利用Python做一个舞动起来的小姐姐词云视频
文章目录
-
- 实现过程
-
-
- 一、选取视频并下载
- 二、获取视频的弹幕内容
- 三、从视频中提取图片
- 四、人像分割(借助免费的百度AI)
- 五、词云生成
- 六、查看原视频中的帧率和图片尺寸
- 七、合成跳舞视频
- 八、加入原视频音频加以渲染
- 九、参考博文
-
实现过程
一、选取视频并下载
可以利用you-get把哔哩哔哩的视频下载到本地
具体可参考上一篇文章:传送门
二、获取视频的弹幕内容
爬取弹幕内容,我在这里给大家推荐一个非常好用的第三方库,bilibili_api,详细内容可参考官方文档:传送门
代码如下:
from bilibili_api import Verify, video
verify = Verify(sessdata="你的sessdata值的内容", csrf="你的csrf值的内容")
# 参数
BVID = "这里填爬取视频弹幕的BV号"
# 获取视频信息
info = video.get_video_info(bvid=BVID, verify=verify)
# # 假设这里获取 p1 的最新弹幕信息,需要取出 page_id,即每 p 都有自己的编号
page_id = info["pages"][0]["cid"]
# 然后开始获取弹幕
danmakus = video.get_danmaku(bvid=BVID, page_id=page_id)
# 保存弹幕内容
list_all = list()
filename = 'D:/danmu.txt' # 这里是保存的地址
for dm in danmakus:
dm = dm.text
list_all.append(dm)
# print(list_all)
file = open(filename, 'w', encoding='utf-8')
for i in range(len(list_all)):
s = str(list_all[i]).replace('[', '').replace(']', '') # 去除[]
s = s.replace("'", '').replace(',', '') + '\n' # 去除单引号,逗号,每行末尾追加换行符
file.write(s) # 将列表中数据依次写入文件中
print('弹幕获取完毕!!!')
file.close()
Q:sessdata和csrf的值怎么找?
A:


在这里面找到sessdata和bili_jct的内容即可(官方文档说,bili_jct的值的值就是csrf的值)
注意:这两个值不要暴露给别人,可能会被盗号(来自官方文档的提示)
结果显示如下:
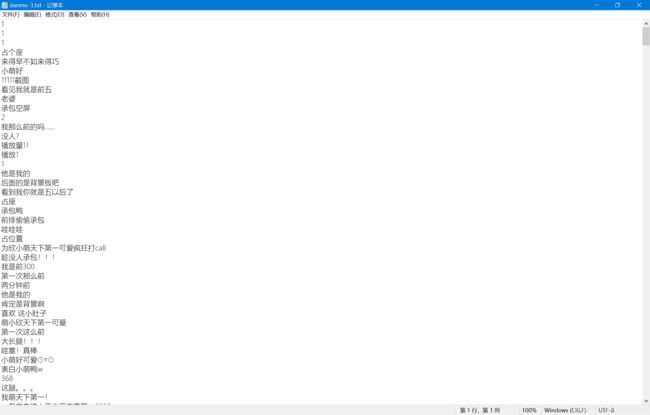
三、从视频中提取图片
(一帧一帧地提取,工程量还是蛮大的)
我们可以使用下面的代码先查看,总共可以分为多少张。
import cv2
# 查看总共有多少张图片
cap = cv2.VideoCapture(r"这里是下载的视频所在的路径")
num = 1
while True:
ret, frame = cap.read()
if ret:
num += 1
else:
break
print(num)
cap.release() # 释放资源
emmm,我爬的这个一分多钟的视频有两千多张,我们可以选取一个范围,就取从第521张到第1314张吧。
import cv2
cap = cv2.VideoCapture(r"这里是下载的视频所在的路径")
num = 1
while True:
# 逐帧读取视频 按顺序保存到本地文件夹
ret, frame = cap.read()
if ret:
if 521 <= num < 1314:
cv2.imwrite(f"这里填预保存图片文件夹的路径/img_{num}.jpg", frame) # 保存一帧帧的图片
print(f'========== 已成功保存第{num}张图片 ==========')
num += 1
else:
break
cap.release() # 释放资源
结果如下:
四、人像分割(借助免费的百度AI)
首先,打开百度AI,传送门,点击右上角的控制台,使用手机扫码登录。登录成功,点击左栏的人脸分析,进行应用创建,创建成功之后,你会在你的应用里得到三个值:

这三个值马上就会用到。
接着,查看人脸分析的Python SDK文件,文件链接传送门
基本熟悉一下它的应用。
最后,直接上代码:
from aip import AipBodyAnalysis
import os
import cv2
import base64
import numpy as np
import time
import random
# 百度云中已创建应用的 APP_ID API_KEY SECRET_KEY
APP_ID = '你的APP_ID的值'
API_KEY = '你的API_KEY的值'
SECRET_KEY = '你的SECRET_KEY的值'
client = AipBodyAnalysis(APP_ID, API_KEY, SECRET_KEY)
# 保存图像分割后的路径
path = '分割后的图像,想要保存的文件夹的路径'
# os.listdir 列出保存到图片名称
img_files = os.listdir('上一步中,保存提取出来的图片的文件夹路径')
# print(img_files)
for num in range(521, 1314): # 图片范围
# 按顺序构造出图片路径
img = f'上一步中,保存提取出来的图片的文件夹路径/img_{num}.jpg'
img1 = cv2.imread(img) # imread读取图片
height, width, _ = img1.shape
# 二进制方式读取图片
with open(img, 'rb') as fp:
img_info = fp.read()
# 设置只返回前景 也就是分割出来的人像
seg_res = client.bodySeg(img_info)
labelmap = base64.b64decode(seg_res['labelmap'])
nparr = np.frombuffer(labelmap, np.uint8)
labelimg = cv2.imdecode(nparr, 1)
labelimg = cv2.resize(labelimg, (width, height), interpolation=cv2.INTER_NEAREST)
new_img = np.where(labelimg == 1, 255, labelimg)
mask_name = path + '\mask_{}.png'.format(num)
# 保存分割出来的人像
cv2.imwrite(mask_name, new_img)
print(f'======== 第{num}张图像分割完成 ========')
time.sleep(random.randint(1, 2))
结果如下:

五、词云生成
from wordcloud import WordCloud
import collections
import jieba
import re
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
# 读取数据
with open('存放弹幕内容的文件路径', "rt", encoding="utf-8") as f:
data = f.read()
# 文本预处理 去除一些无用的字符 只提取出中文出来
new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)
new_data = "/".join(new_data)
# 文本分词
seg_list_exact = jieba.cut(new_data, cut_all=True)
result_list = []
with open('stopwords.txt的存放路径', encoding='utf-8') as f:
con = f.read().split('\n')
stop_words = set()
for i in con:
stop_words.add(i)
for word in seg_list_exact:
# 设置停用词并去除单个词
if word not in stop_words and len(word) > 1:
result_list.append(word)
# 筛选后统计词频
word_counts = collections.Counter(result_list)
path = '保存词云图片的文件夹路径'
for num in range(521, ):
img = f'保存分割后的图像的文件夹的路径/mask_{num}.png'
# 获取蒙版图片
mask_ = 255 - np.array(Image.open(img))
# 绘制词云
plt.figure(figsize=(8, 5), dpi=200)
my_cloud = WordCloud(
background_color='black', # 设置背景颜色 默认是black
mask=mask_, # 自定义蒙版
mode='RGBA',
max_words=500,
font_path='simhei.ttf', # 设置字体 显示中文
).generate_from_frequencies(word_counts)
# 显示生成的词云图片
plt.imshow(my_cloud)
# 显示设置词云图中无坐标轴
plt.axis('off')
word_cloud_name = path + 'wordcloud_{}.png'.format(num)
my_cloud.to_file(word_cloud_name) # 保存词云图片
print(f'======== 第{num}张词云图生成 ========')
Q:stopwords.txt文件是什么?
A:就是一个固定的文件,下载下来即可。百度网盘传送门
提取码:iits
运行结果如下:


六、查看原视频中的帧率和图片尺寸
import cv2
mp4 = cv2.VideoCapture(r"这里是下载的视频所在的路径") # 读取视频
is_opened = mp4.isOpened() # 判断是否打开
print(is_opened)
fps = mp4.get(cv2.CAP_PROP_FPS) # 获取视频的帧率
print(fps)
width = mp4.get(cv2.CAP_PROP_FRAME_WIDTH) # 获取视频的宽度
height = mp4.get(cv2.CAP_PROP_FRAME_HEIGHT) # 获取视频的高度
print(str(width) + "x" + str(height))
i = 1
time_f = int(fps)
运行结果如下:

七、合成跳舞视频
import cv2
import os
# 输出视频的保存路径
video_dir = '保存视频的文件路径'
# 帧率(最好填上一步得到的帧率)
fps = 25
# 图片尺寸(最好填上一步得到的尺寸)
img_size = (1920, 1080)
fourcc = cv2.VideoWriter_fourcc('M', 'P', '4', 'V') # opencv3.0 mp4会有警告但可以播放
videoWriter = cv2.VideoWriter(video_dir, fourcc, fps, img_size)
img_files = os.listdir('词云图片所在的文件路径')
for i in range(521, 1314):
img_path = '词云图片所在的文件路径/' + 'wordcloud_{}.png'.format(i)
frame = cv2.imread(img_path)
frame = cv2.resize(frame, img_size) # 生成视频 图片尺寸和设定尺寸相同
videoWriter.write(frame) # 写进视频里
print(f'======== 按照视频顺序第{i}张图片合进视频 ========')
videoWriter.release() # 释放资源
运行结果如下:
八、加入原视频音频加以渲染
emmmm,我几个星期前刚把剪辑软件《达芬奇》删掉,于是我用的哔哩哔哩云剪辑,上传了,想看的小伙伴可以去看一下。
视频传送门
也许只有看到这篇文章并且看到这里的小伙伴才会看到这个视频吧。
九、参考博文
参考博文:传送门