2020年 前端面试问题总结:附答案
文章目录
- 面试题整理及答案
-
- 1 常规知识点
-
- 1. HTML5和CSS3的新特性
- 2. js当new一个对象时会发生什么?
- 3. 从输入url到获得页面经历的所有事情(越细越好)
- 4. 原型、原型链
- 5. 继承
- 6. ES6新特性
- 7. DOM事件和事件流
- 8. 阻止事件冒泡和移除事件绑定
- 9. 事件循环
- 10. BFC
- 11. Flex常见属性
- 12. 定时器的执行顺序或机制?
- 13. vue响应式原理
- 14. 箭头函数和普通函数的区别
- 15. call apply bind 总结
- 16. 防抖和节流
- 18. 深拷贝和浅拷贝(也会问到JSON.stringify JSON.parse这种方案的弊端)
- 19. 盒子模型
- 20. 跨域请求
- 21. get和post区别
- 22. 闭包
- 23. set和map
- 24. 网络模型以及每层的协议?
- 25. 常见的HTTP请求以及每个请求的作用?GET和POST的区别
- 26. webpack
- 27. Git 基本操作
- 28. 设计模式
- 29. HTTP之状态码
- 30. HTTP简介
- 31. HTTP之URL
- 32. HTTP之请求消息Request和响应消息Response
- 33. HTTP的工作原理
- 34. js中= = 和 = = =的区别
- 35. 面向对象,面向过程的理解
- 36. 封装、继承、多态
- 2 面试中遇到的高频题(跟上面会有重合)
- 3 低频但是需要注意的面试题
- 4 面试遇到的算法题
面试题整理及答案
1 常规知识点
1. HTML5和CSS3的新特性
- HTML
- 新增语义化标签:header、nav、article、section、aside、footer,这些标签可以使用多次,主要是针对搜索引擎的。
- 新增多媒体标签:audio、video,使用它们可以很方便的在页面嵌入音频和视频,不用再去使用flash和其他浏览器插件。
- 新增input类型:常用的有:number、tel、search。
- 新增表单属性:required、placeholder(表单的提示信息)、autocomplete(自动聚焦属性)等。
- 添加了canvas画布和svg,渲染矢量图片。
- 添加了web存储功能,localStorage和sessionStorage。
- CSS
- 新增选择器:属性选择器(E[att = “val”])权重为10、结构伪类选择器(E:nth-child(n),E:nth-of-type(n))权重为10、伪元素选择器(:before,:after)权重为1。
- 媒体查询(可以查询设备的物理像素然后进行自适应操作)。
- transform,transition,translate,scale,skelw,rotate等相关动画效果。
- box-shadow,text-shadow等特效。
- CSS3 @font-face 规则,设计师可以引入任意的字体了。
- CSS3 @keyframes 规则,可以自己创建一些动画等。
- 2D、3D转换。
- 添加了border-radius,border-image等属性。
- 盒子模型:box-sizing:content-box/border-box
2. js当new一个对象时会发生什么?
- 创建空对象;
var obj = {};- 函数中的this被指向新实例对象
ClassA.call(obj); //{}.构造函数();- 执行构造函数里面的而代码,给这个新对象添加属性和方法;
- 返回这个新对象,保存到等号左边的变量中(所以构造函数里面不需要return)。
- 构造函数不用写return语句,自动return
- 如果写了一个return :
- 如果return是基本类型值,无视这个return值,该return什么还是return什么
但是return阻止了构造函数的执行- 如果return是引用类型的值,则实际返回值为这个引用类型。
3. 从输入url到获得页面经历的所有事情(越细越好)
- 第一步:我们会在浏览器地址栏中输入一个url
- 第二步:浏览器会先查看浏览器缓存
系统缓存 -> 路由器缓存
如果缓存中存有先前访问过的数据,则会直接显示在屏幕中;没有的话,则进行第三步操作- 第三步:在发送http请求前,需要域名解析(DNS解析)【DNS域名系统】[可以将域名和IP地址相互映射的一个分布式数据库],解析获取相应的IP地址
- 第四步:浏览器向服务器发起TCP连接,与浏览器建立TCP三次握手。
- 第五步:握手成功后,浏览器向服务器发送 http 请求,请求数据包,服务器处理收到的请求,将数据返回至浏览器
- 第六步:浏览器收到 HTTP 响应,读取页面内容,浏览器渲染,解析 HTML 源码,生成DOM树,解析CSS样式,js交互
- 缓存查找
1.先从浏览器缓存里找IP,因为浏览器会缓存DNS记录一段时间
2.如没找到,再从Hosts文件查找是否有该域名和对应IP
3.如没找到,再从路由器缓存找
4.如没好到,再从DNS缓存查找
5.如果都没找到,浏览器域名服务器向根域名服务器(baidu.com)查找域名对应IP,还没找到就把请求转发到下一级,直到找到IP
- 三次握手:(TCP建立连接的过程,称为三次握手)
- 第一次,客户端向服务器发送SYN同步报文段,请求建立连接
- 第二次,服务器确认收到客户端的连接请求,并向客户端发送SYN同步报文,表示要向客户端建立连接
- 第三次,客户端收到服务器端的确认请求后,处于建立连接状态,向服务器发送确认报文
- 客户端是在收到确认请求后,先建立连接
- 服务器是在收到最后客户端的确认后,建立连接
- 发起连接请求的一定是客户端
- 注意:
两次握手的话,服务器方不确定客户端有没有收到报文,中途可能导致报文丢失而服务器不知,客户端可能就会不断发送报文,而服务器处理连接的数量是有限的,此时建立的连接会消耗大量的资源,可能会导致服务器崩溃
有连接就会有断开,那么连接是三次握手,断开就是四次挥手
- 什么是四次挥手呢?
- 第一次,A端像B端发送FIN结束报文段,准备关闭连接
- 第二次,B端确认A端的FIN,表示自己已经收到对方关闭连接的请求
中间这段时间,A端停止向B端发送数据,但是B端可以向A端发送数据,要将自己未处理完任务处理完- 第三次,B端向A端发送FIN结束报文段,准备关闭连接
- 第四次,A端确认B端的FIN,进入TIME_WAIT状态,此时A端进程已经退出,但是连接还在
当B端收到A端的ACK之后,先断开连接
当A端等待2 MSL之后,确认的B端接收到ACK后,再断开连接
- 发起断开连接请求的一端最后要进入有一个TIME_WAIT状态
- 发起连接请求的可以是客户端也可以是服务器端
4. 原型、原型链
- 原型是什么? 一个对象,我们也称为prototype为原型对象。
- 原型的作用是什么? 共享方法。
JavaScript规定,每一个构造函数都有一个prototype属性,指向另一个对象。注意这个prototype就是一个对象,这个对象的所有属性和方法,都会被构造函数所拥有。
我们可以把那些不变的方法,直接定义在prototype对象上,这样所有对象的实例就可以共享这些方法。
- 对象原型 _proto_是什么? 实例对象的一个属性。
对象都会有一个属性_proto_指向构造函数的prototype原型对象,之所以我们对象可以使用构造函数prototype原型对象的属性和方法,就是因为对象有_proto_原型的存在。
_proto_对象原型的意义就在于为对象的查找机制提供一个方向,或者说一条路线,但是它是一个非标准属性,因此实际开发中,不可以使用这个属性,他只是内部指向原型对象prototype。
- constructor是什么? 对象的一个属性,它指回构造函数本身。
对象原型(proto)和构造函数(prototype)原型对象里面就有一个属性constructor属性,constructor我们称为构造函数,因为他指回构造函数本身。
constructor主要用于记录该对象引用哪个构造函数,它可以让原型对象重新指向原来的构造函数。
- 原型链是什么? 一条由__proto__连起来的链条。
由于__proto__是任何对象都有的属性,而js里万物皆对象,所以会形成一条__proto__连起来的链条,递归访问__proto__必须最终到头,并且是null。
网上看到几张图片,感觉很清晰,拿来借鉴。
转载自知乎
https://www.zhihu.com/people/qian-duan-wo-xi-huan-ni

