莫烦python系列教程 Scikit-Learn 轻松使用机器学习笔记
Scikit-Learn 轻松使用机器学习
莫烦python Scikit-Learn 轻松使用机器学习 官网地址
>>选择学习方法
-
Sklearn 官网提供了一个 流程图, 蓝色圆圈内是判断条件,绿色方框内是可以选择的算法:
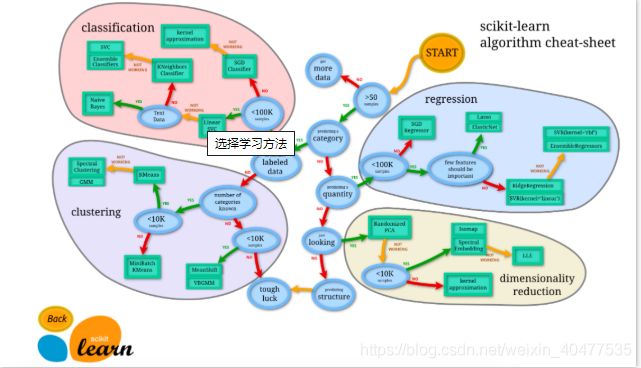
-
从 START 开始,首先看数据的样本是否 >50,小于则需要收集更多的数据。
-
由图中,可以看到算法有四类,分类,回归,聚类,降维。
-
其中 分类和回归是监督式学习,即每个数据对应一个 label。 聚类 是非监督式学习,即没有 label。 另外一类是 降维,当数据集有很多很多属性的时候,可以通过 降维 算法把属性归纳起来。例如 20 个属性只变成 2 个,注意,这不是挑出 2 个,而是压缩成为 2 个,它们集合了 20 个属性的所有特征,相当于把重要的信息提取的更好,不重要的信息就不要了。
>>通用机器学习
from sklearn import datasets #数据集
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import pandas as pd
# 1. 加载数据
iris= datasets.load_iris()
# iris_X, iris_y= iris.data, iris.target
iris_X, iris_y= pd.DataFrame(iris.data), pd.DataFrame(iris.target)
# 2. 将数据切分为 训练数据 验证数据
X_train, X_test, y_train, y_test = train_test_split(iris_X, iris_y, test_size=0.3)
# 3. 定义模型
knn= KNeighborsClassifier() # knn 模型
# 4. fit 训练
knn.fit(X_train, y_train) # 训练
# 5. 模型预测
pre_x=pd.DataFrame(knn.predict(X_test)) # 预测
pre_x.index = y_test.index
y_test["pre"] = pre_x[0]
y_test.T
| 116 | 0 | 9 | 15 | 43 | 70 | 124 | 137 | 90 | 91 | ... | 129 | 19 | 105 | 40 | 33 | 144 | 35 | 10 | 98 | 126 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 0 | 0 | 0 | 0 | 1 | 2 | 2 | 1 | 1 | ... | 2 | 0 | 2 | 0 | 0 | 2 | 0 | 0 | 1 | 2 |
| pre | 2 | 0 | 0 | 0 | 0 | 1 | 2 | 2 | 1 | 1 | ... | 2 | 0 | 2 | 0 | 0 | 2 | 0 | 0 | 1 | 2 |
>>sklearn 强大数据库
- 可以生成虚拟的数据,例如用来训练线性回归模型的数据,可以用函数来生成。
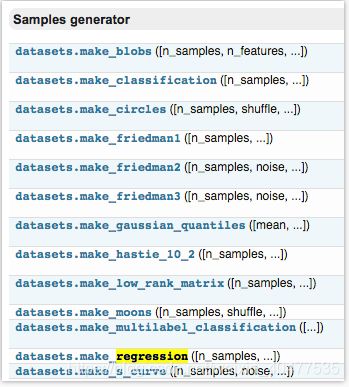
- 按照函数的形式,输入 sample,feature,target 的个数等等
sklearn.datasets.make_regression(n_samples=100, n_features=100, n_informative=10, n_targets=1, bias=0.0, effective_rank=None, tail_strength=0.5, noise=0.0, shuffle=True, coef=False,
from sklearn import datasets
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
