数仓建设中最常用模型--Kimball维度建模详解
数仓建模首推书籍《数据仓库工具箱:维度建模权威指南》,本篇文章参考此书而作。
文章首发公众号:五分钟学大数据,公众号中发送“维度建模”即可获取此书籍第三版电子书
先来介绍下此书,此书是基于作者 60 多年的实际业务环境而总结的经验及教训,为读者提供正式的维度设计和开发技术。面向数仓和BI设计人员,书中涉及到的内容非常广泛,围绕一系列的商业场景或案例研究进行组织。强烈建议买一本实体书研究,反复通读全书至少三遍以上,你的技术将会有质的飞跃。

因为本文是纯理论知识,密密麻麻的字,很多人可能看不下去,所以我尽量用最少的字来表达,尽量将晦涩难懂的词语转化为通俗易于理解的词,将文中的重点加粗展示,内容尽量精简,以保证在不表达错误的情况下更利于读者学习!希望和大家能一起学习,一起进步,努力到达我们自己的金字塔顶部
维度建模是什么
维度模型是数据仓库领域大师Ralph Kimball 所倡导,以分析决策的需求出发构建模型,构建的数据模型为分析需求服务,因此它重点解决用户如何更快速完成分析需求,同时还有较好的大规模复杂查询的响应性能。
维度建模是 数据仓库/商业智能 项目成功的关键,为什么这么说,因为不管我们的数据量从GB到TG还是到PB,虽然数据量越来越大,但是数据展现要获得成功,就必须建立在简单性的基础之上,而维度建模就是时刻考虑如何能够提供简单性,以业务为驱动,以用户理解性和查询性能为目标。
维度建模:维度建模是专门应用于分析型数据库、数据仓库、数据市集建模的方法。数据市集可以理解为一种“小型的数据仓库”
维度建模指导我们在数据仓库中如何建表
维度建模分为两种表:事实表和维度表
- 事实表:必然存在的一些数据,像采集的日志文件,订单表,都可以作为事实表
特征:是一堆主键的集合,每个主键对应维度表中的一条记录,客观存在的,根据主题确定出需要使用的数据 - 维度表:维度就是所分析的数据的一个量,维度表就是以合适的角度来创建的表,分析问题的一个角度:时间、地域、终端、用户等角度
维度建模的三种模式
- 星形模式:以事实表为中心,所有的维度表直接连在事实表上,最简单最常用的一种
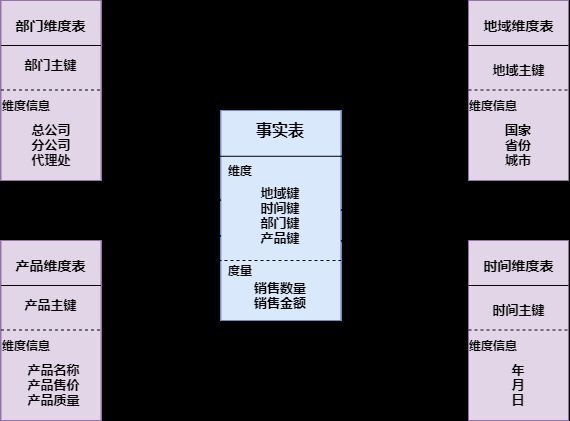
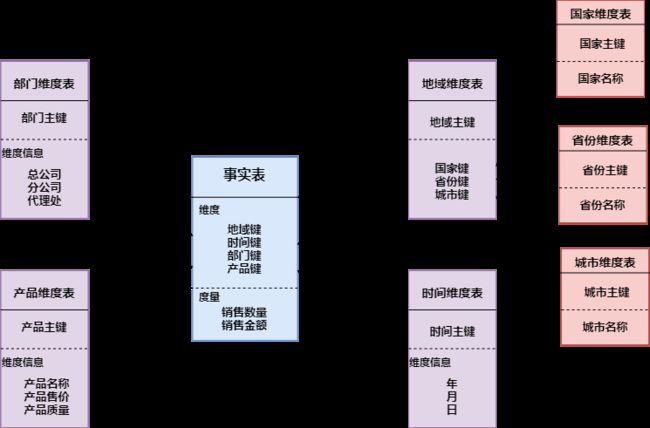
- 雪花模式:雪花模式的维度表可以拥有其他的维度表,这种表不易维护,一般不推荐使用
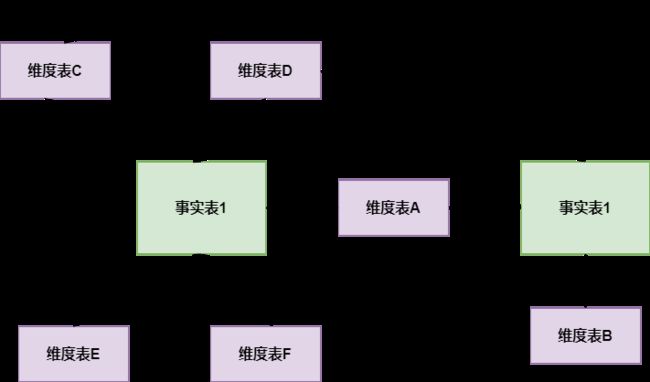
- 星座模型:基于多张事实表,而且共享维度信息,即事实表之间可以共享某些维度表
维度建模怎么建
我们知道事实表,维度表,星形模型,星座模型这些概念了,但是实际业务中,给了我们一堆数据,我们怎么拿这些数据进行数仓建设呢,数仓工具箱作者根据自身60多年的实际业务经验,给我们总结了如下四步,请务必记住!
数仓工具箱中的维度建模四步走:

请牢记以上四步,不管什么业务,就按照这个步骤来,顺序不要搞乱,因为这四步是环环相扣,步步相连。下面详细拆解下每个步骤怎么做
1、选择业务过程
维度建模是紧贴业务的,所以必须以业务为根基进行建模,那么选择业务过程,顾名思义就是在整个业务流程中选取我们需要建模的业务,根据运营提供的需求及日后的易扩展性等进行选择业务。比如商城,整个商城流程分为商家端,用户端,平台端,运营需求是总订单量,订单人数,及用户的购买情况等,我们选择业务过程就选择用户端的数据,商家及平台端暂不考虑。业务选择非常重要,因为后面所有的步骤都是基于此业务数据展开的。
2、声明粒度
先举个例子:对于用户来说,一个用户有一个身份证号,一个户籍地址,多个手机号,多张银行卡,那么与用户粒度相同的粒度属性有身份证粒度,户籍地址粒度,比用户粒度更细的粒度有手机号粒度,银行卡粒度,存在一对一的关系就是相同粒度。为什么要提相同粒度呢,因为维度建模中要求我们,在同一事实表中,必须具有相同的粒度,同一事实表中不要混用多种不同的粒度,不同的粒度数据建立不同的事实表。并且从给定的业务过程获取数据时,强烈建议从关注原子粒度开始设计,也就是从最细粒度开始,因为原子粒度能够承受无法预期的用户查询。但是上卷汇总粒度对查询性能的提升很重要的,所以对于有明确需求的数据,我们建立针对需求的上卷汇总粒度,对需求不明朗的数据我们建立原子粒度。
3、确认维度
维度表是作为业务分析的入口和描述性标识,所以也被称为数据仓库的“灵魂”。在一堆的数据中怎么确认哪些是维度属性呢,如果该列是对具体值的描述,是一个文本或常量,某一约束和行标识的参与者,此时该属性往往是维度属性,数仓工具箱中告诉我们牢牢掌握事实表的粒度,就能将所有可能存在的维度区分开,并且要确保维度表中不能出现重复数据,应使维度主键唯一
4、确认事实
事实表是用来度量的,基本上都以数量值表示,事实表中的每行对应一个度量,每行中的数据是一个特定级别的细节数据,称为粒度。维度建模的核心原则之一是同一事实表中的所有度量必须具有相同的粒度。这样能确保不会出现重复计算度量的问题。有时候往往不能确定该列数据是事实属性还是维度属性。记住最实用的事实就是数值类型和可加类事实。所以可以通过分析该列是否是一种包含多个值并作为计算的参与者的度量,这种情况下该列往往是事实。
事实表种类
事实表分为以下6类:
- 事务事实表
- 周期快照事实表
- 累积快照事实表
- 无事实的事实表
- 聚集事实表
- 合并事实表
简单解释下每种表的概念:
- 事务事实表
表中的一行对应空间或时间上某点的度量事件。就是一行数据中必须有度量字段,什么是度量,就是指标,比如说销售金额,销售数量等这些可加的或者半可加就是度量值。另一点就是事务事实表都包含一个与维度表关联的外键。并且度量值必须和事务粒度保持一致。
- 周期快照事实表
