面向计算机架构的机器学习

文 / Amir Yazdanbakhsh,Google Research 研究员
机器学习 (ML) 近期取得了长足进步,而促成这一进步的关键因素便是自定义加速器的研发(例如 Google TPU 和 Edge TPU)。自定义加速器能够显著提高可用算力,从而解锁各种功能,如 AlphaGo、RankBrain、WaveNets 和对话代理。计算能力的提升,也进一步提高了神经网络训练和推理的性能,从而可以在视觉、语言、理解和自动驾驶汽车等广泛应用中实现更多新的可能。
Google TPU
https://cloud.google.com/tpuAlphaGo
https://deepmind.com/blog/article/alphago-zero-starting-scratch
为维持进步的势头,硬件加速器生态系统必须继续在架构设计上进行创新,并适应快速发展的 ML 模型和应用。要实现这一点,我们需要评估许多不同的加速器设计点,而每个点不仅可以提高计算能力,还可以解锁新的能力。这些设计点通常可根据各种软硬件因素(如内存容量、不同级别的计算单元数量、并行性、互连网络、流水线、软件映射等)来参数化。这是一项艰巨的优化任务,因为搜索空间会呈指数级增长1 ,而目标函数(例如,更低的延迟和/或更高的能效)需要耗费大量的计算能力以通过模拟或合成来进行评估,这使得找到可行的加速器配置具有一定的挑战性。
在 “Appllo:可迁移架构探索 (Apollo: Transferable Architecture Exploration)” 一文中,我们介绍了我们在 ML 驱动的自定义加速器设计方面的研究进展。虽然近期的研究已经证明利用 ML 可以加快低阶布局规划过程(在这一过程中,硬件组件的空间布局和连接将在硅中进行),但在此研究中,我们会专注于将 ML 融合到高阶系统规范和架构设计阶段,该阶段是影响芯片整体性能的关键因素,而在此阶段建立的设计元素将能够控制高阶的功能。我们的研究表明 ML 算法能够促进对架构的探索,帮助在一系列深度神经网络中找出高性能架构,并且领域涵盖图像分类、目标检测、OCR 和语义分割。