# 导入数据
loaded_data = datasets.load_boston()
data_X, data_y = loaded_data.data, loaded_data.target
# 定义模型
model = LinearRegression()
# 训练模型
model.fit(data_X, data_y)
# 预测
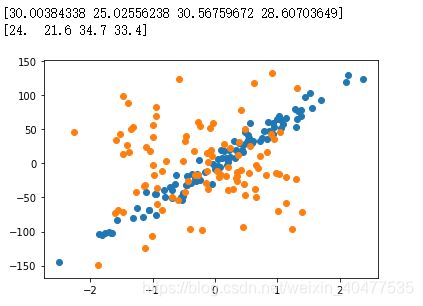
print(model.predict(data_X[:4,:]))
print(data_y[:4])
# 创建虚拟数据
X, y = datasets.make_regression(n_samples=100, n_features=1, n_targets=1, noise=10)
X_50, y_50 = datasets.make_regression(n_samples=100, n_features=1, n_targets=1, noise=50)
plt.scatter(X, y) # noise 10
plt.scatter(X_50, y_50) # noise 50
plt.show()
>>sklearn 常用属性与功能
model.fit() , model.predict()
# 首先导入包,数据, 还有模型
from sklearn import datasets
from sklearn.linear_model import LinearRegression
loaded_data = datasets.load_boston()
data_X = loaded_data.data
data_y = loaded_data.target
model = LinearRegression()
#用来训练模型,用训练好的模型预测。
# model.fit model.predict 属于模型的功能
model.fit(data_X, data_y) #训练
print(model.predict(data_X[:4,:])) #预测
'''
[30.00384338 25.02556238 30.56759672 28.60703649]
'''
model.coef_ , model.intercept_
# Model(LinearRegressor)的属性 model.coef_ 和 model.intercept_
print(model.coef_) # 输出模型的斜率
print(model.intercept_) # 输出模型的截距
'''
[-1.08011358e-01 4.64204584e-02 2.05586264e-02 2.68673382e+00
-1.77666112e+01 3.80986521e+00 6.92224640e-04 -1.47556685e+00
3.06049479e-01 -1.23345939e-02 -9.52747232e-01 9.31168327e-03
-5.24758378e-01]
36.459488385089855
'''
model.get_params()
# model.get_params() 也是功能
print(model.get_params()) #取出之前定义的参数。
'''
{'copy_X': True, 'fit_intercept': True, 'n_jobs': None, 'normalize': False}
'''
model.score()
# model.score(data_X, data_y)
# 它可以对 Model 用 R^2 的方式进行打分,输出精确度
print(model.score(data_X, data_y))
'''
0.7406426641094095
'''
>>正规化 Normalization
- 由于资料的偏差与跨度会影响机器学习的成效,因此正规化(标准化)数据可以提升机器学习的成效
标准化数据模块
# 数据标准化
from sklearn import preprocessing # 标准化数据模块
import numpy as np
