全球人工智能技术创新大赛【热身赛一】布匹疵点智能识别(基于mmdetection)
全球人工智能技术创新大赛【热身赛一】布匹疵点智能识别(基于mmdetection的docker配置及上传)
之前用yolov5参考上传了一次,但是想到自己用的比较多的是mmdetection,所以打算用mmdetection配置一次,再次练习一下docker的使用,PS:这次我使用的是cascade_rcnn模型。
一、Docker CE 及 nvidia-docker2 安装
具体请参考大佬的文章,很详细的:Ubuntu 18.04安装Docker CE及nvidia-docker2流程
二、数据的转换(fabric2coco.py)
文件修改于 Fabric2COCO,这次比赛类别相比之前的20类变成了15类,此外我转换格式的过程中加入了train\val集的划分。具体代码如下:
'''
@bushou
'''
import os
import json
import numpy as np
import shutil
import pandas as pd
defect_name2label = {
'沾污': 0, '错花': 1, '水印': 2, '花毛': 3, '缝头': 4, '缝头印': 5, '虫粘': 6, '破洞': 7,
'褶子': 8, '织疵': 9, '漏印': 10, '蜡斑': 11, '色差': 12, '网折': 13, '其他': 14,
}
# defect_name2label = {
# '破洞': 1, '水渍': 2, '油渍': 3, '污渍': 4, '三丝': 5, '结头': 6, '花板跳': 7, '百脚': 8, '毛粒': 9,
# '粗经': 10, '松经': 11, '断经': 12, '吊经': 13, '粗维': 14, '纬缩': 15, '浆斑': 16, '整经结': 17, '星跳': 18, '跳花': 19,
# '断氨纶': 20, '稀密档': 21, '浪纹档': 22, '色差档': 23, '磨痕': 24, '轧痕': 25, '修痕': 26, '烧毛痕': 27, '死皱': 28, '云织': 29,
# '双纬': 30, '双经': 31, '跳纱': 32, '筘路': 33, '纬纱不良': 34,
# }
class Fabric2COCO:
def __init__(self):
self.train_images = []
self.train_annotations = []
self.val_images = []
self.val_annotations = []
self.categories = []
self.img_id = 0
self.ann_id = 0
if not os.path.exists("data/coco/{}".format('train2017')):
os.makedirs("data/coco/{}".format('train2017'))
if not os.path.exists("data/coco/{}".format('val2017')):
os.makedirs("data/coco/{}".format('val2017'))
def to_coco(self, anno_file, img_dir):
self._init_categories()
anno_result = pd.read_json(open(anno_file, "r"))
name_list = anno_result["name"].unique()
index = list(set(name_list))
print(index)
for fold in [0]:
val_index = index[len(index) * fold // 5:len(index) * (fold + 1) //5]
print(len(val_index))
for img_name in name_list:
if img_name in val_index:
img_anno = anno_result[anno_result["name"] == img_name]
bboxs = img_anno["bbox"].tolist()
defect_names = img_anno["defect_name"].tolist()
assert img_anno["name"].unique()[0] == img_name
img_defect = img_name.split('.')[0]
img_path = os.path.join(img_dir, img_defect, img_name)
# img =cv2.imread(img_path)
# h,w,c=img.shape
h, w = 1000, 2446
self.val_images.append(self._image(img_path, h, w))
self._cp_img(img_path, 'val2017')
for bbox, defect_name in zip(bboxs, defect_names):
label = defect_name2label[defect_name]
annotation = self._annotation(label, bbox)
self.val_annotations.append(annotation)
self.ann_id += 1
self.img_id += 1
else:
img_anno = anno_result[anno_result["name"] == img_name]
bboxs = img_anno["bbox"].tolist()
defect_names = img_anno["defect_name"].tolist()
assert img_anno["name"].unique()[0] == img_name
img_defect = img_name.split('.')[0]
img_path = os.path.join(img_dir, img_defect, img_name)
# img =cv2.imread(img_path)
# h,w,c=img.shape
h, w = 1000, 2446
self.train_images.append(self._image(img_path, h, w))
self._cp_img(img_path, 'train2017')
for bbox, defect_name in zip(bboxs, defect_names):
label = defect_name2label[defect_name]
annotation = self._annotation(label, bbox)
self.train_annotations.append(annotation)
self.ann_id += 1
self.img_id += 1
train_instance = {
}
train_instance['info'] = 'fabric defect'
train_instance['license'] = ['none']
train_instance['images'] = self.train_images
train_instance['annotations'] = self.train_annotations
train_instance['categories'] = self.categories
val_instance = {
}
val_instance['info'] = 'fabric defect'
val_instance['license'] = ['none']
val_instance['images'] = self.val_images
val_instance['annotations'] = self.val_annotations
val_instance['categories'] = self.categories