var a = {
};
console.log(a.prototype); //undefined
console.log(a.__proto__); //Object {}
var b = function(){
}
console.log(b.prototype); //b {}
console.log(b.__proto__); //function() {}

/*1、字面量方式*/
var a = {
};
console.log(a.__proto__); //Object {}
console.log(a.__proto__ === a.constructor.prototype); //true
/*2、构造器方式*/
var A = function(){
};
var a = new A();
console.log(a.__proto__); //A {}
console.log(a.__proto__ === a.constructor.prototype); //true
/*3、Object.create()方式*/
var a1 = {
a:1}
var a2 = Object.create(a1);
console.log(a2.__proto__); //Object {a: 1}
console.log(a.__proto__ === a.constructor.prototype); //false

var A = function(){
};
var a = new A();
console.log(a.__proto__); //A {}(即构造器function A 的原型对象)
console.log(a.__proto__.__proto__); //Object {}(即构造器function Object 的原型对象)
console.log(a.__proto__.__proto__.__proto__); //null
5. 继承
实现继承首先需要一个父类,在js中实际上是没有类的概念,在es6中class虽然很像类,但实际上只是es5上语法糖而已
// 父类
function People(name){
//属性
this.name = name || Annie
//实例方法
this.sleep=function(){
console.log(this.name + '正在睡觉')
}
}
//原型方法
People.prototype.eat = function(food){
console.log(this.name + '正在吃:' + food);
}
1.原型链继承:父类的实例作为子类的原型
- 优点:
简单易于实现,父类的新增的实例与属性子类都能访问- 缺点:
可以在子类中增加实例属性,如果要新增加原型属性和方法需要在new 父类构造函数的后面
无法实现多继承
创建子类实例时,不能向父类构造函数中传参数
function Woman(){
}
Woman.prototype= new People();
Woman.prototype.name = 'haixia';
let womanObj = new Woman();
2.借用构造函数继承(伪造对象、经典继承):复制父类的实例属性给子类
- 优点:
解决了子类构造函数向父类构造函数中传递参数
可以实现多继承(call或者apply多个父类)- 缺点:
方法都在构造函数中定义,无法复用
不能继承原型属性/方法,只能继承父类的实例属性和方法
function Woman(name){
//继承了People
People.call(this); //People.call(this,'wangxiaoxia');
this.name = name || 'renbo'
}
let womanObj = new Woman();
3.实例继承(原型式继承)
- 优点:
不限制调用方式
简单,易实现- 缺点:不能多次继承
function Wonman(name){
let instance = new People();
instance.name = name || 'wangxiaoxia';
return instance;
}
let wonmanObj = new Wonman();
4.组合式继承
- 缺点:
由于调用了两次父类,所以产生了两份实例- 优点:
函数可以复用
不存在引用属性问题
可以继承属性和方法,并且可以继承原型的属性和方法
function People(name,age){
this.name = name || 'wangxiao'
this.age = age || 27
}
People.prototype.eat = function(){
return this.name + this.age + 'eat sleep'
}
function Woman(name,age){
People.call(this,name,age)
}
Woman.prototype = new People();
Woman.prototype.constructor = Woman;
let wonmanObj = new Woman(ren,27);
wonmanObj.eat();
5.寄生组合继承:通过寄生的方式来修复组合式继承的不足,完美的实现继承
//父类
function People(name,age){
this.name = name || 'wangxiao'
this.age = age || 27
}
//父类方法
People.prototype.eat = function(){
return this.name + this.age + 'eat sleep'
}
//子类
function Woman(name,age){
//继承父类属性
People.call(this,name,age)
}
//继承父类方法
(function(){
// 创建空类
let Super = function(){
};
Super.prototype = People.prototype;
//父类的实例作为子类的原型
Woman.prototype = new Super();
})();
//修复构造函数指向问题
Woman.prototype.constructor = Woman;
let womanObj = new Woman();
6.ES6继承extend
代码量少,易懂
//class 相当于es5中构造函数
//class中定义方法时,前后不能加function,全部定义在class的protopyte属性中
//class中定义的所有方法是不可枚举的
//class中只能定义方法,不能定义对象,变量等
//class和方法内默认都是严格模式
//es5中constructor为隐式属性
//注意:子类在构造函数中使用super,必须放到this前面(必须先调用父类的构造方法,再使用子类构造方法)
class People{
constructor(name='wang',age='27'){
this.name = name;
this.age = age;
}
eat(){
console.log(`${
this.name} ${
this.age} eat food`)
}
}
//继承父类
class Woman extends People{
constructor(name = 'ren',age = '27'){
//继承父类属性
super(name, age);
}
eat(){
//继承父类方法
super.eat()
}
}
let wonmanObj=new Woman('xiaoxiami');
wonmanObj.eat();

- ES5继承和ES6继承的区别
- es5继承首先是在子类中创建自己的this指向,最后将方法添加到this中
Child.prototype=new Parent() || Parent.apply(this) || Parent.call(this)- es6继承是使用关键字先创建父类的实例对象this,最后在子类class中修改this
6. ES6新特性
- 新增let、const
- 解构赋值:数组解构,对象解构
- 箭头函数:(参数) => {执行代码}
- 类class、继承extend
- Array相关
- 剩余函数:允许我们将一个不定数量的参数表示为一个数组——…args
- Array扩展运算符——…ary,可用于合并数组,数组转参数
let ary3 = […ary1, …ary2];
ary1.push(…ary2);- 构造函数方法Array.from():将类数组或可遍历对象转换为真正的数组
let newArray = Array.from(aryLike,item=>item*2)- 实例方法:find()、findIndex()、includes()
- String的扩展方法
- 模板字符串:用反引号定义—— ``
- 实例方法:startWith()、endsWith()、repeat(n):表示将原字符串重复n次,返回一个新的字符串
- 数据结构
- set数据结构:类似于数组,但是成员的值都是唯一的,没有重复的值,可以接受数组,用来初始化
const set = new Set([1,2,3,4,5,6]);
实例方法:
add(value):返回set结构本身,
delete(value):返回一个布尔值,
has(value):返回一个布尔值,
clear(value):没有返回值,
forEach(value => cosole.log(value)):没有返回值。
7. DOM事件和事件流
- 事件发生时会在元素节点之间按照特定的顺序传播,这个传播过程即DOM事件流。
- 比如我们给一个div注册了点击事件,会有三个阶段:
1.捕获阶段
2.当前目标阶段
3.冒泡阶段- 事件冒泡:IE最早提出,时间开始由最具体的元素接收,然后逐级向上传播到DOM最顶层节点的过程。
- 事件捕获:网景最早提出,由DOM最顶层结点开始,然后逐级向下传播到最具体的元素接受的过程。