# 建立Array
a = np.array([[10, 2.7, 3.6],
[-100, 5, -2],
[120, 20, 40]], dtype=np.float64)
# 将normalized后的a打印出
print(preprocessing.scale(a))
'''
[[ 0. -0.85170713 -0.55138018]
[-1.22474487 -0.55187146 -0.852133 ]
[ 1.22474487 1.40357859 1.40351318]]
'''
# 数据标准化对机器学习成效的影响
from sklearn import preprocessing
import numpy as np
# 将资料分割成train与test的模块
from sklearn.model_selection import train_test_split
# 生成适合做classification资料的模块
from sklearn.datasets.samples_generator import make_classification
# Support Vector Machine中的Support Vector Classifier
from sklearn.svm import SVC
# 可视化数据的模块
import matplotlib.pyplot as plt
生成数据
# 生成具有2种属性的300笔数据
X, y = make_classification(
n_samples=300, n_features=2,
n_redundant=0, n_informative=2,
random_state=22, n_clusters_per_class=1,
scale=100)
# 可视化数据
plt.scatter(X[:,0], X[:,1], c=y)
plt.show()
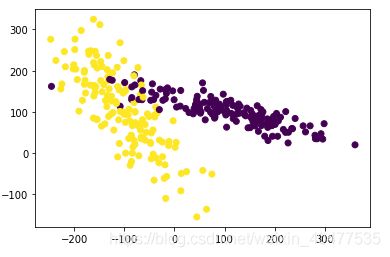
标准化前
# 标准化前的预测准确率
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
clf = SVC()
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
'''
0.4888888888888889
'''
标准化后
# 数据标准化后
X = preprocessing.scale(X)
plt.scatter(X[:,0], X[:,1], c=y)
plt.show()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
clf = SVC()
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
'''
0.9555555555555556
'''
>>检验神经网络(Evaluation)
- 在神经网络的训练当中, 神经网络可能会因为各种各样的问题, 出现学习的效率不高, 或者是因为干扰太多, 学到最后并没有很好的学到规律 . 而这其中的原因可能是多方面的, 可能是数据问题, 学习效率 等参数问题.
- 为了检验,评价神经网络, 避免和改善这些问题, 我们通常会把收集到的数据分为训练数据 和 测试数据, 一般用于训练的数据可以是所有数据的70%, 剩下的30%可以拿来测试学习结果.

- 对于神经网络的评价基本上是基于这30%的测试数据.评价机器学习可以从误差这个值开始, 随着训练时间的变长, 优秀的神经网络能预测到更为精准的答案, 预测误差也会越少 . 到最后能够提升的空间变小, 曲线也趋于水平 ,如果你的机器学习的误差曲线是这样一条曲线, 那就已经是很不错的学习成果啦.
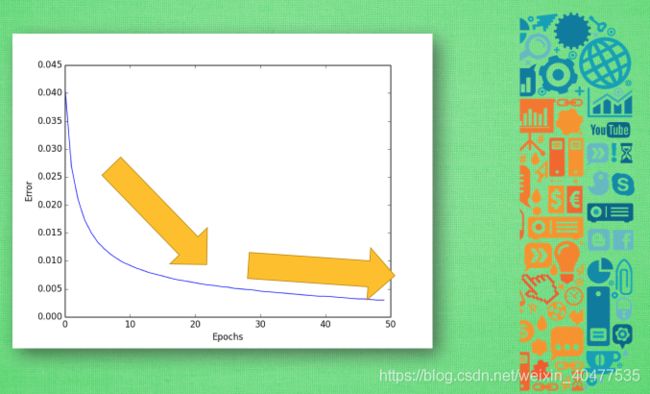
- 除了误差曲线, 我们可以看他的精确度曲线. 最好的精度是趋向于100%精确. 比如在神经网络的分类问题中, 100个样本中, 我有90张样本分类正确, 那就是说我的预测精确度是90%.
