如何快速搭建hadoop大数据平台
前言
最近有朋友问起,怎么样快速搭建一个hadoop大数据平台,大家都知道,hadoop最核心的无非是HDFS和MapRedure, Java并发编程框架中的Fork/join 有点类似MapReudre,下面我们快速讲解一下如何搭建一个hadoop平台,
前期准备
搭建一个hadoop集群,首先我们按三台服务器的规模来计算。需要准备如下条件
- 三台Centos服务器
- hadoop压缩包 hadoop-3.1.1.tag.gz
- jdk安装包jdk-8u181-linux-x64.tar.gz,每台linux服务器必须安装
三台服务器可以是虚拟机环境。其中一台做master,另两台做slave分别为节点Node1,Node2。
安装jdk
在 master 中新建目录 /opt/bigdata/, 此目录下存放 hadoop 大数据所需要的环境包(jdk和hadoop).
- 第一步
把下载好的jdk-8u181-linux-x64.tar.gz包和hadoop-3.0.0.tag.gz上传至master主机中,JDK是安装Hadoop的基础环境,所以需要优先安装好JDK环境(最好把包考到opt目录下下) - 第二步
解压 JDK 并配置环境变量
tar -zxvf jdk-8u181-linux-x64.tar.gz
mv jdk1.8.0_181/ bigdata/
-
第三步
配置环境变量,vi /etc/profile, 如下图

-
第四步
验证环境是否配置成功 java -version 如下图
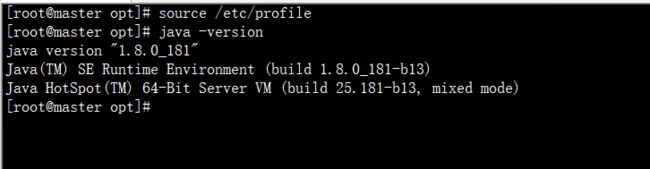
显示了如上图的版本号,则说明jdk已经安装成功了
服务器配置设置
1、把三台虚拟机服务器中的主机名分别更改为master、node1、node2。
命令如下
cd /etc/ // 进入配置目录
vi hostname // 编程hostname 配置文件
输入master,如下图,接着按ESC 输入:wq 退出并保存

在另外两个节点上进行相同的操作,输入node1,node2 分别如下图
![]()
![]()
2、开启主机的DHCP模式,自动获取ip地址。方法如下
cd /etc/sysconfig/network-scripts/ //进入网卡编辑目录 vi
ifcfg-enp16777736 //编辑网卡enp0s3的配置文件
3、最后重启网卡 service network restart


4、三台服务器的ip都记一下
命令为 ip a 或ifconfig
5、配置hosts
hosts文件是域名解析文件,在hosts文件内配置了 ip地址和主机名的对应关系,配置之后,通过主机名,电脑就可以定位到相应的ip地址 ,命令如下
vi /etc/hosts
在hosts配置文件内容输入如下内容:使用同样的方式更改node1和node2的网卡配置。

6、设置ssh 免密登录
ssh 一路回车
ssh-keygen
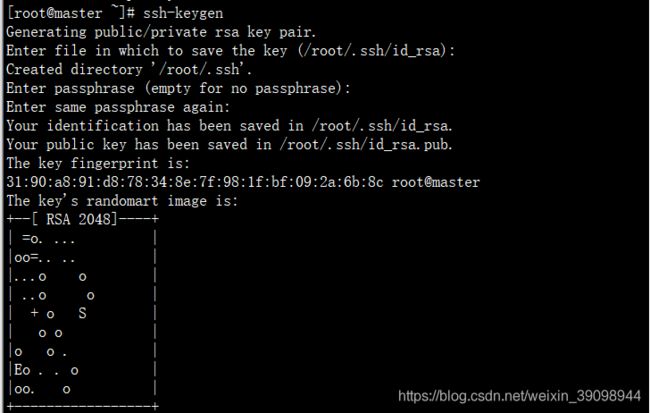
使用如下命令将公钥复制要node1和node2节点中:
ssh-copy-id root@node1
ssh-copy-id root@localhost
ssh-copy-id root@node2
使用 ssh node1 实验是否能免密登录
注意:ssh免密设置后会在如下目录生成四个文件