注意:
1.JS代码中只能执行捕获或者冒泡其中一个阶段。
2.onclick和attachEvent 只能得到冒泡阶段。
3.addEventListener(type,listener[,useCapture])第三个参数如果是true,表示事件冒泡阶段调用事件处理程序。
4.实际开发中我们很少使用事件捕获,我们更关注事件冒泡。
5.有些事件是没有冒泡的,比如onblur,onfocus、onmouseenter、onmousleave
6.事件冒泡有时候会带来麻烦,有时候又会帮助很巧妙的做某些事件,我们后面讲解。
8. 阻止事件冒泡和移除事件绑定
- 标准写法:利用事件对象里面的stopPropagation()方法
e.stopPropagation()- 非标准写法:IE6-8 利用事件对象cancelBuble属性
事件冒泡本身的特性,会带来的坏处,也会带来的好处,需要我们灵活掌握。程序中也有如此场景:
点击每个li都会弹出对话框, 以前需要给每个li注册事件, 而且访问DOM的次数越多,这就会延长整个页面的就绪时间。
事件委托
事件委托也称为事件代理,在jQuery里面称为事件委派。
事件委托原理
不是每个子节点单独设置事件监听器,而是事件监听设置在其父节点上,然后利用冒泡原理影响设置每个子节点。(面试)
以上案例:给ul注册点击事件,然后利用事件对象的target来找到当前点击的li,因为点击li,事件会冒泡到ul上,ul有注册事件,就会触发事件监听器。
事件委托的作用
我们只操作了一次DOM,提高了程序的性能。
- 监听事件的绑定与移除主要是addEventListener和removeEventListener的运用。
9. 事件循环
其实,event loop用简单点的话去解释,就是:
1、先执行主线程
2、遇到宏队列(macrotask)放到宏队列(macrotask)
3、遇到微队列(microtask)放到微队列(microtask)
4、主线程执行完毕
5、执行微队列(microtask),微队列(microtask)执行完毕
6、执行一次宏队列(macrotask)中的一个任务,执行完毕
7、执行微队列(microtask),执行完毕 8、依次循环。。。
这个过程,其实就是我们具体要说的js事件循环机制(event loop)。
先用一张图来表示同步和异步的执行:

同步和异步任务分别进入不同的执行环境,同步的进入主线程,即主执行栈,异步的进入任务队列。主线程内的任务执行完毕为空,会去任务队列读取对应的任务,推入主线程执行。 上述过程的不断重复就是我们说的 Event Loop (事件循环)。

task分为两大类, 分别是 Macro Task (宏任务)和 Micro Task(微任务), 并且每个宏任务结束后, 都要清空所有的微任务,这里的 Macro Task也是我们常说的 task ,有些文章并没有对其做区分,后面文章中所提及的task皆看做宏任务( macro task)。
- 宏任务主要包含:script( 整体代码)、setTimeout、setInterval、I/O、UI 交互事件、setImmediate(Node.js 环境)
- 微任务主要包含:Promise、MutaionObserver、process.nextTick(Node.js 环境)
console.log('script start');
setTimeout(function() {
console.log('timeout1');
}, 10);
new Promise(resolve => {
console.log('promise1');
resolve();
setTimeout(() => console.log('timeout2'), 10);
}).then(function() {
console.log('then1')
})
console.log('script end');
//其输出的顺序依次是:
//script start, promise1, script end, then1, timeout1, timeout2
10. BFC
- BFC 即 Block Formatting Contexts (块级格式化上下文),它属于定位方案的普通流。(普通流、浮动、绝对定位)
- 具有 BFC 特性的元素可以看作是隔离了的独立容器,容器里面的元素不会在布局上影响到外面的元素,并且 BFC 具有普通容器所没有的一些特性。
- 通俗一点来讲,可以把 BFC 理解为一个封闭的大箱子,箱子内部的元素无论如何翻江倒海,都不会影响到外部。
- BFC是一个独立的布局环境,其中的元素布局是不受外界的影响,并且在一个BFC中,块盒与行盒(行盒由一行中所有的内联元素所组成)都会垂直的沿着其父元素的边框排列。
11. Flex常见属性
- Flex 是 Flexible Box 的缩写,意为"弹性布局",用来为盒状模型提供最大的灵活性。
任何一个容器都可以指定为 Flex 布局。- 注意,设为 Flex 布局以后,子元素的float、clear和vertical-align属性将失效。
/*属性*/
/*属性决定主轴的方向(即项目的排列方向)。*/
flex-direction : row | row-reverse | column | column-reverse;
/*默认情况下,项目都排在一条线(又称"轴线")上。flex-wrap属性定义,如果一条轴线排不下,如何换行。*/
flex-wrap : nowrap | wrap | wrap-reverse;
/*flex-flow属性是flex-direction属性和flex-wrap属性的简写形式,默认值为row nowrap。*/
flex-flow : row nowrap
/*justify-content属性定义了项目在主轴上的对齐方式。*/
justify-content : flex-start | flex-end | center | space-between | space-around;
/*align-items属性定义项目在交叉轴上如何对齐*/
align-items: flex-start | flex-end | center | baseline | stretch;
/*align-content属性定义了多根轴线的对齐方式。如果项目只有一根轴线,该属性不起作用。*/
align-content : flex-start | flex-end | center | space-between | space-around | stretch;
如何实现类似快手这种视频列表的瀑布流布局(一行两个) flex:1的含义
/*父节点*/
.list_cai{
display: flex; justify-content: space-around; flex-direction: row; flex-wrap: wrap;}
/*子节点*/
.list_cai .list_cai_li{
width: 45%; height:100px; border: 1px solid orange; border-radius: 20rpx;}
当 flex 取值为一个非负数字,则该数字为 flex-grow 值,flex-shrink 取 1,flex-basis 取 0%,如下是等同的:
.item {
flex: 1;}
.item {
flex-grow: 1;
flex-shrink: 1;
flex-basis: 0%;
}
附详细链接:https://www.cnblogs.com/zhus/p/7161702.html
12. 定时器的执行顺序或机制?
因为js是单线程的,浏览器遇到setTimeout或者setInterval会先执行完当前的代码块,在此之前会把定时器推入浏览器的待执行事件队列里面,等到浏览器执行完当前代码之后会看一下事件队列里面有没有任务,有的话才执行定时器的代码。所以即使把定时器的时间设置为0还是会先执行当前的一些代码。
13. vue响应式原理
- 在生成vue实例时,为对传入的data进行遍历,使用Object.defineProperty把这些属性转为getter/setter.
Object.defineProperty 是 ES5 中一个无法识别的特性,这也就是 Vue 不支持 IE8 以及更低版本浏览器的原因。- 每个vue实例都有一个watcher实例,它会在实例渲染时记录这些属性,并在setter触发时重新渲染。

