预训练语言模型
『预训练语言模型分类 』
单向特征、自回归模型(单向模型):
ELMO/ULMFiT/SiATL/GPT1.0/GPT2.0
双向特征、自编码模型(BERT系列模型):
BERT/ERNIE/SpanBERT/RoBERTa
双向特征、自回归模型“
XLNet
『各模型之间的联系 』
传统word2vec无法解决一词多义,语义信息不够丰富,诞生了ELMO
ELMO以lstm堆积,串行且提取特征能力不够,诞生了GPT
GPT 虽然用transformer堆积,但是是单向的,诞生了BERT
BERT虽然双向,但是mask不适用于自编码模型,诞生了XLNET
BERT中mask代替单个字符而非实体或短语,没有考虑词法结构/语法结构,诞生了ERNIE
为了mask掉中文的词而非字,让BERT更好的应用在中文任务,诞生了BERT-wwm
Bert训练用更多的数据、训练步数、更大的批次,mask机制变为动态的,诞生了RoBERTa
ERNIE的基础上,用大量数据和先验知识,进行多任务的持续学习,诞生了ERNIE2.0
BERT-wwm增加了训练数据集、训练步数,诞生了BERT-wwm-ext
BERT的其他改进模型基本考增加参数和训练数据,考虑轻量化之后,诞生了ALBERT
「 1.ELMO 」
“Embedding from Language Models"
NAACL18 Best Paper
传统word2vec无法解决一词多义,语义信息不够丰富,诞生了ELMO
ELMO以lstm堆积,串行且提取特征能力不够,诞生了GPT
特点:传统的词向量(如word2vec)是静态的/上下文无关的,而ELMO解决了一词多义;ELMO采用双层双向LSTM
缺点:lstm是串行,训练时间长;相比于transformer,特征提取能力不够(ELMO采用向量拼接)
使用分为两阶段:预训练+应用于下游任务,本质就是根据当前上下文对Word Embedding进行动态调整的过程:
-
用语言模型进行预训练
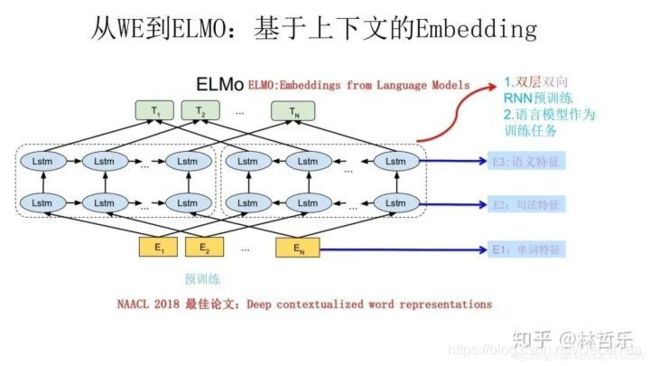
左边的前向双层LSTM是正方向编码器,顺序输入待预测单词w的上文;右边则是反方向编码器,逆序输入w的下文 -
训练好之后,输入一个新句子s,每个单词都得到三个Embedding:1)单词的Word Embedding 2)第一层关于单词位置的Embedding 3)第二层带有语义信息的Embedding(上述的三个Embedding 、LSTM网络结果均为训练结果)
-
做下游任务时,从预训练网络中提取对应单词的网络各层的Word Embedding作为新特征补充到下游任务中。 如QA任务:输入Q/A句子,对三个Embedding分配权重,整合生成新的Embedding
「 2.GPT 」
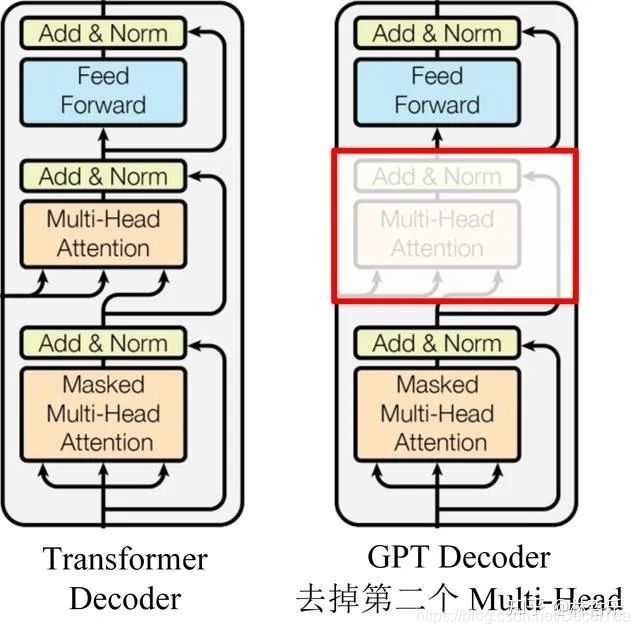