Appllo:可迁移架构探索
http://arxiv.org/abs/2102.01723近期的研究
https://ai.googleblog.com/2020/04/chip-design-with-deep-reinforcement.html
架构搜索空间和工作负载
在进行架构探索时,我们的目标是为一组工作负载找到一组可行的加速器参数,从而在一组可选的用户定义约束条件下使所需的目标函数(例如,运行时的加权平均值)的值最小化。然而,架构搜索的流形决定了搜索过程通常会包含许多无法从软件映射到硬件的设计点。其中一些是先验已知的设计点,可以通过用户将其制定为优化约束条件来绕过(例如,在面积预算2 约束的情况下,总内存大小不能超过预定义的限制)。但是,由于架构和编译器的相互影响以及搜索空间的复杂性,有些约束条件可能无法正确地制定到优化中,因此编译器可能无法为目标硬件找到可行的软件映射。在优化问题中,这些不可行的设计点难以制定,并且一般在整个编译器通过之前始终为未知。因此,架构探索的主要挑战之一是如何有效地避开不可行的设计点,以最少次数的周期精确架构模拟对搜索空间进行有效探索。
下图显示了目标 ML 加速器的整体架构搜索空间。该加速器包含一个二维的处理元件 (Processing Elements, PE) 阵列,每个处理元件以单指令流多数据流 (SIMD) 的方式执行一组算术计算。每个 PE 的主要架构组件是处理核心,这些核心包含多个用于 SIMD 操作的计算通道。每个 PE 中都有供其所有计算核心共享的共享内存(PE 内存),主要用于存储模型激活、部分结果和输出,而供单个核心使用的内存则主要用于存储模型参数。每个核心都有多条具有多路乘法累加 (MAC) 单元的计算通道。而模型每个计算周期的结果要么回存到 PE 内存中以用于进一步计算,要么卸载回 DRAM 中。