return train_instance, val_instance
def _init_categories(self):
# for v in range(1, 16):
# print(v)
# category = {}
# category['id'] = v
# category['name'] = str(v)
# category['supercategory'] = 'defect_name'
# self.categories.append(category)
for k, v in defect_name2label.items():
category = {
}
category['id'] = v + 1
category['name'] = k
category['supercategory'] = 'defect_name'
self.categories.append(category)
def _image(self, path, h, w):
image = {
}
image['height'] = h
image['width'] = w
image['id'] = self.img_id
image['file_name'] = os.path.basename(path)
return image
def _annotation(self, label, bbox):
area = (bbox[2]-bbox[0])*(bbox[3]-bbox[1])
points = [[bbox[0], bbox[1]], [bbox[2], bbox[1]], [bbox[2], bbox[3]], [bbox[0], bbox[3]]]
annotation = {
}
annotation['id'] = self.ann_id
annotation['image_id'] = self.img_id
annotation['category_id'] = label
annotation['segmentation'] = [np.asarray(points).flatten().tolist()]
annotation['bbox'] = self._get_box(points)
annotation['iscrowd'] = 0
annotation['area'] = area
return annotation
def _cp_img(self, img_path, mode):
shutil.copy(img_path, os.path.join("data/coco/{}".format(mode), os.path.basename(img_path)))
def _get_box(self, points):
min_x = min_y = np.inf
max_x = max_y = 0
for x, y in points:
min_x = min(min_x, x)
min_y = min(min_y, y)
max_x = max(max_x, x)
max_y = max(max_y, y)
'''coco,[x,y,w,h]'''
return [min_x, min_y, max_x - min_x, max_y - min_y]
def save_coco_json(self, instance, save_path):
import json
with open(save_path, 'w') as fp:
json.dump(instance, fp, indent=1, separators=(',', ': '))
if __name__ == '__main__':
'''转换有瑕疵的样本为coco格式'''
img_dir = "/home/yhh/workspace/datawhale/mmdetection/data/guangdong/guangdong1_round2_train2_20191004_images/defect"
anno_dir = "/home/yhh/workspace/datawhale/mmdetection/data/guangdong/guangdong1_round2_train2_20191004_Annotations/Annotations/anno_train.json"
fabric2coco = Fabric2COCO()
train_instance, val_instance = fabric2coco.to_coco(anno_dir, img_dir)
if not os.path.exists("data/coco/annotations/"):
os.makedirs("data/coco/annotations/")
fabric2coco.save_coco_json(train_instance, "data/coco/annotations/"+'instances_{}.json'.format("train2017"))
fabric2coco.save_coco_json(val_instance, "data/coco/annotations/" + 'instances_{}.json'.format("val2017"))
三、MMDetction的安装与修改
- 把mmdetection代码 clone到本地
git clone https://github.com/open-mmlab/mmdetection.git
- 修改配置文件
我这里的是配置文件cascade_rcnn_r50_fpn_guangdong.py,代码如下
_base_ = [
'../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_2x.py', '../_base_/default_runtime.py'
]
# model settings
model = dict(
type='CascadeRCNN',
pretrained='torchvision://resnet50',
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
dcn=dict(type='DCNv2', deform_groups=1, fallback_on_stride=False),
stage_with_dcn=(False, True, True, True),#这里加入了DCNv2
style='pytorch'),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5),
rpn_head=dict(
type='RPNHead',
in_channels=256,
feat_channels=256,
anchor_generator=dict(
type='AnchorGenerator',
scales=[8],
ratios=[0.02, 0.05, 0.1, 0.5, 1.0, 2.0, 2.0, 10.0, 20.0, 50.0],
strides=[4, 8, 16, 32, 64]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[.0, .0, .0, .0],
target_stds=[1.0, 1.0, 1.0, 1.0]),
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0)),
roi_head=dict(
type='CascadeRoIHead',
num_stages=3,
stage_loss_weights=[1, 0.5, 0.25],
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
bbox_head=[
dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=15,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2]),