- 与ELMO的不同:
GPT只用了transformer的decoder模块提取特征,而不是Bi-LSTM;堆叠12个
单向(根据上文预测单词,利用mask屏蔽下文)
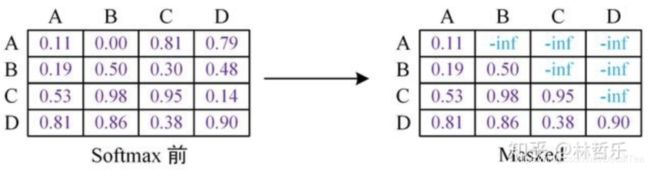
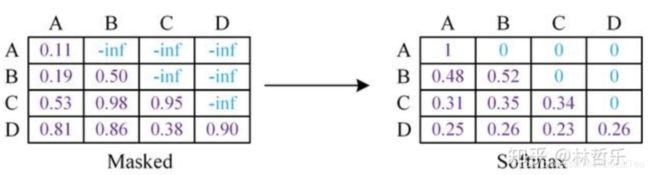
GPT中的mask如下图所示,mask之后要进行softmax:
- GPT依然分为两阶段:单向语言模型预训练(无监督)+fine tuning应用到下游任务(有监督)
第一阶段(预训练):
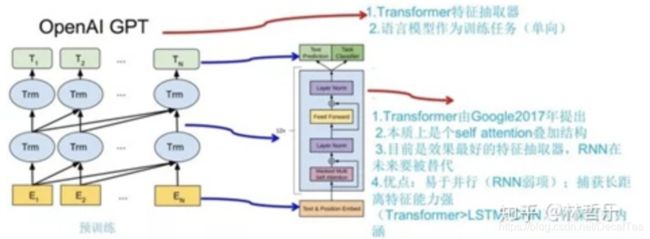
GPT的训练过程
第二阶段(应用于下游任务):
向GPT的网络结构看齐,把任务的网络结构改造成和 GPT的网络结构是一样的。做法如下:
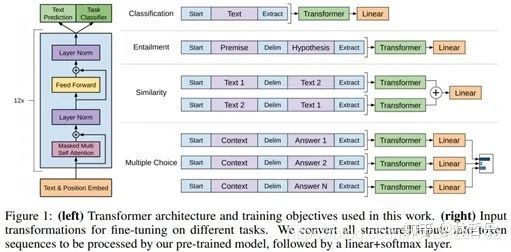
对于分类问题,不用怎么动,加上一个起始和终结符号即可;
对于句子关系判断问题,比如 Entailment,两个句子中间再加个分隔符即可;
对文本相似性判断问题,把两个句子顺序颠倒下做出两个输入即可,这是为了告诉模型句子顺序不重要;
对于多项选择问题,则多路输入,每一路把文章和答案选项拼接作为输入即可。从上图可看出,这种改造还是很方便的,不同任务只需要在输入部分施工即可。
效果:在 12 个任务里,9 个达到了最好的效果,有些任务性能提升非常明显。
「 3.BERT 」
-
1)与GPT的区别:
双向
用的是transformer的encoder(GPT用的是decoder,ELMO用的是Bi-LSTM)
多任务学习方式训练:预测目标词和预测下一句
优点:效果好、普适性强、效果提升大
缺点:硬件资源的消耗巨大、训练时间长;预训练用了[MASK]标志,影响微调时模型表现 -
2)预训练:
- Embedding layer
三个Embedding 求和而得,分别是:
a.Token Embeddings:词向量,首单词是[CLS]标志,可用于分类任务
b.Segment Embeddings:用[SEP]标志将句子分为两段,因为预训练不光做LM还要做以两个句子为输入的分类任务
c.Position Embeddings:和之前文章中的Transformer不同,不是三角函数而是学习出来的
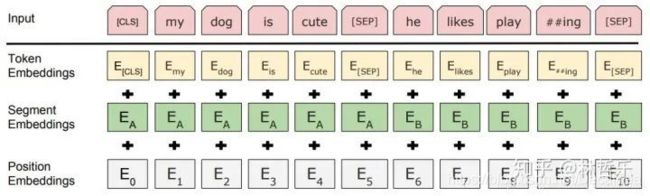
Question:BERT的输入和输出?
从上图中可以看出,BERT 模型通过查询字向量表将文本中的每个字转换为一维向量,作为模型输入。模型输出则是输入各字对应的融合全文语义信息后的向量表示。此外,模型输入除了字向量(英文中对应的是 Token Embeddings),还包含另外两个部分:
文本向量(英文中对应的是 Segment Embeddings):该向量的取值在模型训练过程中自动学习,用于刻画文本的全局语义信息,并与单字/词的语义信息相融合
位置向量(英文中对应的是 Position Embeddings):由于出现在文本不同位置的字/词所携带的语义信息存在差异(比如:“我爱你”和“你爱我”),因此,BERT 模型对不同位置的字/词分别附加一个不同的向量以作区分
最后,BERT 模型将字向量、文本向量和位置向量的加和作为模型输入。特别地,在目前的 BERT 模型中,文章作者还将英文词汇作进一步切割,划分为更细粒度的语义单位(WordPiece),例如:将 playing 分割为 play 和##ing;此外,对于中文,目前作者未对输入文本进行分词,而是直接将单字作为构成文本的基本单位。
需要注意的是,上图中只是简单介绍了单个句子输入 BERT 模型中的表示,实际上,在做 Next Sentence Prediction 任务时,在第一个句子的首部会加上一个[CLS] token,在两个句子中间以及最后一个句子的尾部会加上一个[SEP] token。
Question:BERT 的 embedding 向量如何得来的?
以中文为例,「BERT 模型通过查询字向量表将文本中的每个字转换为一维向量,作为模型输入(还有 position embedding 和 segment embedding);模型输出则是输入各字对应的融合全文语义信息后的向量表示。」
而对于输入的 token embedding、segment embedding、position embedding 都是随机生成的,需要注意的是在 Transformer 论文中的 position embedding 由 sin/cos 函数生成的固定的值,而在这里代码实现中是跟普通 word embedding 一样随机生成的,可以训练的。作者这里这样选择的原因可能是 BERT 训练的数据比 Transformer 那篇大很多,完全可以让模型自己去学习。
- 预测目标词Masked LM
随机挑选一个句子中15%的词,用上下文来预测。这15%中,80%用[mask]替换,10%随机取一个词替换,10%不变。用非监督学习的方法预测这些词。
这么做的主要原因是:在后续微调任务中语句中并不会出现 [MASK] 标记,而且这么做的另一个好处是:预测一个词汇时,模型并不知道输入对应位置的词汇是否为正确的词汇( 10% 概率),这就迫使模型更多地依赖于上下文信息去预测词汇,并且赋予了模型一定的纠错能力。上述提到了这样做的一个缺点,其实这样做还有另外一个缺点,就是每批次数据中只有 15% 的标记被预测,这意味着模型可能需要更多的预训练步骤来收敛。
Question:BERT 模型为什么要用 mask?它是如何做 mask 的?其 mask 相对于 CBOW 有什么异同点?