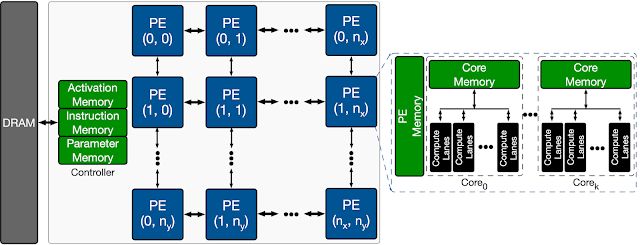
用于架构探索的 ML 加速器(基于模板)概览
优化策略
在这项研究中,我们针对架构探索,探究了四种优化策略:
随机:对架构搜索空间进行均匀的随机采样。
Vizier:将贝叶斯优化用于目标函数评估时间较长(例如硬件模拟,可能需要几个小时才能完成)的搜索空间的探索。利用来自搜索空间的采样点集合,贝叶斯优化可形成一个替代函数(通常用高斯过程来表示),该函数可用于模拟搜索空间的流形。在替代函数值的引导下,贝叶斯优化算法会在探索和利用中进行权衡,决定是对流形中有希望的区域进行更多的采样(即利用),还是对搜索空间中未见的区域进行更多的采样(即探索)。然后,优化算法会使用这些新采样的点进一步更新替代函数,以更好地模拟目标搜索空间。Vizier 使用预期的改进 (Expected Improvement) 作为其核心采集函数。
Vizier
https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/46180.pdf预期的改进
https://proceedings.neurips.cc/paper/2011/file/86e8f7ab32cfd12577bc2619bc635690-Paper.pdf
进化:使用具有 k 个个体的群体进行进化搜索,其中每个个体的基因组对应一个离散的加速器配置序列。新个体的产生方式为:利用 tournament selecting(联赛选择)方法从群体中为每个个体选择两个亲本,以一定的交叉率重组其基因组,并以一定的概率对重组后的基因组进行突变。
进化
https://arxiv.org/pdf/2006.03227.pdftournament selecting