- 详细
- 在 new Vue() 后, Vue 会调用_init 函数进行初始化,也就是init 过程,在 这个过程Data通过Observer转换成了getter/setter的形式,来对数据追踪变化,当被设置的对象被读取的时候会执行getter 函数,而在当被赋值的时候会执行 setter函数。
- 当外界通过Watcher读取数据时,会触发getter从而将Watcher添加到依赖中。
- 在修改对象的值的时候,会触发对应的setter, setter通知之前依赖收集得到的 Dep 中的每一个 Watcher,告诉它们自己的值改变了,需要重新渲染视图。这时候这些 Watcher就会开始调用 update 来更新视图。

14. 箭头函数和普通函数的区别
- 普通函数在es5中就有了,箭头函数是es6中出现的函数形式
- 箭头函数单条处理可以省略return和{大括号};单个参数可以省略(小括号)
- 箭头函数不能作为构造函数 不能new。会报错;
- 箭头函数不绑定arguments,但是可使用…rest参数
- this代表不一样:
箭头函数,this代表上层对象,若无自定义上层,则代表window。
普通函数,this代表当前对象。- 箭头函数没有原型属性:
- 箭头函数bind()、call()、apply()均无法改变指向。
15. call apply bind 总结
- 相同点:都可以改变函数内部的this指向
- 区别点:
- call和apply 会调用函数,并且改变函数内部this指向
- call 和 apply 传递参数aru1,aru2,。。。形式 apply必须数组形式[arg]
- bind不会调用函数,可以改变函数内部this指向
- 主要引用场景:
- call经常做继承
- apply经常跟数组有关系,比如借助于数学对象实现数组最大值最小值
- bind 不调用函数,但是还想改变this指向,比如改变定时器内部的this指向。
16. 防抖和节流
- 防抖
触发高频事件后n秒内函数只会执行一次,如果n秒内高频事件再次被触发,则重新计算时间
思路:- 每次触发事件时都取消之前的延时调用方法
function debounce(fn) {
let timeout = null; // 创建一个标记用来存放定时器的返回值
return function () {
clearTimeout(timeout); // 每当用户输入的时候把前一个 setTimeout clear 掉
timeout = setTimeout(() => {
// 然后又创建一个新的 setTimeout, 这样就能保证输入字符后的 interval 间隔内如果还有字符输入的话,就不会执行 fn 函数
fn.apply(this, arguments);
}, 500);
};
}
function sayHi() {
console.log('防抖成功');
}
var inp = document.getElementById('inp');
inp.addEventListener('input', debounce(sayHi)); // 防抖
- 节流
高频事件触发,但在n秒内只会执行一次,所以节流会稀释函数的执行频率- 思路:
每次触发事件时都判断当前是否有等待执行的延时函数
function throttle(fn) {
let canRun = true; // 通过闭包保存一个标记
return function () {
if (!canRun) return; // 在函数开头判断标记是否为true,不为true则return
canRun = false; // 立即设置为false
setTimeout(() => {
// 将外部传入的函数的执行放在setTimeout中
fn.apply(this, arguments);
// 最后在setTimeout执行完毕后再把标记设置为true(关键)表示可以执行下一次循环了。当定时器没有执行的时候标记永远是false,在开头被return掉
canRun = true;
}, 500);
};
}
function sayHi(e) {
console.log(e.target.innerWidth, e.target.innerHeight);
}
window.addEventListener('resize', throttle(sayHi));
- ES6新增数据类型
Symbol 类型(基本)
Set 类型(复杂)
Map 类型(复杂)
WeakSet 类型(复杂)
WeakMap 类型(复杂)
TypedArray 类型(复杂)
18. 深拷贝和浅拷贝(也会问到JSON.stringify JSON.parse这种方案的弊端)
- javascript变量包含两种不同数据类型的值:基本类型和引用类型。
- 基本类型值指的是简单的数据段,包括es6里面新增的一共是有6种,具体如下:number、string、boolean、null、undefined、symbol。
- 引用类型值指那些可能由多个值构成的对象,只有一种如下:object。
在将一个值赋给变量时,解析器必须确定这个值是基本类型值还是引用类型值。
- javascript的变量的存储方式:栈(stack)和堆(heap)。
- 栈:自动分配内存空间,系统自动释放,里面存放的是基本类型的值和引用类型的地址
- 堆:动态分配的内存,大小不定,也不会自动释放。里面存放引用类型的值。
- 基本类型与引用类型最大的区别实际就是: 传值与传址 的区别
- 值传递:基本类型采用的是值传递。
- 地址传递:引用类型则是地址传递,将存放在栈内存中的地址赋值给接收的变量。
- 浅拷贝只是拷贝一层,更深层次对象级别的只拷贝引用
- 深拷贝拷贝多层,每一级别的数据都会拷贝
- Object.assign(target,…sources) es6新增方法可以浅拷贝
注意:ES6新增了Object.assign() 方法
Object.assign() 只是一级属性复制,比浅拷贝多深拷贝了一层而已。
深拷贝实现方法
(1)for循环
//深拷贝
var obj = {
id: 1;
name: 'andy';
msg: {
age: 18
};
coloe: ['pink','red']
};
var o = {
};
//封装函数
function deepCopy(newobj, oldobj){
for(var k in obj){
//判断我们的属性值属于哪种数据类型
//1.获取属性值 oldobj[k]
var item = oldobj[k];
//2. 判断这个值是否是数组 //数组也是对象,所以应该先判断数组
if(item instanceof Array){
newobj[k] = [];
deepcopy(newobj[k],item)
}else if(item instanceof Object){
//3. 判断这个值是否是对象
newobj[k] = {
};
deepCopy(newobj[k],item)
}else{
//4.属于简单数据类型
newobj[k] = item;
}
}
}
deepCopy(o,obj);
console.log(o);
(2)JSON.parse(JSON.stringify())
- 原理:用JSON.stringify()将对象转成字符串,再用JSON.parse()把字符串解析成对象。
var obj1 = {
'name' : 'zhangsan',
'language' : [1,[2,3],[4,5]],
};
var obj2 = JSON.parse(JSON.stringify(obj1));
obj2.name = "lisi";
obj2.language[1] = ["二","三"];
console.log('obj1',obj1)
console.log('obj2',obj2)
- 缺点:这种方法可以实现数组和对象和基本数据类型的深拷贝,但不能处理函数。因为JSON.stringify()方法是将一个javascript值转换我一个JSON字符串,不能接受函数。
- 其他影响如下:
- 如果对象中有时间对象,那么用该方法拷贝之后的对象中,时间是字符串形式而不是时间对象
- 如果对象中有RegExp、Error对象,那么序列化的结果是空
- 如果对象中有函数或者undefined,那么序列化的结果会把函数或undefined丢失
- 如果对象中有NAN、infinity、-infinity,那么序列化的结果会变成null
- JSON.stringfy()只能序列化对象的可枚举自有属性,如果对象中有是构造函数生成的,那么拷贝后会丢弃对象的constructor
- 如果对象中存在循环引用也无法正确实现深拷贝
19. 盒子模型