hadoop的安装
在上面的环境准备好以后,就可以安装hadoop了,
1、把 hadoop 的压缩包上传到 bigdata 目录下解压
tar -zxvf hadoop-3.1.1.tar.gz
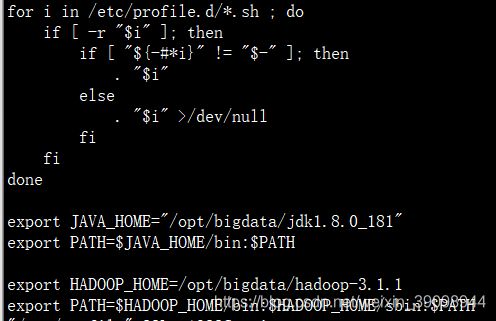
配置 hadoop 环境变量
注:环境变量是让系统变量,在环境变量配置的命令目录后,该目录的命令将可以在任何位置都可以使用。 如下图
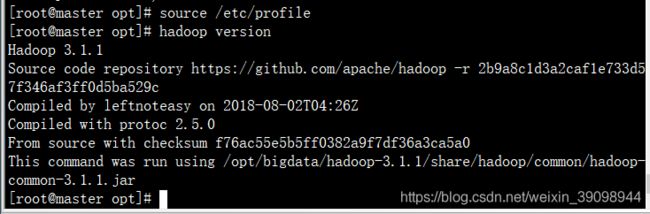
输入如下命令验证是否成功
hadoop verison
出现版本号,说明成功了,如图
hadoop的配置
对hadoop进行配置,先进入cd /opt/bigdata/hadoop-3.1.1/etc/hadoop/目录,我们需要对 core-site.xml、hadoop-env.sh、hdfs-site.xml、mapred-site.xml进行配置,下面一一列举
1、配置 hadoop-env.sh
编辑hadoop-env.sh文件。
命令如下:
vi hadopp-env.sh
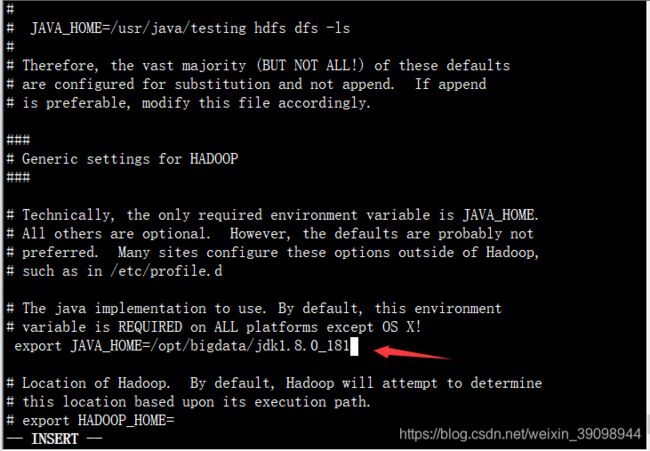
查找JAVA_HOME 配置的位置
:/export JAVA_HOME
输入JAVA_HOME的绝对路径。
export JAVA_HOME=/opt/bigdata/jdk1.8.0_181 (要把前面的注释#去掉)
2、配置core-site.xml
编辑core-site.xml文件。
vi core-site.xml
进入core-site.xml文件中结构如下所示,找到configuration的位置

<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.temp.dir</name>
<value>/opt/bigdata/hadoop-3.1.1/temp</value>
</property>
</configuration>
3、配置 hdfs-site.xml
vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.datanode.name.dir</name>
<value>/opt/bigdata/hadoop-3.1.1/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/bigdata/hadoop-3.1.1/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:9001</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0.50070</value>
</property>
</configuration>
4、配置mapred-site.xml
vi mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker.http.address</name>
<value>0.0.0.0:50030</value>
</property>
<property>
<name>mapred.task.tracker.http.address</name>
<value>0.0.0.0:50060</value>
</property>
</property>
</value>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/opt/bigdata/hadoop-3.1.1/etc/hadoop,
/opt/bigdata/hadoop-3.1.1/share/hadoop/common/*,
/opt/bigdata/hadoop-3.1.1/share/hadoop/common/lib/*,
/opt/bigdata/hadoop-3.1.1/share/hadoop/hdfs/*,
/opt/bigdata/hadoop-3.1.1/share/hadoop/hdfs/lib/*,
/opt/bigdata/hadoop-3.1.1/share/hadoop/mapreduce/*,
/opt/bigdata/hadoop-3.1.1/share/hadoop/mapreduce/lib/*,
/opt/bigdata/hadoop-3.1.1/share/hadoop/yarn/*,
/opt/bigdata/hadoop-3.1.1/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
5、配置yarn-sit.xml
vi yarn-sit.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8099</value>
</property>
6、配置workers
此处因为前面配置了hosts,所以此处可以直接写主机名,如果没有配置,必须输入相应主机的ip地址。配置的workers,hadoop会把配置在这里的主机当作datanode。
node1
node2
7、hadoop复制到其他host
把hadoop复制到所有datanode节点,此处是node1和node2。
命令如下:
scp -r * node1:/opt/
scp -r * node2:/opt/
8、启动
starta-all.sh 启动
写在最后
搭建hadoop集群其实并不复杂,关键是在于其应用,怎么通过数据挖掘和数据分析到达BI的目的,让领导层进行决策,要从海量的数据库中提取到有用的数据,分析出用户的行为习惯,从而开发出更有用的产品,这个涉及到数据算法的领域。
总之,收集数据容易,利用数据难
参考文献:
https://blog.csdn.net/a458383896/article/details/82876411
https://blog.csdn.net/fanxin_i/article/details/80425461
想了解更多的知识,请关注我吧_