- 预测下一句 Next Sentence Prediction
选择句子对A+B,其中50%的B是A的下一句,50%为语料库中随机选取。
这个类似于「段落重排序」的任务,即:将一篇文章的各段打乱,让我们通过重新排序把原文还原出来,这其实需要我们对全文大意有充分、准确的理解。
Next Sentence Prediction 任务实际上就是段落重排序的简化版:只考虑两句话,判断是否是一篇文章中的前后句。在实际预训练过程中,文章作者从文本语料库中随机选择 50% 正确语句对和 50% 错误语句对进行训练,与 Masked LM 任务相结合,让模型能够更准确地刻画语句乃至篇章层面的语义信息。
BERT 模型通过对 Masked LM 任务和 Next Sentence Prediction 任务进行联合训练,使模型输出的每个字 / 词的向量表示都能尽可能全面、准确地刻画输入文本(单句或语句对)的整体信息,为后续的微调任务提供更好的模型参数初始值。
-
3)fine-tuning(应用于下游任务时微调):
-
BERT的微调(fine tuning)参考参数:
Batch Size:16 or 32
Learning Rate: 5e-5, 3e-5, 2e-5
Epochs:2, 3, 4 -
BERT 的 Fine-Tuning 共分为 4 中类型:
单句子分类任务
单句子标注任务
句子对分类任务
问答任务
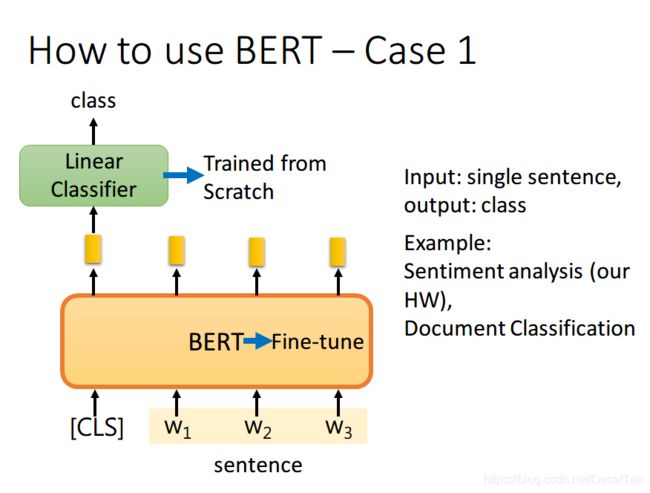
如果现在的任务是 classification,首先在输入句子的开头加一个代表分类的符号 [CLS],然后将该位置的 output,丢给 Linear Classifier,让其 predict 一个 class 即可。整个过程中 Linear Classifier 的参数是需要从头开始学习的,而 BERT 中的参数微调就可以了