box-sizing 用来指定盒模型
box-sizing: content-box; // 盒子大小为width+padding+border
box-sizing: border-box; // 盒子大小为width
20. 跨域请求
- 造成跨域的原因
浏览器的同源策略会导致跨域,这里同源策略又分为以下两种
- DOM同源策略:禁止对不同源页面DOM进行操作。这里主要场景是iframe跨域的情况,不同域名的iframe是限制互相访问的。
- XmlHttpRequest同源策略:禁止使用XHR对象向不同源的服务器地址发起HTTP请求。
- 只要协议、域名、端口有任何一个不同,都被当作是不同的域,之间的请求就是跨域操作。
- 为什么要有跨域限制
跨域限制主要是为了安全考虑。
- AJAX同源策略主要用来防止CSRF攻击。如果没有AJAX同源策略,相当危险,我们发起的每一次HTTP请求都会带上请求地址对应的cookie,那么可以做如下攻击:
- 用户登录了自己的银行页面 http://mybank.com,http://mybank.com向用户的cookie中添加用户标识。
- 用户浏览了恶意页面 http://evil.com。执行了页面中的恶意AJAX请求代码。
- http://evil.com向http://mybank.com发起AJAX
- HTTP请求,请求会默认把http://mybank.com对应cookie也同时发送过去。
- 银行页面从发送的cookie中提取用户标识,验证用户无误,response中返回请求数据。此时数据就泄露了。
- 而且由于Ajax在后台执行,用户无法感知这一过程。
- DOM同源策略也一样,如果iframe之间可以跨域访问,可以这样攻击:
- 做一个假网站,里面用iframe嵌套一个银行网站 http://mybank.com。
- 把iframe宽高啥的调整到页面全部,这样用户进来除了域名,别的部分和银行的网站没有任何差别。
- 这时如果用户输入账号密码,我们的主网站可以跨域访问到http://mybank.com的dom节点,就可以拿到用户的输入了,那么就完成了一次攻击。
所以说有了跨域跨域限制之后,我们才能更安全的上网了。
- 跨域的解决方式
- 跨域资源共享(CORS)
通过在HTTP Header中加入扩展字段,服务器在相应网页头部加入字段表示允许访问的domain和HTTP method,客户端检查自己的域是否在允许列表中,决定是否处理响应。
实现的基础是JavaScript不能够操作HTTP Header。某些浏览器插件实际上是具有这个能力的。
服务器端在HTTP的响应头中加入(页面层次的控制模式):
Access-Control-Allow-Origin: example.com
Access-Control-Request-Method: GET, POST
Access-Control-Allow-Headers: Content-Type, Authorization, Accept, Range, Origin
Access-Control-Expose-Headers: Content-Range
Access-Control-Max-Age: 3600
//多个域名之间用逗号分隔,表示对所示域名提供跨域访问权限。"*"表示允许所有域名的跨域访问。
客户端可以有两种行为:
- 发送OPTIONS请求,请求Access-Control信息。如果自己的域名在允许的访问列表中,则发送真正的请求,否则放弃请求发送。
- 直接发送请求,然后检查response的Access-Control信息,如果自己的域名在允许的访问列表中,则读取response body,否则放弃。
本质上服务端的response内容已经到达本地,JavaScript决定是否要去读取。
- jsonp实现跨域
基本原理就是通过动态创建script标签,然后利用src属性进行跨域。
<script>
//定义一个fun函数
function fun(data) {
console.log(data);
}
// 创建一个脚本,并且告诉后端回调函数名叫fun
var body= document.getElementsByTagName('body')[0];
var script= document.createElement('script');
script.type= 'text/javascript';
script.src= 'demo.js?callback=fun';
body.appendChild(script);
</script>
- 服务器代理
浏览器有跨域限制,但是服务器不存在跨域问题,所以可以由服务器请求所要域的资源再返回给客户端。
参考链接:https://www.cnblogs.com/huang-yc/p/9858384.html
21. get和post区别
- 数据的传输
get把请求的数据放在url上,即HTTP协议头上,其格式为:
以?分割URL和传输数据,参数之间以&相连。
数据如果是英文字母/数字,原样发送,
如果是空格,转换为+,
如果是中文/其他字符,则直接把字符串用BASE64加密,及“%”加上“字符串的16进制ASCII码”。
post把数据放在HTTP的包体内(requrest body)。- 传输数据的长度
get提交的数据最大是2k(原则上url长度无限制,那么get提交的数据也没有限制咯?限制实际上取决于浏览器,(大多数)浏览器通常都会限制url长度在2K个字节,即使(大多数)服务器最多处理64K大小的url。也没有卵用。)。
post理论上没有限制。实际上IIS4中最大量为80KB,IIS5中为100KB。- TCP数据包
GET产生一个TCP数据包,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);
POST产生两个TCP数据包,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。- 回退
GET在浏览器回退时是无害的,POST会再次提交请求。- bookmark 收藏为书签
GET产生的URL地址可以被Bookmark,而POST不可以。
HTTP POST 可以被收藏,但由于书签仅包括URL,所有的形式参数都将丢失。这通常意味着Web服务器不知道该如何处理请求,因为它期望一些表单参数。如果您通过GET请求提交表单,所有表单参数将进入URL(在?之后),因此书签将包含Web服务器第二次重建页面所需的所有信息(可能除了cookies之外,web服务器更有可能正常处理)- cache 缓存
GET请求会被浏览器主动cache,而POST不会,除非手动设置。
HTTP缓存的基本目的就是使应用执行的更快,更易扩展,但是HTTP缓存通常只适用于idempotent request(可以理解为查询请求,也就是不更新服务端数据的请求),这也就导致了在HTTP的世界里,一般都是对Get请求做缓存,Post请求很少有缓存。- 编码方式
GET请求只能进行url编码,而POST支持多种编码方式。- 浏览记录
GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。- 参数类型限制
GET只接受ASCII字符的参数的数据类型,而POST没有限制
22. 闭包
- 什么是闭包?
闭包(closure)指有权访问另一个函数作用域中变量的函数。简单理解就是,一个作用域可以访问另外一个函数内部的局部变量。- 闭包的主要作用?
延伸了变量的作用范围
// 利用闭包的方式得到当前小li的索引号
for(var i = 0; i < lis.length; i++){
//利用for循环创建了4个立即执行函数 函数式是一个作用域
//立即执行函数也称为小闭包,因为立即执行函数里面的任何一个函数都可以使用它的i这个变量
(function(i){
//console.log(i);
lis[i].onclick = function(){
console.log(this.index);
}
})(i);
}
23. set和map
| set | weakset | map | weakmap | |
|---|---|---|---|---|
| 定义 | 类似于数组,但是成员的值都是唯一的,没有重复的值。 Set本身是一个构造函数,使用new Set()创建Set实例。 | 它与 Set 有两个区别。首先,WeakSet 的成员只能是对象,而不能是其他类型的值。其次,WeakSet 中的对象都是弱引用,即垃圾回收机制不考虑 WeakSet 对该对象的引用,也就是说,如果其他对象都不再引用该对象,那么垃圾回收机制会自动回收该对象所占用的内存,不考虑该对象还存在于 WeakSet 之中。WeakSet 是一个构造函数,可以使用new命令,创建 WeakSet 数据结构。 | Map类似于对象,但是键的范围不限于字符串,各种类型的值都可以作为键值。使用new Map()创建Map实例 | WeakMap与Map的区别有两点。首先,WeakMap只接受对象作为键名(null除外),不接受其他类型的值作为键名。其次,WeakMap的键名所指向的对象,不计入垃圾回收机制。WeakMap的专用场合就是,它的键所对应的对象,可能会在将来消失。WeakMap结构有助于防止内存泄漏。注意,WeakMap 弱引用的只是键名,而不是键值。键值依然是正常引用。 |
| size属性 | set.size | - | map.size | - |
| 新增 | set.add(val); 返回Set结构本身 | WeakSet.add(value):向 WeakSet 实例添加一个新成员。 | map.set(key, val); 返回Map结构本身 | set() |
| 删除 | set.delete(val); 返回布尔值,表示是否删除成功 | WeakSet.delete(value):清除 WeakSet 实例的指定成员。 | map.delete(key); 返回布尔值,表示是否删除成功 | delet() |
| 是否包含某个值 | set.has(val); 返回布尔值,表示是否包含这个值 | WeakSet.has(value):返回一个布尔值,表示某个值是否在 WeakSet 实例之中。 | map.has(val); 返回布尔值,表示是否包含这个键 | has() |
| 获取值 | - | - | map.get(key); 返回对应键值的值,没有则返回undefined | get() |
| 清除所有成员 | set.clear(); 没有返回值 | - | map.clear(); 没有返回值 | - |
| 遍历 | 1. 遍历键名:for(let item of set.keys()){ };2. 遍历键值: for(let item of set.values()){ };3. 遍历键值对: for(let item of set.entries()){ };4. 使用回调遍历每个成员: set.forEach(); |
WeakSet 不能遍历,是因为成员都是弱引用,随时可能消失,遍历机制无法保证成员的存在,很可能刚刚遍历结束,成员就取不到了。WeakSet 的一个用处,是储存 DOM 节点,而不用担心这些节点从文档移除时,会引发内存泄漏。 | 1.for(let item of map.keys()){ };2. for(let item of map.values()){ };3. for(let item of map.entries()){ };4. map.forEach() ; |
- |
应用:
使用 Set 可以很容易地实现并集(Union)、交集(Intersect)和差集(Difference)。
let a = new Set([1, 2, 3]);
let b = new Set([4, 3, 2]);
// 并集
let union = new Set([...a, ...b]);
// Set {1, 2, 3, 4}
// 交集
let intersect = new Set([...a].filter(x => b.has(x)));
// set {2, 3}
// (a 相对于 b 的)差集
let difference = new Set([...a].filter(x => !b.has(x)));
// Set {1}
扩展运算符和 Set 结构相结合,就可以去除数组的重复成员。
let arr = [3, 5, 2, 2, 5, 5];
let unique = [...new Set(arr)];
// [3, 5, 2]
而且,数组的map和filter方法也可以间接用于 Set 了。
let set = new Set([1, 2, 3]);
set = new Set([...set].map(x => x * 2));
// 返回Set结构:{2, 4, 6}
let set = new Set([1, 2, 3, 4, 5]);
set = new Set([...set].filter(x => (x % 2) == 0));
// 返回Set结构:{2, 4}
如果想在遍历操作中,同步改变原来的 Set 结构,目前没有直接的方法,但有两种变通方法。一种是利用原 Set 结构映射出一个新的结构,然后赋值给原来的 Set 结构;另一种是利用Array.from方法。
// 方法一
let set = new Set([1, 2, 3]);
set = new Set([...set].map(val => val * 2));
// set的值是2, 4, 6
// 方法二
let set = new Set([1, 2, 3]);
set = new Set(Array.from(set, val => val * 2));
// set的值是2, 4, 6
Map 转为数组,Map 转为数组最方便的方法,就是使用扩展运算符(...)。
const myMap = new Map()
.set(true, 7)
.set({
foo: 3}, ['abc']);
[...myMap]
// [ [ true, 7 ], [ { foo: 3 }, [ 'abc' ] ] ]
数组 转为 Map,将数组传入 Map 构造函数,就可以转为 Map。
new Map([
[true, 7],
[{
foo: 3}, ['abc']]
])
// Map {
// true => 7,
// Object {foo: 3} => ['abc']
// }
对象转为 Map对象转为 Map 可以通过Object.entries()。
let obj = {
"a":1, "b":2};
let map = new Map(Object.entries(obj));
24. 网络模型以及每层的协议?