https://wpmedia.wolfram.com/uploads/sites/13/2018/02/09-3-2.pdf
基于群体的黑盒优化 (P3BO):使用已被证明可以提高样本效率和稳健性的优化方法集合,包括进化和基于模型的方法。采样得到的数据在集合中的优化方法之间进行交换,而优化器则根据其性能历史记录进行加权以生成新的配置。我们在研究中使用的是 P3BO 的一个变体,该变体中优化器的超参数使用进化搜索动态更新。
基于群体的黑盒优化
https://arxiv.org/pdf/2006.03227.pdf
加速器搜索空间嵌入向量
为更好地呈现每个优化策略在导航加速器搜索空间中的有效性,我们使用 t-分布式随机邻域嵌入 (t-SNE) 将探索的配置映射到整个优化范围内的二维空间中。我们将所有实验的目标(回报)定义为每个加速器区域的吞吐量(推理/秒)。在下图中, x 和 y 轴表示嵌入空间的 t-SNE 组件(嵌入向量 1 和嵌入向量 2)。星形和圆形标记分别表示不可行(零回报)和可行的设计点,可行设计点的大小与其回报相对应。
果不其然,随机策略以均匀分布的方式搜索该空间,最终在设计空间中找到了极少的可行设计点。
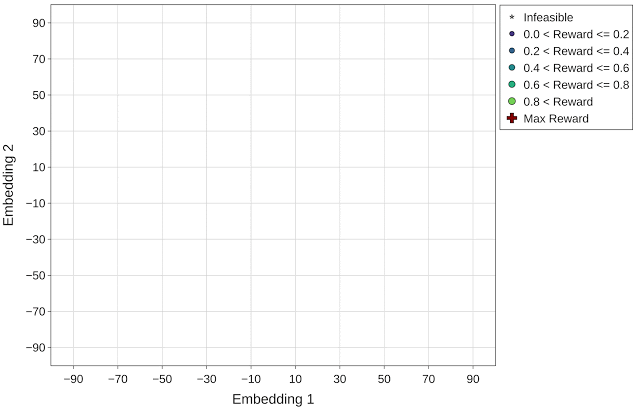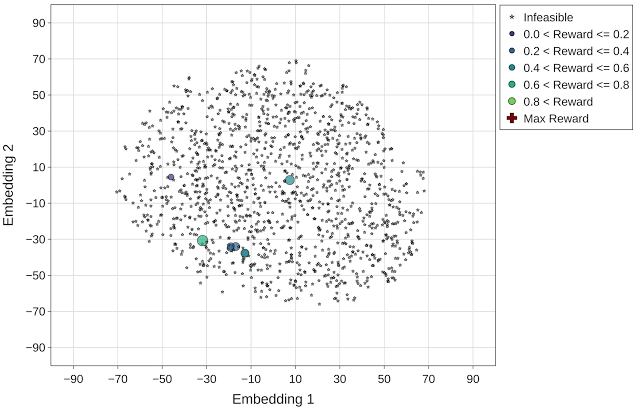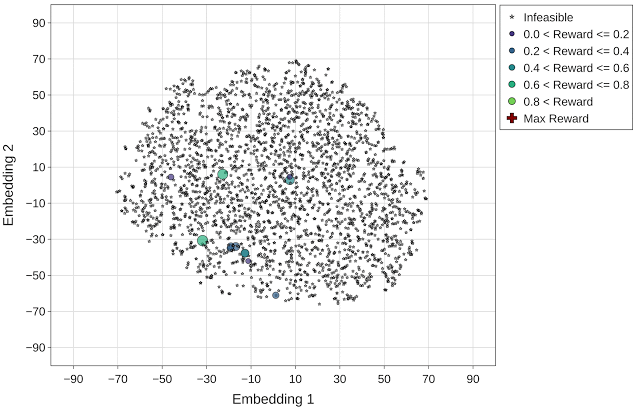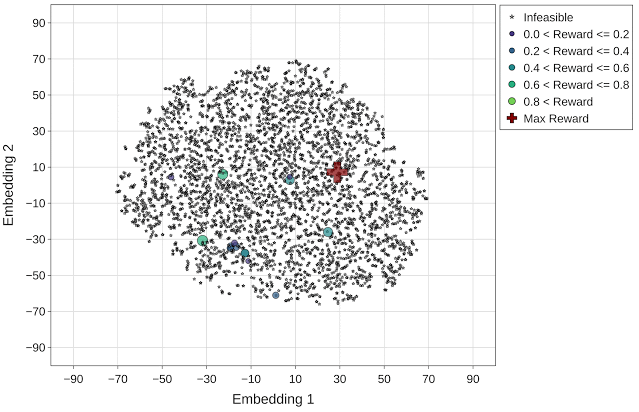
可视化后的图像呈现了通过随机优化策略(最高回报 = 0.96)探索的设计点(约 4000 个)的 t-SNE 组件。最高回报点(红色十字标记)在动画的最后一帧突出显示