reg_class_agnostic=True,
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=False,
loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
loss_weight=1.0)),
dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=15,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.05, 0.05, 0.1, 0.1]),
reg_class_agnostic=True,
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=False,
loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
loss_weight=1.0)),
dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=15,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.033, 0.033, 0.067, 0.067]),
reg_class_agnostic=True,
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=False,
loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0))
]),
# model training and testing settings
train_cfg=dict(
rpn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.7,
neg_iou_thr=0.3,
min_pos_iou=0.3,
match_low_quality=True,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=256,
pos_fraction=0.5,
neg_pos_ub=-1,
add_gt_as_proposals=False),
allowed_border=0,
pos_weight=-1,
debug=False),
rpn_proposal=dict(
nms_across_levels=False,
nms_pre=2000,
nms_post=2000,
max_num=2000,
nms_thr=0.7,
min_bbox_size=0),
rcnn=[
dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0.5,
match_low_quality=False,
ignore_iof_thr=-1),
sampler=dict(
type='OHEMSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=-1,
debug=False),
dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.6,
neg_iou_thr=0.6,
min_pos_iou=0.6,
match_low_quality=False,
ignore_iof_thr=-1),
sampler=dict(
type='OHEMSampler', #使用OHEM
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=-1,
debug=False),
dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.7,
neg_iou_thr=0.7,
min_pos_iou=0.7,
match_low_quality=False,
ignore_iof_thr=-1),
sampler=dict(
type='OHEMSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=-1,
debug=False)
]),
test_cfg=dict(
rpn=dict(
nms_across_levels=False,
nms_pre=1000,
nms_post=1000,
max_num=1000,
nms_thr=0.7,
min_bbox_size=0),
rcnn=dict(
score_thr=0.05,
nms=dict(type='nms', iou_threshold=0.5),
max_per_img=100)))
data_root = 'data/coco/'
dataset_type = 'CocoDataset'
classes = ('沾污', '错花', '水印', '花毛', '缝头', '缝头印', '虫粘', '破洞',
'褶子', '织疵', '漏印', '蜡斑', '色差', '网折', '其他')
data = dict(
samples_per_gpu=2,
workers_per_gpu=4,
train=dict(
type='CocoDataset',
classes=classes,
ann_file='data/coco/annotations/instances_train2017.json',
img_prefix='data/coco/train2017/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', img_scale=(1500, 700), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
]),
val=dict(
type='CocoDataset',
classes=classes,
ann_file='data/coco/annotations/instances_val2017.json',
img_prefix='data/coco/val2017/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1500, 700),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]),
test=dict(
type='CocoDataset',
classes=classes,
ann_file='data/coco/annotations/instances_val2017.json',
img_prefix='data/coco/val2017',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1500, 700),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]))
#load_from = "checkpoints/cascade_rcnn_r50_fpn_1x_coco_20200316-3dc56deb.pth" #注意这里要使用预训练模型的话,需要自己从mmdetection的github页面下载模型
optimizer = dict(type='SGD', lr=0.0025, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=None)
注意这里要使用预训练模型的话,需要自己从mmdetection的github页面下载模型到checkpionts中(需要自己创建一个空文件checkpionts),并且在刚刚加上这句"load_from = "checkpoints/cascade_rcnn_r50_fpn_1x_coco_20200316-3dc56deb.pth",这里我下载的是cascade_rcnn_r50_fpn_1x_coco_20200316-3dc56deb.pth,具体预训练模型自行修改。