25. 常见的HTTP请求以及每个请求的作用?GET和POST的区别
GET: 用于请求访问已经被URI(统一资源标识符)识别的资源,可以通过URL传参给服务器。
POST:用于传输信息给服务器,主要功能与GET方法类似,但一般推荐使用POST方式。
PUT: 传输文件,报文主体中包含文件内容,保存到对应URI位置。
HEAD: 获得报文首部,与GET方法类似,只是不返回报文主体,一般用于验证URI是否有效。
DELETE:删除文件,与PUT方法相反,删除对应URI位置的文件。
OPTIONS:查询相应URI支持的HTTP方法。


26. webpack

不像大多数的模块打包机,webpack是收把项目当作一个整体,通过一个给定的的主文件,webpack将从这个文件开始找到你的项目的所有依赖文件,使用loaders处理它们,最后打包成一个或多个浏览器可识别的js文件
- install:首先添加我们即将使用的包:
- entry: 用来写入口文件,它将是整个依赖关系的根
- output: 即使入口文件有多个,但是只有一个输出配置
- loader的作用:
- 实现对不同格式的文件的处理,比如说将scss转换为css,或者typescript转化为js
- 转换这些文件,从而使其能够被添加到依赖图中
loader是webpack最重要的部分之一,通过使用不同的Loader,我们能够调用外部的脚本或者工具,实现对不同格式文件的处理,loader需要在webpack.config.js里边单独用module进行配置,- 这里介绍几个常用的loader:
1.babel-loader: 让下一代的js文件转换成现代浏览器能够支持的JS文件。
2.css-loader,style-loader:两个建议配合使用,用来解析css文件,能够解释@import,url()如果需要解析less就在后面加一个less-loader
3.file-loader: 生成的文件名就是文件内容的MD5哈希值并会保留所引用资源的原始扩展名
4.url-loader: 功能类似 file-loader,但是文件大小低于指定的限制时,可以返回一个DataURL事实上,在使用less,scss,stylus这些的时候,npm会提示你差什么插件,差什么,你就安上就行了
- Plugins
plugins和loader很容易搞混,说都是外部引用有什么区别呢? 事实上他们是两个完全不同的东西。这么说loaders负责的是处理源文件的如css、jsx,一次处理一个文件。而plugins并不是直接操作单个文件,它直接对整个构建过程起作用下面列举了一些我们常用的plugins和他的用法
ExtractTextWebpackPlugin: 它会将入口中引用css文件,都打包都独立的css文件中,而不是内嵌在js打包文件中。
27. Git 基本操作
Git 的工作就是创建和保存你项目的快照及与之后的快照进行对比。
Git 常用的是以下 6 个命令:git clone、git push、git add 、git commit、git checkout、git pull。