与随机采样方法相比,Vizier 默认的优化策略在探索搜索空间和寻找更高回报(1.14 对比 0.96)的设计点之间取得了良好的平衡。然而,这种方法往往会卡在不可行的区域,虽然确实找到了几个具有最高回报的设计点(用红色十字标记表示),但在探索的最后一次迭代中,该方法找到的可行设计点很少。
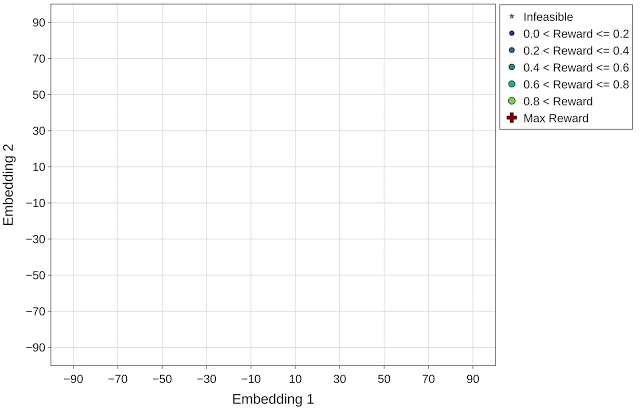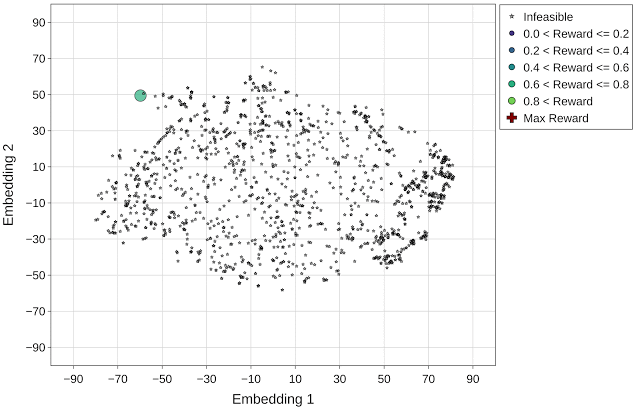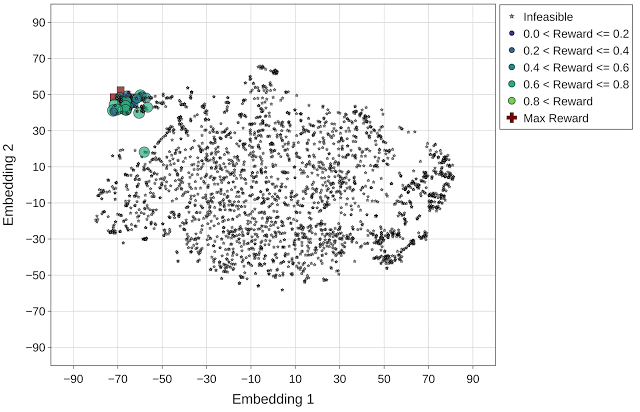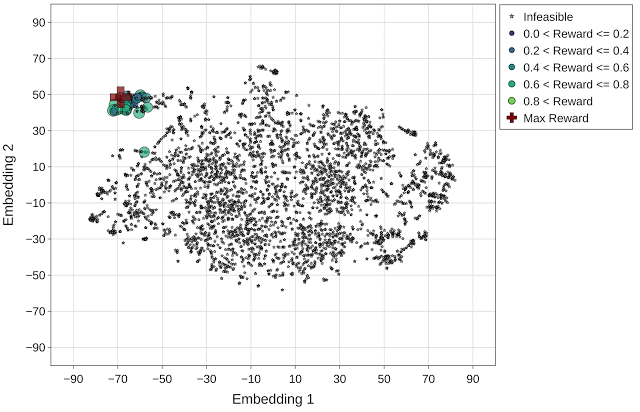
与上文图片相同,但使用的是 Vizier 默认优化策略(最高回报 = 1.14)。最高回报点(红色十字标记)在动画的最后一帧突出显示
而进化策略则是在优化的很早的时候就找到了可行的解,并在其周围形成了可行设计点的集群。因此,这种方法主要做的是浏览可行区域(绿圈),并有效避开不可行的设计点。此外,进化搜索也能够找到更多具有最高回报的设计方案(用红色十字表示)。该方法能够提供多种具有高回报的解决方案,可以让设计者灵活探索各种具有不同设计权衡的架构。
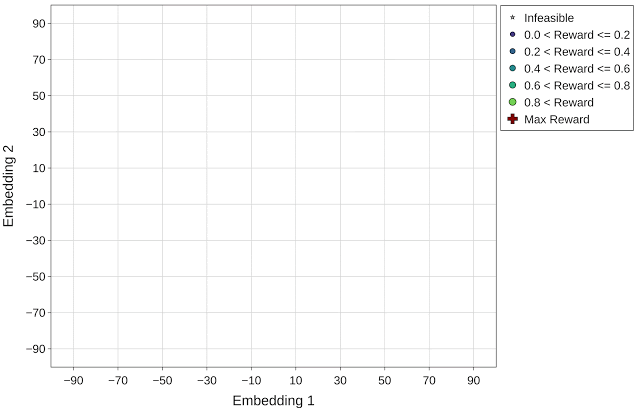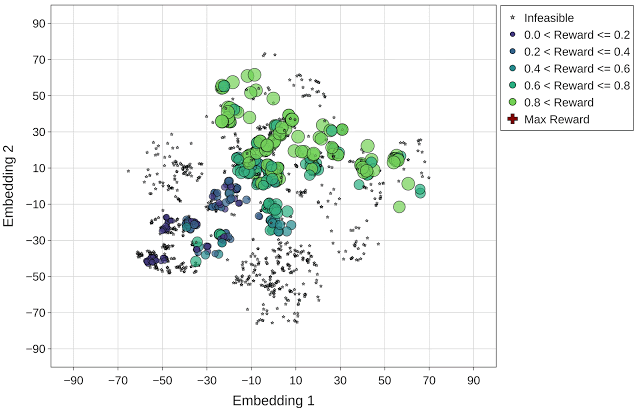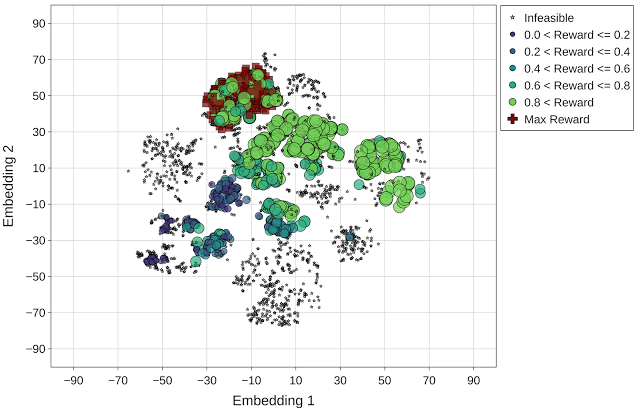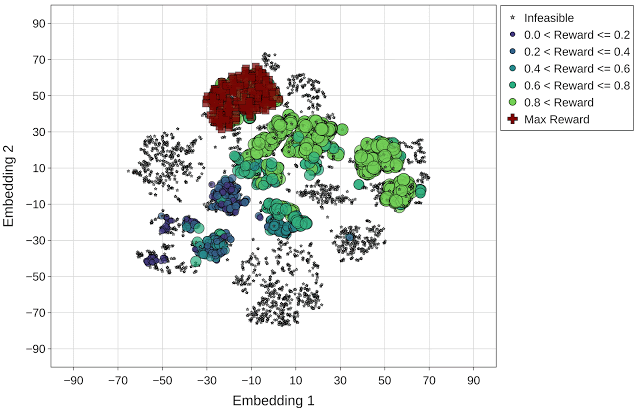
与上文图片相同,但使用的是进化优化策略(最高回报 = 1.10)。最高回报点(红色十字标记)在动画的最后一帧突出显示
最后,基于群体的优化方法 (P3BO) 以更有针对性的方式(具有高回报点的区域)对设计空间进行探索,以找到最优解。P3BO 策略在约束条件较严(如不可行的设计点较多的情况)的搜索空间中找到了具有最高回报的设计点,显示出了其在浏览大量不可行点的搜索空间中的有效性。
