Python爬取你好李焕英豆瓣短评并利用stylecloud制作更酷炫的词云图
词云图:






爬取过程:
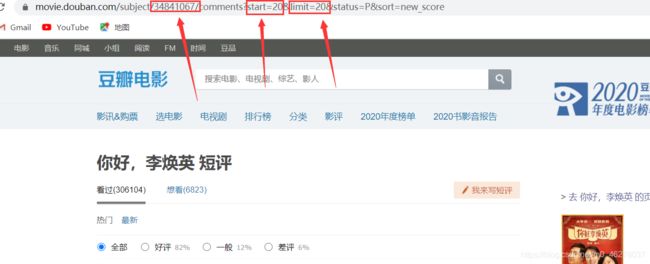
你好,李焕英 短评的URL:
https://movie.douban.com/subject/34841067/comments?start=20&limit=20&status=P&sort=new_score
分析要爬取的URL;
34841067:电影ID
start=20:开始页面
limit=20:每页评论条数
代码:
url = 'https://movie.douban.com/subject/%s/comments?start=%s&limit=20&sort=new_score&status=P % (movie_id, (i - 1) * 20)
在谷歌浏览器中按F12进入开发者调试模式,查看源代码,找到短评的代码位置,查看位于哪个div,哪个标签下:
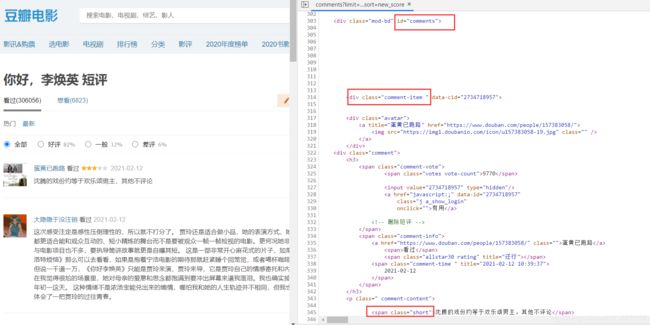
可以看到评论在div[id=‘comments’]下的div[class=‘comment-item’]中的第一个span[class=‘short’]中,使用正则表达式提取短评内容,即代码为:
url = 'https://movie.douban.com/subject/%s/comments?start=%s&limit=20&sort=new_score&status=P' \
% (movie_id, (i - 1) * 20)
req = requests.get(url, headers=headers)
req.encoding = 'utf-8'
comments = re.findall('(.*)', req.text)
完整代码:
# 分析豆瓣你好李焕英的影评,生成词云
# https://movie.douban.com/subject/34841067/comments?start=20&limit=20&status=P&sort=new_score
# url = 'https://movie.douban.com/subject/%s/comments?start=%s&limit=20&sort=new_score&status=P '\
# % (movie_id, (i - 1) * 20)
import requests
from stylecloud import gen_stylecloud
import jieba
import re
from bs4 import BeautifulSoup
from wordcloud import STOPWORDS
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:64.0) Gecko/20100101 Firefox/64.0'
}
def jieba_cloud(file_name, icon):
with open(file_name, 'r', encoding='utf8') as f:
word_list = jieba.cut(f.read())
result = " ".join(word_list) # 分词用 隔开
# 制作中文词云
icon_name = " "
if icon == "1":
icon_name = ''
elif icon == "2":
icon_name = "fas fa-space-shuttle"
elif icon == "3":
icon_name = "fas fa-heartbeat"
elif icon == "4":
icon_name = "fas fa-bug"
elif icon == "5":
icon_name = "fas fa-thumbs-up"
elif icon == "6":
icon_name = "fab fa-qq"
pic = str(icon) + '.png'
if icon_name is not None and len(icon_name) > 0:
gen_stylecloud(text=result,
size=1024, # stylecloud 的大小(长度和宽度)
icon_name=icon_name,
font_path='simsun.ttc',
max_font_size=200, # stylecloud 中的最大字号
max_words=2000, # stylecloud 可包含的最大单词数
stopwords=True, # 布尔值,用于筛除常见禁用词
custom_stopwords=STOPWORDS,
output_name=pic)
else:
gen_stylecloud(text=result, font_path='simsun.ttc', output_name=pic)
return pic
def spider_comment(movie_id, page):
comment_list = []
with open("douban.txt", "a+", encoding='utf-8') as f:
for i in range(1,page+1):
url = 'https://movie.douban.com/subject/%s/comments?start=%s&limit=20&sort=new_score&status=P' \