- 说明:
workspace:工作区
staging area:暂存区/缓存区
local repository:或本地仓库
remote repository:远程仓库
下表列出了 git 的常见命令:
| 初始化 | |
|---|---|
| git init | git init |
| git clone | 拷贝一份远程仓库,也就是下载一个项目。 |
| 提交与修改 | |
|---|---|
| git add | 添加文件到仓库 |
| git status | 查看仓库当前的状态,显示有变更的文件。 |
| git diff | 比较文件的不同,即暂存区和工作区的差异。 |
| git commit | 提交暂存区到本地仓库。 |
| git reset | 回退版本。 |
| git rm | 删除工作区文件。 |
| git mv | 移动或重命名工作区文件。 |
| 提交日志 | |
|---|---|
| git log | 查看历史提交记录 |
| git blame | 以列表形式查看指定文件的历史修改记录 |
| 远程操作 | |
|---|---|
| git remote | 远程仓库操作 |
| git fetch | 从远程获取代码库 |
| git pull | 下载远程代码并合并 |
| git push | 上传远程代码并合并 |
28. 设计模式
总体来说设计模式分为三大类:
创建型模式,共五种:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。
结构型模式,共七种:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
行为型模式,共十一种:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
其实还有两类:并发型模式和线程池模式。
下面介绍几种模式
- 工厂模式
在工厂模式中,我们在创建对象时不会对客户端暴露创建逻辑,并且是通过使用一个共同的接口来指向新创建的对象。
应用实例: 您需要一辆汽车,可以直接从工厂里面提货,而不用去管这辆汽车是怎么做出来的,以及这个汽车里面的具体实现。- 代理模式
在代理模式(Proxy Pattern)中,一个类代表另一个类的功能。我们创建具有现有对象的对象,以便向外界提供功能接口。
应用实例:买火车票不一定在火车站买,也可以去代售点。- 中介者模式
中介者模式(Mediator Pattern)是用来降低多个对象和类之间的通信复杂性。这种模式提供了一个中介类,该类通常处理不同类之间的通信,并支持松耦合,使代码易于维护。
应用实例:MVC 框架,其中C(控制器)就是 M(模型)和 V(视图)的中介者。
29. HTTP之状态码
状态代码有三位数字组成,第一个数字定义了响应的类别,共分五种类别:
1xx:指示信息–表示请求已接收,继续处理
2xx:成功–表示请求已被成功接收、理解、接受
3xx:重定向–要完成请求必须进行更进一步的操作
4xx:客户端错误–请求有语法错误或请求无法实现
5xx:服务器端错误–服务器未能实现合法的请求
常见状态码:
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
30. HTTP简介
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。
HTTP是一个基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)。
HTTP是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。
HTTP协议工作于客户端-服务端架构为上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。
主要特点
- 简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
- 灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
- 无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
- 无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
- 支持B/S及C/S模式。
31. HTTP之URL
HTTP使用统一资源标识符(Uniform Resource Identifiers, URI)来传输数据和建立连接。URL是一种特殊类型的URI,包含了用于查找某个资源的足够的信息
URL,全称是UniformResourceLocator, 中文叫统一资源定位符,是互联网上用来标识某一处资源的地址。以下面这个URL为例,介绍下普通URL的各部分组成:
http://www.aspxfans.com:8080/news/index.asp?boardID=5&ID=24618&page=1#name
从上面的URL可以看出,一个完整的URL包括以下几部分:
- 协议部分:该URL的协议部分为“http:”,这代表网页使用的是HTTP协议。在Internet中可以使用多种协议,如HTTP,FTP等等本例中使用的是HTTP协议。在"HTTP"后面的“//”为分隔符
- 域名部分:该URL的域名部分为“www.aspxfans.com”。一个URL中,也可以使用IP地址作为域名使用
- 端口部分:跟在域名后面的是端口,域名和端口之间使用“:”作为分隔符。端口不是一个URL必须的部分,如果省略端口部分,将采用默认端口
- 虚拟目录部分:从域名后的第一个“/”开始到最后一个“/”为止,是虚拟目录部分。虚拟目录也不是一个URL必须的部分。本例中的虚拟目录是“/news/”
- 文件名部分:从域名后的最后一个“/”开始到“?”为止,是文件名部分,如果没有“?”,则是从域名后的最后一个“/”开始到“#”为止,是文件部分,如果没有“?”和“#”,那么从域名后的最后一个“/”开始到结束,都是文件名部分。本例中的文件名是“index.asp”。文件名部分也不是一个URL必须的部分,如果省略该部分,则使用默认的文件名
- 锚部分:从“#”开始到最后,都是锚部分。本例中的锚部分是“name”。锚部分也不是一个URL必须的部分
- 参数部分:从“?”开始到“#”为止之间的部分为参数部分,又称搜索部分、查询部分。本例中的参数部分为“boardID=5&ID=24618&page=1”。参数可以允许有多个参数,参数与参数之间用“&”作为分隔符。
32. HTTP之请求消息Request和响应消息Response
客户端发送一个HTTP请求到服务器的请求消息包括以下格式:
请求行(request line)、请求头部(header)、空行和请求数据四个部分组成。
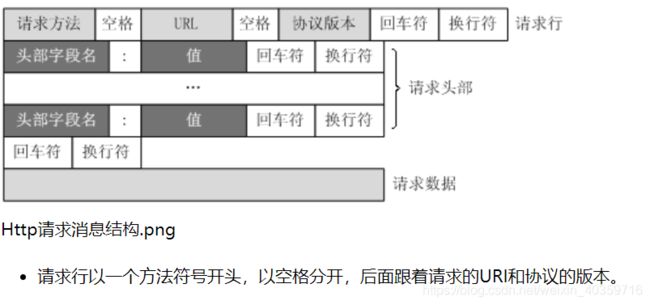
一般情况下,服务器接收并处理客户端发过来的请求后会返回一个HTTP的响应消息。
HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文。