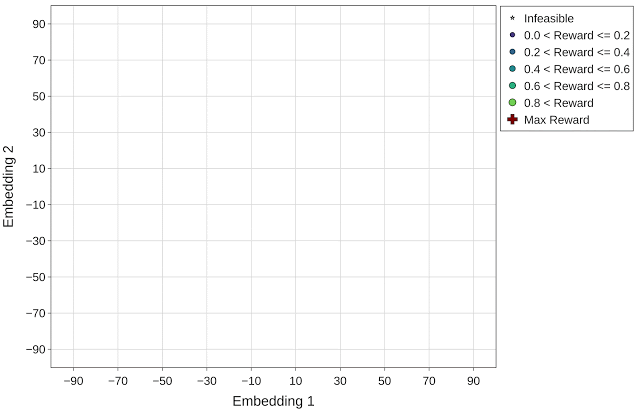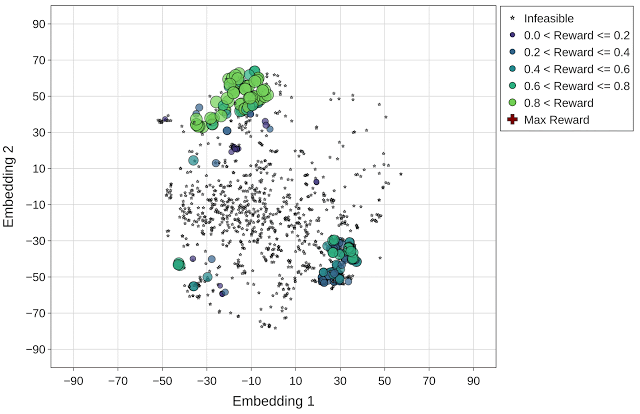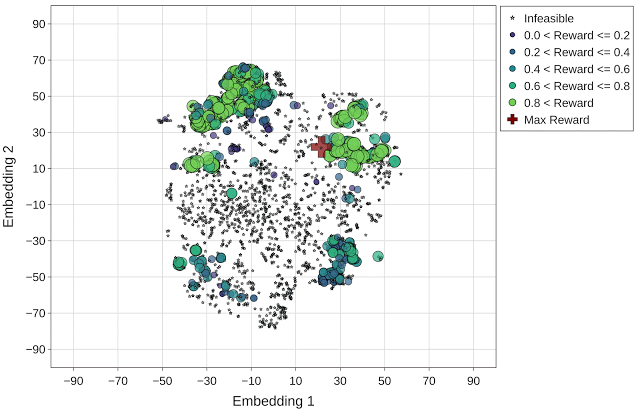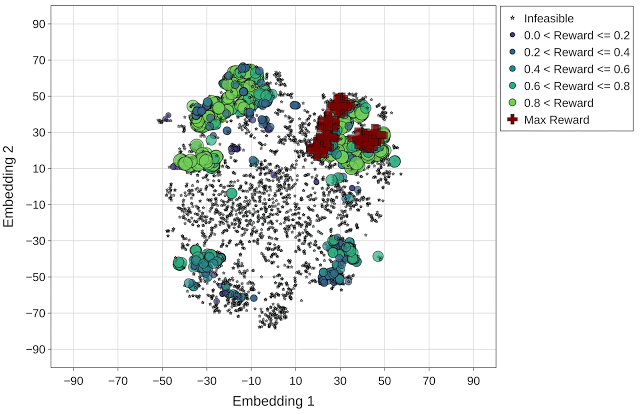
与上文图片相同,但使用的是 P3BO 优化策略(最高回报 = 1.13)。最高回报点(红色十字标记)在动画的最后一帧突出显示
不同设计约束条件下的架构探索
我们还研究了不同面积预算约束条件下(6.8 mm2、5.8 mm2 和 4.8 mm2)各优化策略的效益。下面的小提琴图 (Violin plots) 显示了在优化结束时(经过 10 次运行,每次 4000 次试验后),在所研究的优化策略中,最高可实现回报的完整分布。较宽的部分代表了有较高概率在特定的给定回报下观察到可行的架构配置。这意味着我们倾向于能够增加回报较高(性能较高)点的宽度的优化算法。
架构探索中表现最好的两种优化策略分别是“进化”和 P3BO,这两种策略都能在多次运行中提供具有高回报和稳健性的解决方案。通过研究不同的设计约束条件,我们观察到,当面积预算约束条件收紧时,P3BO 优化策略会产生更多具有高性能的解。例如,当面积预算约束条件设置为 5.8 mm2 时,P3BO 找到的设计点的回报(吞吐量/加速器面积)为 1.25,优于其他所有优化策略。当面积预算约束条件设置为 4.8mm2 时,我们也观察到了同样的趋势,在多次运行中,该策略找到的点的回报略高,且稳健性更好(变异性更小)。
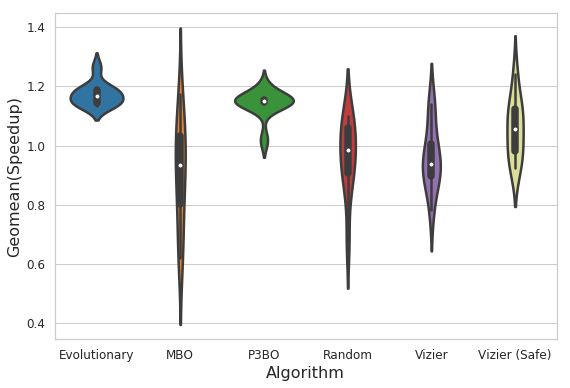
小提琴图显示了在 6.8 mm2 的面积预算下,经过 4000 次试验评估后,10 次运行中各优化策略的最大可实现回报的完整分布。P3BO 和进化算法能够得到更多具有高性能的设计(具有更宽的部分)。x 和 y 轴分别表示所研究的优化算法,以及对比基线加速器得到的增速(回报)的几何平均值

与上文图片相同,但面积预算约束为 5.8 mm2
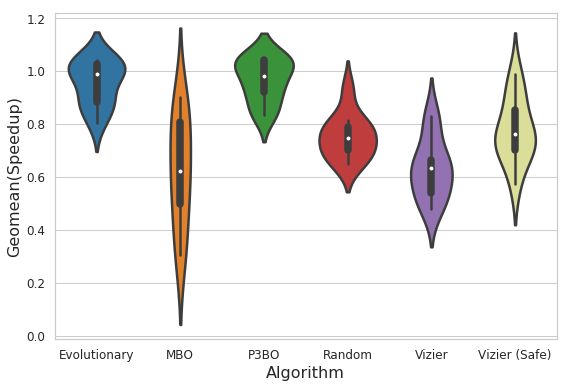
与上文图片相同,但面积预算约束为 4.8 mm2
结论
虽然 “Apollo” 一文朝更好理解加速器设计空间和构建更高效的硬件迈出了第一步,但发明具有新功能的硬件加速器仍然是一个充满未知的领域,同时也是新的前沿趋势。我们相信,这项研究会是一条令人振奋的前进之路,可以进一步探索由 ML 驱动,且适用于跨计算栈架构设计和协同优化(如编译器、映射和调度)的技术,以发明出能够适用于下一代应用的高效加速器。
致谢
这项研究由 Amir Yazdanbakhsh、Christof Angermueller 和 Berkin Akin 合作完成。我们还要感谢 Milad Hashemi、Kevin Swersky、James Laudon、Herman Schmit、Cliff Young、Yanqi Zhou、Albin Jones、Satrajit Chatterjee、Ravi Narayanaswami、Ray (I-Jui) Sung、Suyog Gupta、Kiran Seshadri、Suvinay Subramanian、Matthew Denton,以及 Vizier 团队的帮助和支持。
1. 在我们的目标加速器中,设计点的总数约为 5 x 108。↩
2. 芯片面积大约为芯片上所有硬件元件的总和,包括片上存储、处理引擎、控制器、I/O 引脚等。 ↩
更多 AI 相关阅读:
推出 TracIn:估算训练数据影响力的简单方法
Google 翻译中更稳定的实时语音翻译
ToTTo:受控的表到文本生成数据集
推出 RxR:多语言指令跟随导航基准数据集
利用 AutoML 进行时间序列预测
![]()
