莫烦 python教程学习笔记————搭建自己的神经网络
最近看了莫烦大神的教程,看到了搭建自己的神经网络,莫烦大神的视频还是很好的就是不太适合纯新手,这里我就把大神的代码拿出来分析一下好了
首先,我们应该先建立一个数据集,最后让我们自己神经网络去学习,绘制一条和数据集差不多的函数,我们先来绘制数据点图
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
x_data = np.linspace(-1,1,300)[:,None]
#生成原始X的数据,使用np.linspace()函数并将生成的数变成列的结构
#np.linspace(start,stop,num) 就是从-1到1之间生成300个数
#np.newaxis=none [:,None]是为多维数组增加一个轴 例:array([0,1])[:,None]输出:array([[0],
# [1])
noise = np.random.normal(0,0.05, x_data.shape)
#加入噪点
y_data = np.square(x_data)-0.05 + noise
#设定y的值
fig = plt.figure()
#调用画布
ax = fig.add_subplot(1,1,1)
#将画布分割,这里是将分割成一行一列且在第一块,也就是使用整个画布
#若是fig.add_subplot(2,2,4)就是分割成两行两列,在第4块
ax.scatter(x_data, y_data)
#将原始数据传入图中
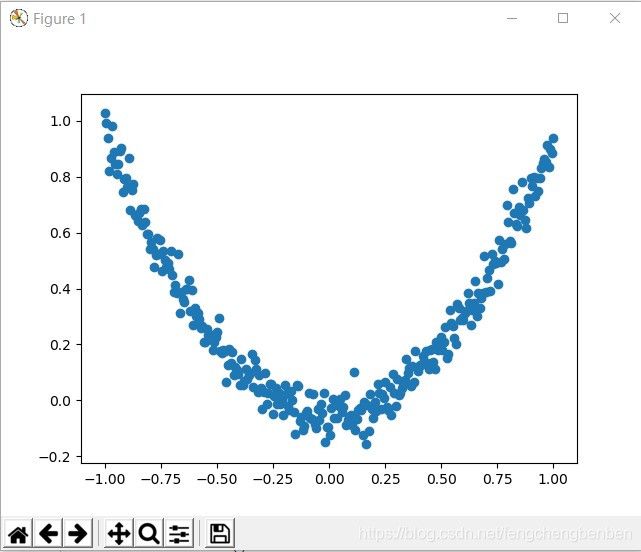
plt.show()上面的代码运行后会得出这样的图来,可能你的和我的会不一样,没问题的,因为这都是随机生成的数字,但是形状是差不多的
这是我的图
接下来就要添加我们的神经层了,添入神经层后的整体代码如下:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
"""
先增加隐藏层
参数:
inputs:输入的数据 in_size:输入数据的格式维度、out_size:输出数据的维度、actviation:激活函数,初始为零
"""
def add_lay(inputs, in_size, out_size, actviation_function = None):
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
# 权重用tf.random_norma()产生一个服从正态分布的随机矩阵,in_size行out_size列
biases = tf.Variable(tf.zeros([1,out_size])+0.1)
# 偏重,设置成1行out_size列的一个矩阵并加0.1,因为这个不能等于零
# tf.zeros()函数是产生一个全是零的矩阵
Wx_plus_b = tf.matmul(inputs, Weights)+ biases
if actviation_function is None:
output = Wx_plus_b
else:
output = actviation_function(Wx_plus_b)
return output
x_data = np.linspace(-1,1,300)[:,None]
#生成原始X的数据,使用np.linspace()函数并将生成的数变成列的结构
#np.linspace(start,stop,num) 就是从-1到1之间生成300个数
#np.newaxis=none [:,None]是为多维数组增加一个轴 例:array([0,1])[:,None]输出:array([[0],
# [1])
noise = np.random.normal(0,0.05, x_data.shape)
#加入噪点
y_data = np.square(x_data)-0.05 + noise
#设定y的值
xs = tf.placeholder(tf.float32,[None,1])
ys = tf.placeholder(tf.float32,[None,1])
l1 = add_lay(xs,1,10,actviation_function=tf.nn.relu)
#传入x_data,将输入值输入,然后用tf.nn.relu这个激活函数进行训练
prediction = add_lay(l1,10,1,actviation_function=None)
#预测函数,调用add_lay,将上一步的结果输入到函数中,不调用激活函数,得出刚才的预测值
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction), reduction_indices= [1]))
#计算损失使用均方误差
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
#训练,使用梯度下降,学习效率为0.1,最小化loss
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
#这里是将变量初始化
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.scatter(x_data,y_data)
plt.ion()
#使matplotlib的显示模式转换为交互(interactive)模式。即使在脚本中遇到plt.show(),代码还是会继续执行
plt.show()
for i in range(1000):
sess.run(train_step,feed_dict={xs:x_data, ys:y_data})
#运行train_step,并且将x_data,y_data的值传入进去
#feed_dict()作用就是给placeholder传值,将x_data的值传给xs,y_data传给ys
if i %50==0:
#没训练50次,绘制一次
try:
ax.lines.remove(lines[0])
except Exception:
pass
#上面这一段是在程序开始之前先绘制一次,为了避免报错,将错误强制pass
prediction_value = sess.run(prediction, feed_dict={xs:x_data})
#进行预测,并将x_data的值传入
lines = ax.plot(x_data,prediction_value,'r',lw=5)
#绘制曲线,数据是x_data,和y的预测值,颜色是红色,线宽=5
plt.pause(0.1)
#暂停0.1秒这里做一下讲解,我刚开始对于这个神经网络的运行方式很是纳闷,他究竟是怎么进行运行的,于是,我就拆分下来,一步一步的进行运行,发现,如果train_step如果不运行的话,prediction这个预测值就是最初的值,不会进行更新
于是,我去查了下GradientDescentOptimizer这个函数,发现他返回的是一个操作,对损失函数中的变量的值进行修改
默认修改var_list=[w,b],梯度下降就是找函数的斜率的相反方向走的,修改w和b两个值,只有修改w才会有反应,w在函数中代表着斜率