这里李宏毅老师有一点没讲到,就是为什么要用第一个位置,即 [CLS] 位置的 output。这里我看了网上的一些博客,结合自己的理解解释一下。因为 BERT 内部是 Transformer,而 Transformer 内部又是 Self-Attention,所以 [CLS] 的 output 里面肯定含有整句话的完整信息,这是毋庸置疑的。但是 Self-Attention 向量中,自己和自己的值其实是占大头的,现在假设使用 的 output 做分类,那么这个 output 中实际上会更加看重 ,而 又是一个有实际意义的字或词,这样难免会影响到最终的结果。但是 [CLS] 是没有任何实际意义的,只是一个占位符而已,所以就算 [CLS] 的 output 中自己的值占大头也无所谓。当然你也可以将所有词的 output 进行 concat,作为最终的 output
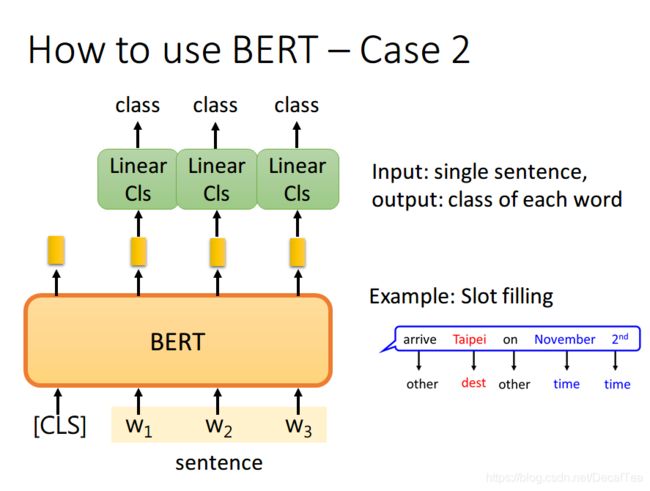
如果现在的任务是 Slot Filling,将句子中各个字对应位置的 output 分别送入不同的 Linear,预测出该字的标签。其实这本质上还是个分类问题,只不过是对每个字都要预测一个类别
如果现在的任务是 NLI(自然语言推理)。即给定一个前提,然后给出一个假设,模型要判断出这个假设是 正确、错误还是不知道。这本质上是一个三分类的问题,和 Case 1 差不多,对 [CLS] 的 output 进行预测即可

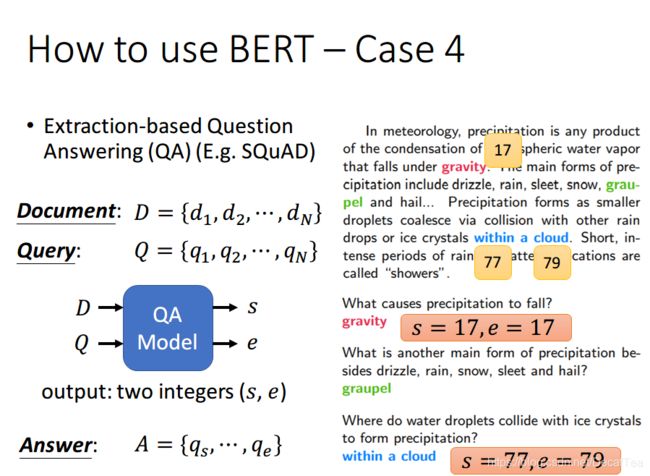