33. HTTP的工作原理
以下是 HTTP 请求/响应的步骤:
1、客户端连接到Web服务器
一个HTTP客户端,通常是浏览器,与Web服务器的HTTP端口(默认为80)建立一个TCP套接字连接。例如,http://www.oakcms.cn。2、发送HTTP请求
通过TCP套接字,客户端向Web服务器发送一个文本的请求报文,一个请求报文由请求行、请求头部、空行和请求数据4部分组成。3、服务器接受请求并返回HTTP响应
Web服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读取。一个响应由状态行、响应头部、空行和响应数据4部分组成。4、释放连接TCP连接 若connection
模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;若connection
模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求;5、客户端浏览器解析HTML内容
客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示。
34. js中= = 和 = = =的区别
简单来说: = = 代表相同, = = =代表严格相同, 为啥这么说呢,
这么理解: 当进行双等号比较时候: 先检查两个操作数数据类型,如果相同, 则进行= = = 比较, 如果不同, 则愿意为你进行一次类型转换, 转换成相同类型后再进行比较, 而===比较时, 如果类型不同,直接就是false.
// 0 是逻辑的 false;1 是逻辑的 true;
// 空字符串是逻辑的 false;null 是逻辑的 false
// NaN==任何 都是false
0 == [] // true
'0' == [] // false
'' == [] // true
100 == "100" // true
1 == true // true
null == null // true
undefined == undefined // true
null == undefined // true
true == "20" // false
"1" == "01" // false,此处等号两边值得类型相同,不要再转换类型了!!
NaN == NaN // false,NaN和所有值包括自己都不相等。
100 === "100" // false
1 === true // false
NaN === NaN // false
null === undefined // false
'abc' === "abc" // true
false === false // true
null === null // true
undefined === undefined // true
35. 面向对象,面向过程的理解
首先先举一个简单的例子:
将水果放入冰箱
面向过程:
打开冰箱–》存储水果 --》关上冰箱
对于面向过程思想,强调的是过程(动作)。
面向对象:
冰箱打开–》冰箱存储水果–》冰箱关上
对于面向对象,强调的是对象
面向过程
优点:性能比面向对象高,因为类调用时需要实例化,开销比较大,比较消耗资源,比如单片机、嵌入式开发、Linux/Unix等一般采用面向过程开发,性能是最重要的因素。
缺点:没有面向对象易维护、易复用、易扩展
面向对象
优点:易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合的系统,使系统更加灵活、更加易于维护
缺点:性能比面向过程低
举例子:
例如设计一个五子棋:面向过程的思路就是首先分析问题的步骤:
1.开始游戏;
2.黑子先走;
3.绘制棋盘画面;
4.判断输赢;
5.白子走;
6.绘制棋盘;
7.判断输赢;
8.返回到步骤2;
9.输出最后的结果;
就这样一步步的实现,问题就解决了;
而面向对象则是从另外一个思路来设计解决问题:
1.玩家系统:黑白ABCD都是玩家,所以属性,步骤功能一样;
2.绘制棋盘系统;
3.规则系统:决定哪个先走,判断输赢等操作;
可以看出面向对象是以功能来划分,而不是步骤,黑子落棋后通知白棋棋盘发生变化,绘制棋盘系统就开始把变化绘制出来,规则系统则判定结果;赢了则返回,否则由白字继续走;
如果要加一个悔棋功能,面向过程则需要改动很多地方,黑子撤回棋,棋盘变化,然后载绘制,再判断,可能很多要变化;随着功能的越来越多,系统无法应付功能需求的规则的复杂而膨胀,最终导致奔溃;但是面向对象只需要得到悔棋命令后,绘制棋盘系统将棋盘重新绘制,调用规则系统判定即可,减少了大的改动;保证了面向对象程序的可扩展性;
36. 封装、继承、多态
首先举例子:
封装——学生类:有学号、姓名、图书馆借书功能
继承——本科生、硕士研究生、博士都继承自学生类
多态——因为不同类型的学生可借阅的书的数量不同,所以本科生、硕士、博士都对自己的借书功能进行了重写,因此不同类型的学生在调用图书馆借书功能的时候,都会按照各自重写之后的借书功能来使用,最终呈现出不同的结果
封装:把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。
继承:它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。其继承的过程,就是从一般到特殊的过程。
多态:“一个接口,多种方法”,同一操作作用于不同的对象,可以有不同的解释,产生不同的执行结果。
2 面试中遇到的高频题(跟上面会有重合)
- 事件循环
- 原型链
- vue响应式原理
- HTTP缓存
- 前端性能优化
- vue3解决什么问题
- Vue 为什么不能检测数组和对象的变化,怎么处理(为什么通过索引操作数组不能触发响应式)
- vue router原理
- v-model实现原理
- vue.nexttick
- https的过程
- 性能优化
- promise(基本上要求可以手写Promise.all方法,这个问的最多)
- async/await
- vue虚拟dom & diff算法
- 跨域形成原因以及解决方案
- 深拷贝和浅拷贝(也会问到JSON.stringify JSON.parse这种方案的弊端)
- 箭头函数和普通函数有什么区别
- 最近在看什么新技术
3 低频但是需要注意的面试题
- CSRF & XSS
- chrome设置小于12px字体
- node和浏览器事件循环有何不同
- webpack tree shaking
- map & set
- 前端有哪些技术(腾讯面试题,面试官会顺着你说的技术一个一个展开问)
- 实现一个call/bind(call,apply,bind区别)
- get 和 post 的区别
- BFC
- yield
- 如何给localStorage加上max-age功能
- Object.defineProperties都有那些参数,以及参数解释
- requestAnimation
- 手写原型链和js各种继承模式
- 让你重新做你做过的项目有什么可以改进的地方
- 让一个元素消失的几种做法,有何不同,对子元素的影响
- 如何遍历对象(接下来会问有何不同)
- 搜索框输入需要注意的点(其实还是在问防抖)
- 原生实现inserAfter
- 事件委托应用场景,e.target和e.currentTarget区别
- HTTP缓存,对应字段,cache-contron都有那些值
- new过程都发生了什么
4 面试遇到的算法题
- 排序算法(冒泡,快排)
- 洗牌算法
- v1.2.3 v0.3.0 这样的版本号比大小(找简单方法,不要随便写一个循环的版本)
- 广度优先遍历
- 用O(n)的复杂度合并两个有序数组
- 数组生成树形结构
var arr = [
{
id: 1, value: "节点1", p_id: 0 },
{
id: 2, value: "节点2", p_id: 1 },
{
id: 3, value: "节点3", p_id: 1 },
{
id: 4, value: "节点4", p_id: 2 },
{
id: 5, value: "节点5", p_id: 0 },
{
id: 6, value: "节点6", p_id: 5 },
{
id: 7, value: "节点7", p_id: 6 },
{
id: 8, value: "节点8", p_id: 6 },
];
// 输出
[{
"id": 1,
"value": "节点1",
"p_id": 0,
"children": [
{
"id": 2,
"value": "节点2",
"p_id": 1,
"children": [
{
"id": 4,
"value": "节点4",
"p_id": 2,
"children": []
}
]
},
{
"id": 3,
"value": "节点3",
"p_id": 1,
"children": []
}
]
},
{
"id": 5,
"value": "节点5",
"p_id": 0,
"children": [
{
"id": 6,
"value": "节点6",
"p_id": 5,
"children": [
{
"id": 7,
"value": "节点7",
"p_id": 6,
"children": []
},
{
"id": 8,
"value": "节点8",
"p_id": 6,
"children": []
}
]
}
]
}]
- 数组L型输出
// L型输出
var arr = [
['1', '2', '3'],
['4', '5', '6'],
['7', '8', '9'],
];
// 输出大致顺序 1 4 7 8 9 2 5 6 3
- 数组求排列组合
// 数组排列组合
var arr = [
['A', 'B', 'C'],
[1, 2, 3],
['X', 'Y', 'Z'],
];
// 输出类似 A1X A1Y A1Z ...
- 实现一个函数 find(obj, str),满足
var obj = {
a:{
b:{
c:1}}};
find(obj,'a.b.c') //1
find(obj,'a.d.c') //undefined
- 乒乓球比赛判断输赢(这个表达起来费劲,但是是个贴合实际开发场景的例子.不常见,但是不难)