>>交叉验证
- Sklearn 中的 Cross Validation (交叉验证)对于我们选择正确的 Model 和 Model 的参数是非常有帮助的, 有了他的帮助,我们能直观的看出不同 Model 或者参数对结构准确度的影响。
交叉验证1 Cross-validation
# Model 基础验证法
from sklearn.datasets import load_iris # iris数据集
from sklearn.model_selection import train_test_split # 分割数据模块
from sklearn.neighbors import KNeighborsClassifier # K最近邻分类算法
# 加载iris 数据集
iris = load_iris()
X = iris.data
y = iris.target
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=4)
# 建立模型
knn = KNeighborsClassifier()
# 训练模型
knn.fit(X_train, y_train)
# 预测分数
print(knn.score(X_test, y_test))
'''
0.973684210526
'''
可以看到基础验证的准确率为 0.973684210526
from sklearn.model_selection import cross_val_score # K折交叉验证模块
# 加载iris 数据集
iris = load_iris()
X = iris.data
y = iris.target
# 建立模型
knn = KNeighborsClassifier()
# 使用K折交叉验证模块
scores = cross_val_score(knn, X, y, cv=5, scoring="accuracy")
# 将5次的预测准确率打印出
print(scores)
# 将5次的预测准确平均率打印出
print(scores.mean())
'''
[0.96666667 1. 0.93333333 0.96666667 1. ]
0.9733333333333334
'''
可以看到交叉验证的准确平均率为 0.973333333333
# 一般来说准确率(accuracy)会用于判断分类(Classification)模型的好坏。
import matplotlib.pyplot as plt
# 建立测试参数集
k_range = range(1, 31)
k_scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knn, X, y, cv =10, scoring="accuracy")
k_scores.append(scores.mean())
# 可视化数据
plt.plot(k_range, k_scores)
plt.xlabel("Value of K for KNN")
plt.ylabel("Cross-Validated Accuracy")
plt.show()
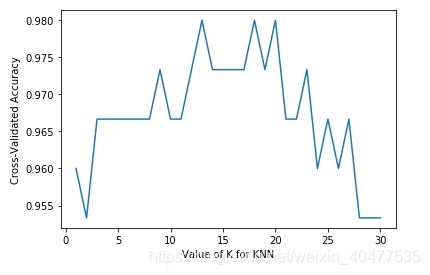
从图中可以得知,选择 12~18的k值最好。高过18之后,准确率开始下降则是因为过拟合(Over fitting)的问题。
# 一般来说**平均方差**(Mean squared error)会用于判断回归(Regression)模型的好坏。
import matplotlib.pyplot as plt
k_range = range(1, 31)
k_scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
loss = -cross_val_score(knn, X, y, cv=10, scoring='neg_mean_squared_error')
k_scores.append(loss.mean())
plt.plot(k_range, k_scores)
plt.xlabel('Value of K for KNN')
plt.ylabel('Cross-Validated MSE')
plt.show()
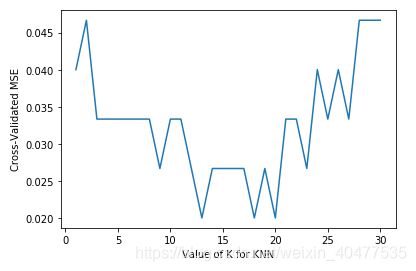
平均方差越低越好,因此选择 13~18左右的K值会最好
交叉验证 2 Cross-validation
- sklearn.learning_curve 中的 learning curve 可以很直观的看出我们的 model 学习的进度, 对比发现有没有 overfitting 的问题. 然后我们可以对我们的 model 进行调整, 克服 overfitting 的问题.
# Learning curve 检视过拟合
# 加载对应模块
from sklearn.model_selection import learning_curve # 学习曲线
from sklearn.datasets import load_digits #加载digits数据集,其包含的是手写体的数字,从0到9
from sklearn.svm import SVC # Support Vector Classifier
import matplotlib.pyplot as plt
import numpy as np
digits = load_digits()
X = digits.data
y = digits.target
# 观察样本由小到大的学习曲线变化,
# 采用K折交叉验证 cv=10,
# 选择平均方差检视模型效能 scoring='neg_mean_squared_error',
# 样本由小到大分成5轮检视学习曲线(10%, 25%, 50%, 75%, 100%):
train_sizes, train_loss, test_loss = learning_curve(
SVC(gamma=0.001), X, y, cv=10, scoring="neg_mean_squared_error",
train_sizes=[0.1, 0.25, 0.5, 0.75, 1])
print(train_sizes.shape)
#平均每一轮所得到的平均方差(共5轮,分别为样本10%、25%、50%、75%、100%)
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)
# 可视化图形
plt.plot(train_sizes, train_loss_mean, 'o-', color="r",
label="Training")
plt.plot(train_sizes, test_loss_mean, 'o-', color="g",
label="Cross-validation")
plt.xlabel("Training examples")
plt.ylabel("Loss")
plt.legend(loc="best")
plt.show()
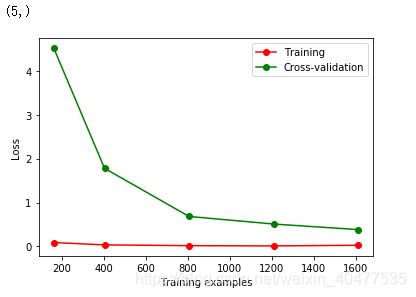
交叉验证 3 Cross-validation
- 这一次的 sklearn 中我们用到了sklearn.learning_curve当中的另外一种, 叫做validation_curve,用这一种曲线我们就能更加直观看出改变模型中的参数的时候有没有过拟合(overfitting)的问题了. 这也是可以让我们更好的选择参数的方法.
