python多进程与多线程实验
本篇前部分转载自:
python是单线程的,多线程有意义么
后半部分自己写。
经常遇到小伙伴提到python是单线程的,写代码的时候用多线程没有意义,今天与大家分享一下关于python的单线程与多线程、多进程相关理解。
首先 python是单线程的 这句话是不对的。
这里要提到一个概念:Python的全局解释器锁(GIL)
- GIL是什么
需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码。有名的编译器例如GCC,INTEL C++,Visual C++等。Python也一样,同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行。像其中的JPython就没有GIL。然而因为CPython是大部分环境下默认的Python执行环境。所以在很多人的概念里CPython就是Python,也就想当然的把GIL归结为Python语言的缺陷。所以这里要先明确一点:GIL并不是Python的特性,Python完全可以不依赖于GIL
import threading
import time
def test1():
for i in range(100000000):
a = 100 - i
def test2():
threads = []
t1 = threading.Thread(target=test1)
t2 = threading.Thread(target=test1)
t3 = threading.Thread(target=test1)
t4 = threading.Thread(target=test1)
threads.append(t1)
threads.append(t2)
threads.append(t3)
threads.append(t4)
threads[0].start()
threads[1].start()
threads[2].start()
threads[3].start()
threads[0].join()
threads[1].join()
threads[2].join()
threads[3].join()
if __name__ == '__main__':
t1 = time.time()
print('进程一启动时间:', time.time()) # 单线程一次:
test1()
print('单线程一次:', time.time() - t1) # 单线程一次: 3.872997760772705
test1()
print('单线程两次:', time.time() - t1) # 单线程两次: 7.738230466842651
test1()
print('单线程三次:', time.time() - t1) # 单线程三次: 11.609771013259888
test1()
print('单线程四次:', time.time() - t1) # 单线程四次: 15.493367433547974
t2 = time.time()
test2()
print('进程1多线程四次:', time.time() - t2) # 多线程四次: 15.55045747756958
print('进程一结束时间:', time.time()) # 进程结束:
这段代码执行后会发现4个线程同时执行所消耗的时间与一个线程执行消耗的时间是几乎一样的,python多线程在提高效率这块确实没用。因为上边说了,GIL的存在,与单线程处理效率是一样的。
本质是这4个线程交替轮番执行,你执行一会儿,我执行一会儿,他执行一会儿…就是非常和谐的随机在单核上执行
由于Python的GIL的限制,多线程更适合于I/O密集型应用(I/O释放了GIL,可以允许更多的并发),而不是计算密集型应用。对于后一种情况而言,为了实现更好地并行性,你需要使用多进程,以便让CPU的其他内核来执行。
- 多进程
怎么开启多进程,以及验证多进程是否会自动分配到多个CPU上单独执行呢?
我们改造上诉的代码如下,并复制4份,分别命名为:
threadTest1.py,threadTest2.py,threadTest3.py,threadTest4.py。
代码如下:
import threading
import time
def test1():
for i in range(100000000):
a = 100 - i
def test2():
threads = []
t1 = threading.Thread(target=test1)
t2 = threading.Thread(target=test1)