顾名思义,周期事实表就是每行都带有时间值字段,代表周期,通常时间值都是标准周期,如某一天,某周,某月等。粒度是周期,而不是个体的事务,也就是说一个周期快照事实表中数据可以是多个事实,但是它们都属于某个周期内。
- 累计快照事实表
周期快照事实表是单个周期内数据,而累计快照事实表是由多个周期数据组成,每行汇总了过程开始到结束之间的度量。每行数据相当于管道或工作流,有事件的起点,过程,终点,并且每个关键步骤都包含日期字段。如订单数据,累计快照事实表的一行就是一个订单,当订单产生时插入一行,当订单发生变化时,这行就被修改。
- 无事实的事实表
我们以上讨论的事实表度量都是数字化的,当然实际应用中绝大多数都是数字化的度量,但是也可能会有少量的没有数字化的值但是还很有价值的字段,无事实的事实表就是为这种数据准备的,利用这种事实表可以分析发生了什么。
- 聚集事实表
聚集,就是对原子粒度的数据进行简单的聚合操作,目的就是为了提高查询性能。如我们需求是查询全国所有门店的总销售额,我们原子粒度的事实表中每行是每个分店每个商品的销售额,聚集事实表就可以先聚合每个分店的总销售额,这样汇总所有门店的销售额时计算的数据量就会小很多。
- 合并事实表
这种事实表遵循一个原则,就是相同粒度,数据可以来自多个过程,但是只要它们属于相同粒度,就可以合并为一个事实表,这类事实表特别适合经常需要共同分析的多过程度量。
维度表技术
- 维度表结构
维度表谨记一条原则,包含单一主键列,但有时因业务复杂,也可能出现联合主键,请尽量避免,如果无法避免,也要确保必须是单一的,这很重要,如果维表主键不是单一,和事实表关联时会出现数据发散,导致最后结果可能出现错误。
维度表通常比较宽,包含大量的低粒度的文本属性。
- 跨表钻取
跨表钻取意思是当每个查询的行头都包含相同的一致性属性时,使不同的查询能够针对两个或更多的事实表进行查询
钻取可以改变维的层次,变换分析的粒度。它包括上钻/下钻:
上钻(roll-up):上卷是沿着维的层次向上聚集汇总数据。例如,对产品销售数据,沿着时间维上卷,可以求出所有产品在所有地区每月(或季度或年或全部)的销售额。
下钻(drill-down):下钻是上钻的逆操作,它是沿着维的层次向下,查看更详细的数据。
- 退化维度
退化维度就是将维度退回到事实表中。因为有时维度除了主键没有其他内容,虽然也是合法维度键,但是一般都会退回到事实表中,减少关联次数,提高查询性能
- 多层次维度
多数维度包含不止一个自然层次,如日期维度可以从天的层次到周到月到年的层次。所以在有些情况下,在同一维度中存在不同的层次。
- 维度表空值属性
当给定维度行没有被全部填充时,或者当存在属性没有被应用到所有维度行时,将产生空值维度属性。上述两种情况,推荐采用描述性字符串代替空值,如使用 unknown 或 not applicable 替换空值。
- 日历日期维度
在日期维度表中,主键的设置不要使用顺序生成的id来表示,可以使用更有意义的数据表示,比如将年月日合并起来表示,即YYYYMMDD,或者更加详细的精度。