# validation_curve 检视过拟合
from sklearn.model_selection import validation_curve #validation_curve模块
from sklearn.datasets import load_digits
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
# digits数据集
digits = load_digits()
X, y = digits.data, digits.target
# 建立参数测试集
param_range = np.logspace(-6, -2.3, 5)
# 使用validation_curve快速找出参数对模型的影响
train_loss, test_loss = validation_curve(
SVC(), X, y, param_name="gamma", param_range=param_range,
cv=10, scoring="neg_mean_squared_error")
# 平均每一轮的平均方差
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_maen = -np.mean(test_loss, axis=1)
# 可视化图形
plt.plot(param_range, train_loss_mean, "o-", color="r", label="Training")
plt.plot(param_range, test_loss_mean, "o-", color="g", label="Cross-validation")
plt.xlabel("gamma")
plt.ylabel("Loss")
plt.legend()
plt.show()
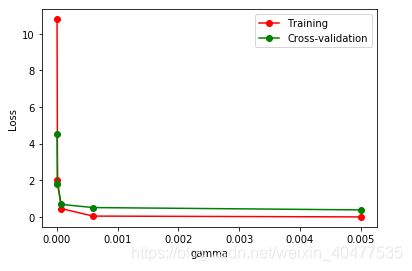
由图中可以明显看到 gamma值大于0.001,模型就会有过拟合(Overfitting)的问题
>>保存模型
- 训练好了一个Model 以后总需要保存和再次预测, 所以保存和读取我们的sklearn model也是同样重要的一步。这次主要介绍两种保存Model的模块pickle与joblib。
pickle
# 使用 pickle 保存
# 首先简单建立与训练一个SVCModel
from sklearn import svm
from sklearn import datasets
clf = svm.SVC()
iris = datasets.load_iris()
X, y = iris.data, iris.target
clf.fit(X,y)
'''
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto_deprecated',
kernel='rbf', max_iter=-1, probability=False, random_state=None,
shrinking=True, tol=0.001, verbose=False)
'''
# 使用pickle来保存与读取训练好的Model。
import pickle
# 保存Model(注: model文件夹要预先建立, 否侧会报错)
with open("model/clf.pickle", 'wb') as f:
pickle.dump(clf, f)
print("save model done")
# 读取model
with open("model/clf.pickle", "rb") as f:
clf2 = pickle.load(f)
# 测试读取后的Model
print(clf2.predict(X[0:1]))
'''
[0]
'''
joblib
# 使用 joblib 保存 joblib是sklearn的外部模块。
from sklearn.externals import joblib
# 保存Model(注:model文件夹预先建立,否则会报错
joblib.dump(clf, "model/clf.pkl")
# 读取Model
clf3 = joblib.load("model/clf.pkl")
# 测试读取后的Model
print(clf.predict(X[0:1]))
'''
[0]
'''
可以知道joblib在使用上比较容易,读取速度也相对pickle快.
=======================================================================