% (movie_id, (i - 1) * 20)
req = requests.get(url, headers=headers)
req.encoding = 'utf-8'
comments = re.findall('(.*)', req.text)
f.writelines('\n'.join(comments))
print(comments)
# 主函数
if __name__ == '__main__':
movie_id = '34841067'
page = 10
spider_comment(movie_id, page)
jieba_cloud("douban.txt", "1")
jieba_cloud("douban.txt", "2")
jieba_cloud("douban.txt", "3")
jieba_cloud("douban.txt", "4")
jieba_cloud("douban.txt", "5")
jieba_cloud("douban.txt", "6")
stylecloud初识:
stylecloud是wordcloud优化改良版,操作简单,直接调用。
- 可以使用 Font Awesome 提供的免费图标更改词云的形状;
- 通过 palettable 更改调色板以自定义风格,更改背景颜色;
- 添加梯度使颜色按照特定方向流动。
stylecloud参数详解:
text: 传入的字符串列表
file_path: 字符串的文本/ CSV的文件路径
gradient: 渐变方向 [「default:」 None]('horizontal')
size:stylecloud的大小(调大可提高图片清晰度)
icon_name: stylecloud形状的图标名称 [「default:」 fas fa-flag]
palette: 调色板 [「default:」 cartocolors.qualitative.Bold_5]
colors: 用作文本颜色的颜色 [「default:」 None]
background_color: 背景色(名称或十六进制)[「default:」 white]
max_font_size: stylecloud中的最大字体大小 [「default:」 200]
max_words: 要包含在stylecloud中的最大单词数 [「default:」 2000]
stopwords: 用于过滤掉常见的停用词 [「default:」 True]
custom_stopwords: list定制停用词列表 [「default:」 STOPWORDS, via word_cloud]
output_name: stylecloud的输出文件名 [「default:」 stylecloud.png]
font_path: 要在stylecloud中使用的字体的.ttf文件的路径 [「default:」 uses included Staatliches font]
random_state: 控制文字和颜色的随机状态 [「default:」 None]
collocations: 是否包括两个单词的搭配(二字组)。与基本word_cloud软件包的行为相同 [「default:」 True]
invert_mask: 是否反转图标掩码,因此单词填充除图标掩码以外的所有空格 [「default:」 False]
例如:
def gen_stylecloud(text=None,
file_path=None, # 输入文本/CSV 的文件路径
size=512, # stylecloud 的大小(长度和宽度)
icon_name='fas fa-flag', # stylecloud 形状的图标名称(如 fas fa-grin)。[default: fas fa-flag]
palette='cartocolors.qualitative.Bold_5', # 调色板(通过 palettable 实现)。[default: cartocolors.qualitative.Bold_6]
colors=None,
background_color="white", # 背景颜色
max_font_size=200, # stylecloud 中的最大字号
max_words=2000, # stylecloud 可包含的最大单词数
stopwords=True, # 布尔值,用于筛除常见禁用词
custom_stopwords=STOPWORDS,
icon_dir='.temp',
output_name='stylecloud.png', # stylecloud 的输出文本名
gradient=None, # 梯度方向
font_path=os.path.join(STATIC_PATH,
'Staatliches-Regular.ttf'), # stylecloud 所用字体
random_state=None, # 控制单词和颜色的随机状态
collocations=True,
invert_mask=False,
pro_icon_path=None,
pro_css_path=None):
词云形状:
使用 Font Awesome 提供的免费图标更改词云的形状。
https://fontawesome.dashgame.com/
https://fa5.dashgame.com/#/%E5%9B%BE%E6%A0%87
https://fontawesome.com/icons?d=gallery