- 检测文件detect.py
import time, os
import json
import mmcv
from mmdet.apis import init_detector, inference_detector
def main():
config_file = 'configs/cascade_rcnn/cascade_rcnn_r50_fpn_guangdong.py' # 修改成自己的配置文件
checkpoint_file = 'checkpoints/epoch_12_2_last.pth' # 修改成自己的训练权重
test_path = 'data/guangdong/tcdata/guangdong1_round2_testB_20191024' # 官方测试集图片路径
json_name = "result.json"
model = init_detector(config_file, checkpoint_file, device='cuda:0')
img_list = []
for img_name in os.listdir(test_path):
# if img_name.endswith('.jpg'):
img_list.append(img_name)
result = []
for i, img_name in enumerate(img_list, 1):
# img_det = img_name.split('.')[0]
full_img = os.path.join(test_path, img_name, img_name+'.jpg')
predict = inference_detector(model, full_img)
for i, bboxes in enumerate(predict, 1):
if len(bboxes) > 0:
defect_label = i
# print(i)
image_name = img_name + '.jpg'
for bbox in bboxes:
x1, y1, x2, y2, score = bbox.tolist()
x1, y1, x2, y2 = round(x1, 2), round(y1, 2), round(x2, 2), round(y2, 2) # save 0.00
result.append(
{
'name': image_name, 'category': defect_label, 'bbox': [x1, y1, x2, y2], 'score': score})
with open(json_name, 'w') as fp:
json.dump(result, fp, indent=4, separators=(',', ': '))
if __name__ == "__main__":
main()
- 制作train.sh,run.sh
1).train.sh
这里我是单GPU训练(1070)
#!/usr/bin/env bash
python tools/train.py configs/cascade_rcnn/cascade_rcnn_r50_fpn_guangdong.py --gpus 1
2).run.sh
python detect.py
四、Dockerfile文件及docker镜像的制作
1.Dockerfile文件
先给出我的Dockerfile文件,注意创建的Dockerfile文件要放在mmdetection的当前目录下:
ARG PYTORCH="1.6.0"
ARG CUDA="10.1"
ARG CUDNN="7"
FROM pytorch/pytorch:${PYTORCH}-cuda${CUDA}-cudnn${CUDNN}-devel
ENV TORCH_CUDA_ARCH_LIST="6.0 6.1 7.0+PTX"
ENV TORCH_NVCC_FLAGS="-Xfatbin -compress-all"
ENV CMAKE_PREFIX_PATH="$(dirname $(which conda))/../"
RUN apt-get update && apt-get install -y ffmpeg libsm6 libxext6 git ninja-build libglib2.0-0 libsm6 libxrender-dev libxext6 \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
# Install MMCV
RUN pip install mmcv-full==latest+torch1.6.0+cu101 -f https://openmmlab.oss-accelerate.aliyuncs.com/mmcv/dist/index.html
# Install MMDetection
RUN conda clean --all
#RUN git clone https://github.com/open-mmlab/mmdetection.git /mmdetection
ADD . /
WORKDIR /
ENV FORCE_CUDA="1"
RUN pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements/build.txt
RUN pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --no-cache-dir -e .
RUN apt-get update
RUN apt-get install curl
2.mmdetection镜像
1)build镜像
docker build -t registry.cn-shenzhen.aliyuncs.com/你阿里云的仓命名空间/你阿里云的仓库名称:1.0 .
2)训练与测试(记得先su 一下进入root)
训练(当然也可以在本地训练,不过需要自己配环境)
1、在命令行直接训练
一、查看image id :
docker images
二、运行:
docker run --gpus all -v /home/yhh/workspace/datawhale/mmdetection/data:/data -it e69a22f6c832 sh train.sh
| |
本地数据集的路径 映射到docker镜像里数据集的路径
本地数据集的路径 与 映射到docker镜像里数据集的路径 之间用 “:” 隔开,这里我都是放在当前目录的data文件里,你的请注意自行修改。
2、在进去docker容器里
一、查看image id :
docker images
二、运行:
docker run --gpus all -v /home/yhh/workspace/datawhale/mmdetection/data:/data -it e69a22f6c832 /bin/bash
| | | |
用GPU 本地数据集的路径 映射到docker镜像里数据集的路径 image_id
这时候就跟你进入一个新的linux系统一样,不过环境已经配好了,训练操作就跟你在本地的linux的操作一样,例如我这里的训练命令:python tools/train.py configs/cascade_rcnn/cascade_rcnn_r50_fpn_guangdong.py --gpus 1
测试 测试与训练类似,就不述了,略。。。。
五、提交
推送镜像
(1)查看镜像 id
docker images
(2)推送镜像
docker push registry.cn-shenzhen.aliyuncs.com/test_for_tianchi/test_for_tianchi_submit:1.0(自己替换仓
库地址以及指定版本号)
提交
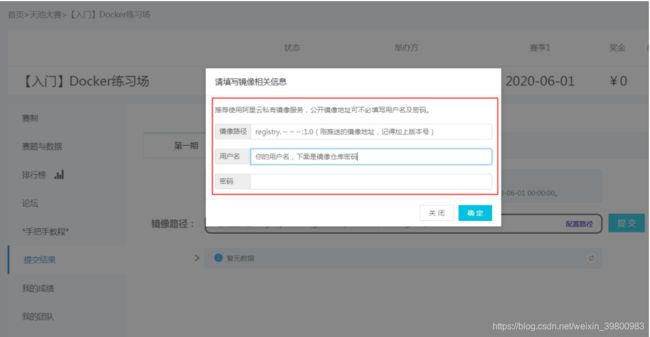
在左侧【提交结果】中填写推送的镜像路径、用户名和密码,即可提交。根据【我的成绩】中的分数和日志可以查看运行情况。
这一次的分数,更惨:
