop/hadoop-2.6.4/etc/hadoop/slaves将各个Slave的IP或者机器名写入![]
(3-3)、更改hdfs-site.xml文件中的dfs.replication属性值为3(因为有另外3台虚拟机,记住:只能是奇数!)vim /usr/hadoop/hadoop-2.6.4/etc/hadoop/hdfs-site.xml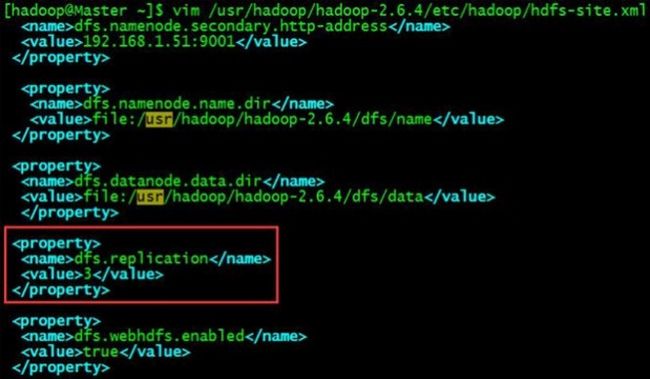 (这里需要注意的是,所有的机器都要这样配置。)
(这里需要注意的是,所有的机器都要这样配置。)
(4-1)、启动Hadoop集群,验证是否成功
先来执行一个HDFS格式的命令(改成完全分布式的集群,所以这里需要重新格式)bin/hadoop namenode -format
(4-2)、验证一下整个集群的HDFS是否正常可用,启动整个集群的HDFS,在Master机器上面,用hadoop用户操作start-dfs.sh
通过浏览器来查看整个集群的HDFS状态,地址为:http://192.168.1.50:50070/dfshealth.html#tab-overview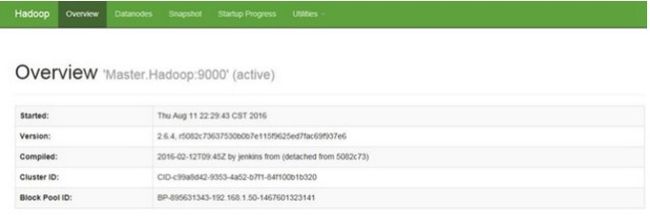
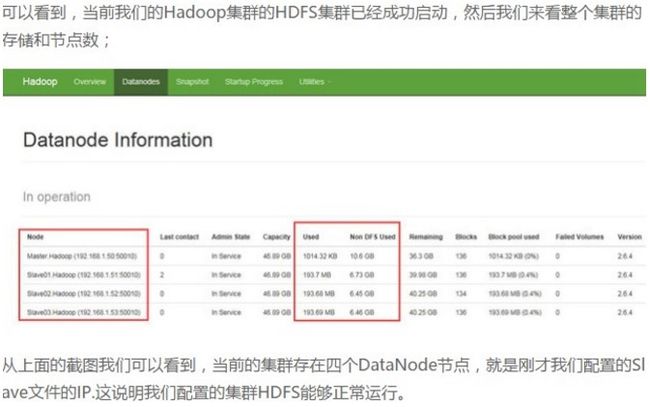
(4-3)、验证一下整个集群的YARN分布式计算框架是否正常可用,启动Yarnstart-yarn.sh 通过浏览器来查看整个集群的Hadoop集群状态,地址为:http://192.168.1.50:8088/
通过浏览器来查看整个集群的Hadoop集群状态,地址为:http://192.168.1.50:8088/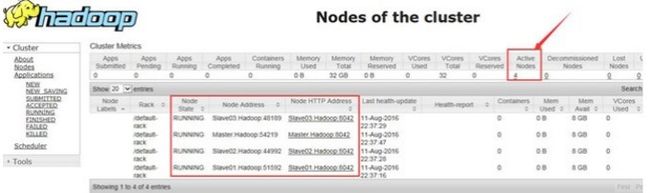 可见当前的Hadoop集群已经存在四个正在运行的节点。
可见当前的Hadoop集群已经存在四个正在运行的节点。