t3 = threading.Thread(target=test1)
t4 = threading.Thread(target=test1)
threads.append(t1)
threads.append(t2)
threads.append(t3)
threads.append(t4)
threads[0].start()
threads[1].start()
threads[2].start()
threads[3].start()
threads[0].join()
threads[1].join()
threads[2].join()
threads[3].join()
if __name__ == '__main__':
t1 = time.time()
print('进程一启动时间:', time.time()) # 单线程一次:
test2()
print('进程1多线程四次:', time.time() - t1) # 多线程四次: 15.55045747756958
print('进程一结束时间:', time.time()) # 进程结束:
然后分别快速启动则4个程序,查看运行时间,可以看到,本人旧电脑cpu四核,当4个程序同时起来时,本人的电脑CPU四核全部被占满,意思是4个进程分别自动分配到了4核上。所以已经实现并行了。
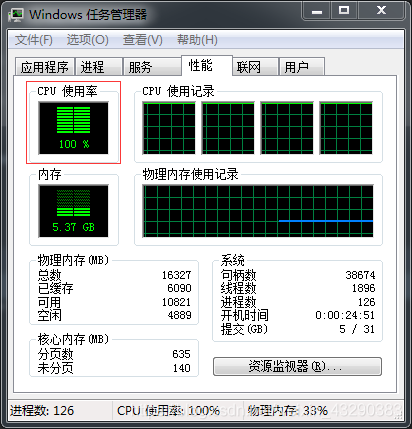
运行结果如下:单个程序运行32.36秒,全部4个程序运行完,71.65秒,除去手工启动时间延迟6秒,可以近似认为4个程序几乎同时运行了64秒。也就是说,4个程序的运行时间和单个程序的运行时间的2倍,但是不是4个程序依次执行的4倍。程序整体速度还是有提升的。为啥是两倍呢?后续解释。
进程一启动时间: 1613957587.375495
进程1多线程四次: 64.36468148231506
进程一结束时间: 1613957651.7401764
进程四启动时间: 1613957595.347951
进程4多线程四次: 63.67764210700989
进程四结束时间: 1613957659.025593
作为对比,我们让单个程序for循环4次,看看CPU的使用情况。仅需要改动一点。
if __name__ == '__main__':
t1 = time.time()
print('进程一启动时间:', time.time()) # 单线程一次:
for i in range(4):
test2()
print('进程1多线程运行四次:', time.time() - t1) # 多线程四次
print('进程一结束时间:', time.time()) # 进程结束:
运行CPU情况
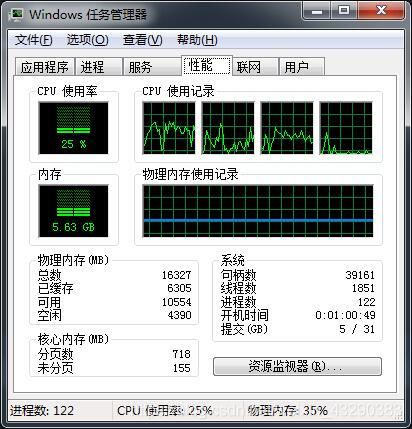
可以看到cpu只用了25%,因此只用了一个CPU核。验证了我们4个程序相当于4个进程,自动分配到了4核,一个程序分配到一核。
运行结果:
进程一启动时间: 1613959221.2839491
进程1多线程运行四次: 128.84336948394775
进程一结束时间: 1613959350.1273186
基本上是32秒的4倍。因为单独运行一个test2(),需要32秒,如下:
进程一启动时间: 1613959931.0745466
进程1多线程运行四次: 31.243787050247192
进程一结束时间: 1613959962.3183336
符合我们的预期。
所以结论:
对于多IO少密集计算的场景,用多线程没有问题,对于计算密集的场景,用多进程一样能充分利用CPU的多核特性并行处理,简单的处理就是把数据合理隔离,复制成多个程序一起跑就行了。
另外CPU打满了100%感觉性能反而会下降,我们只运行3个进程看看,单个进程需要多长时间。
进程二启动时间: 1613960078.199962
进程2多线程四次: 50.52488970756531
进程二结束时间: 1613960128.7248516
cpu情况:

看,单个进程仅需要50.52488970756531,理论上应该还是存在一定的CPU资源的抢夺,因为我的CPU是2核物理核虚拟的4核,运行2个进程呢?
cpu情况:
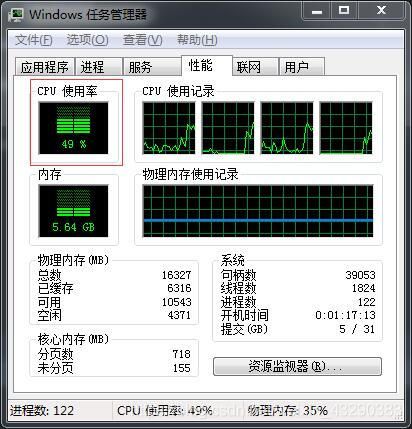
看看结果:
进程一启动时间: 1613960226.8174622
进程1多线程运行四次: 40.730329751968384
进程一结束时间: 1613960267.547792
和单个进程32秒比较接近了,因此充分利用了2个物理核,CPU争抢的情况下降。
所以结论:进程数尽量和CPU物理核的个数保持一致,进程的运行效率比较高。