如果现在的任务是 QA(问答),举例来说,如上图,将一篇文章,和一个问题(这里的例子比较简单,答案一定会出现在文章中)送入模型中,模型会输出两个数 s,e,这两个数表示,这个问题的答案,落在文章的第 s 个词到第 e 个词。具体流程我们可以看下面这幅图
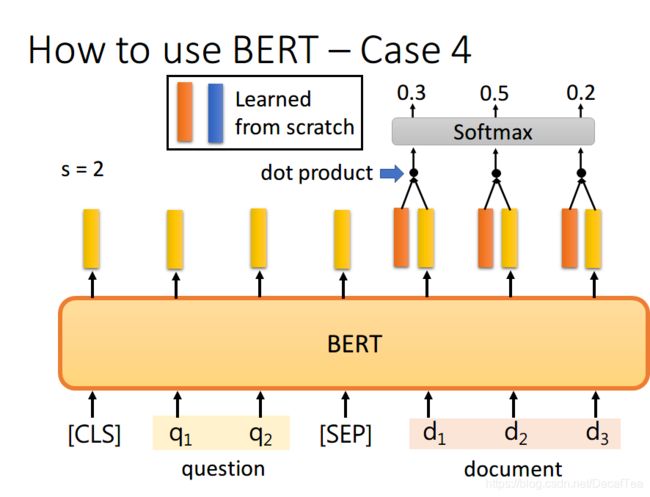
首先将问题和文章通过 [SEP] 分隔,送入 BERT 之后,得到上图中黄色的输出。此时我们还要训练两个 vector,即上图中橙色和蓝色的向量。首先将橙色和所有代表文章的黄色向量进行 dot product,然后通过 softmax,看哪一个输出的值最大,例如上图中 对应的输出概率最大,那我们就认为 s=2
同样地,我们用蓝色的向量和所有代表文章的黄色向量进行 dot product,最终预测得 d2 的概率最大,因此 e=3。最终,答案就是 s=2,e=3
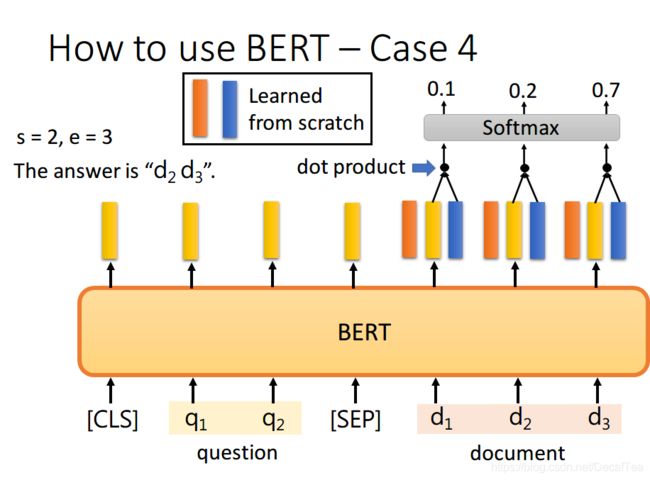
你可能会觉得这里面有个问题,假设最终的输出 s>e 怎么办,那不就矛盾了吗?其实在某些训练集里,有的问题就是没有答案的,因此此时的预测搞不好是对的,就是没有答案。
橙色的和蓝色的vector是由随机初始化从头学得的,用nn.linear()。
nn.linear() vs nn.embedding?
nn.linear() 和 nn.embedding() 都是一层神经网络的权重参数。
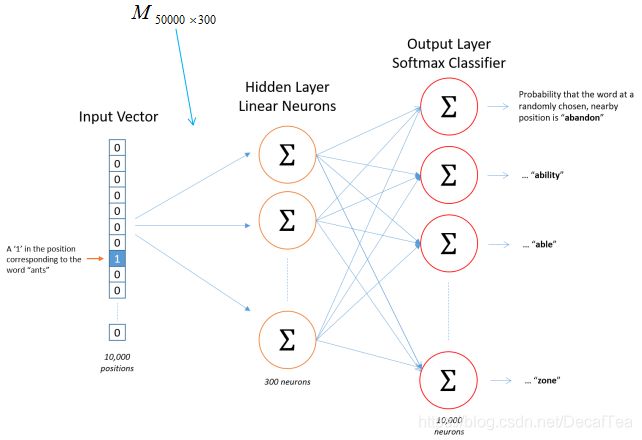
-
想要查看某个词的词向量,需要传入:
nn.linear():one-hot vector
nn.embedding():这个词在词典中的 index,torch.LongTensor type.
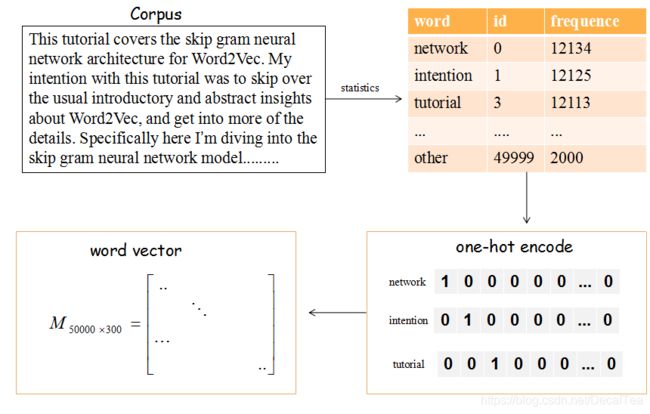
-
input and output:
embeds = nn.linear(100,10)
embeds = nn.Embedding(100, 10)
学得的权重维度都是 (num_embeddings, embedding_dim),默认是随机初始化的。
num_embeddings 表示单词的总数目,embedding_dim 表示每个单词需要用什么维度的向量表示。
要训练word embedding matrix,可以直接使用 nn.Linear(),只不过输入要改为 one-hot Encoding,而不能像 nn.Embedding() 这种方式直接传入一个 index。还有就是需要设置 bias=False,因为我们只需要训练一个权重矩阵,不训练偏置。
BERT中的词向量token embedding可以直接随机初始化,也可以使用用nn.linear() or nn.embedding() 来训练word2vec的预训练模型。
代码细节见:https://wmathor.com/index.php/archives/1435/
- 4)BERT 是怎么用 Transformer 的?

- 5)BERT 有什么局限性?
从 XLNet 论文中,提到了 BERT 的两个缺点,分别如下:
- BERT 在第一个预训练阶段,假设句子中多个单词被 Mask 掉,这些被 Mask 掉的单词之间没有任何关系,是条件独立的,然而有时候这些单词之间是有关系的,比如”New York is a city”,假设我们 Mask 住”New”和”York”两个词,那么给定”is a city”的条件下”New”和”York”并不独立,因为”New York”是一个实体,看到”New”则后面出现”York”的概率要比看到”Old”后面出现”York”概率要大得多。
但是需要注意的是,这个问题并不是什么大问题,甚至可以说对最后的结果并没有多大的影响,因为本身 BERT 预训练的语料就是海量的(动辄几十个 G),所以如果训练数据足够大,其实不靠当前这个例子,靠其它例子,也能弥补被 Mask 单词直接的相互关系问题,因为总有其它例子能够学会这些单词的相互依赖关系。
- **BERT 的在预训练时会出现特殊的[MASK],但是它在下游的 fine-tune 中不会出现,这就出现了预训练阶段和 fine-tune 阶段不一致的问题。**其实这个问题对最后结果产生多大的影响也是不够明确的,因为后续有许多 BERT 相关的预训练模型仍然保持了[MASK]标记,也取得了很大的结果,而且很多数据集上的结果也比 BERT 要好。但是确确实实引入[MASK]标记,也是为了构造自编码语言模型而采用的一种折中方式。
总结上述介绍的三种预训练语言模型:ELMO, GPT, BERT
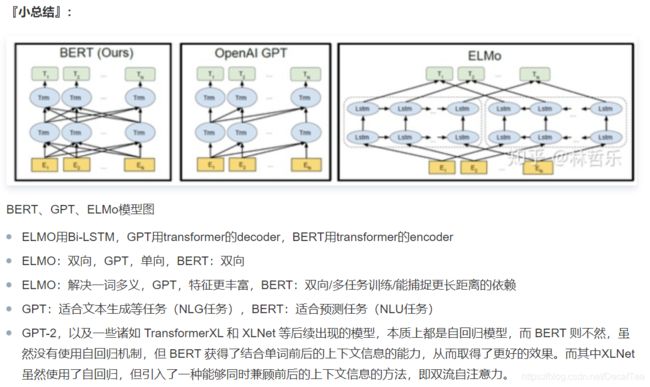
reference:
https://wmathor.com/index.php/archives/1435/
https://wmathor.com/index.php/archives/1456/
https://cloud.tencent.com/developer/article/1701172
https://mp.weixin.qq.com/s/E60wUHkHo-Gj3wb9Denuag
BERT的PyTorch实现:https://www.bilibili.com/video/BV11p4y1i7AN/?spm_id_from=333.788.videocard.4