【Python】多线程和互斥锁
文章目录
-
- 1 互斥锁的位置对函数执行情况的影响
-
- 1.1 情况一
- 1.2 情况二
- 2 线程之间的执行情况
-
- 2.1 情况一
- 2.2 情况二
- 2.3 结论
在学 Python 的时候经常对不同线程之间的执行情况感到困惑,故在此文中对该问题进行梳理,同时也会提到互斥锁的问题。
同一个进程中的不同线程之间是并发执行的,并不是真正的同时执行,而是在极短的时间内交替执行。例如:线程 1 在 CPU 中执行了 0.0001ms,之后轮到线程 2 到 CPU 中执行 0.0001ms,这样交替进行下去(当然并不是严格的“你一次我一次”这样交替的,实际上是随机进行的)。
下面通过例子进行解释
import threading
import time
# 全局变量
gl_num = 0
# 创建互斥锁
mutex = threading.Lock()
# 将该函数放入子线程1中执行,用于将全局变量循环自加1
def sum1(num):
global gl_num
for i in range(num):
mutex.acquire() # 开启互斥锁
gl_num += 1
mutex.release() # 关闭互斥锁
print("子线程1中sum1结果为:%d" % gl_num)
# 将该函数放入子线程2中执行,用于将全局变量循环自加1
def sum2(num):
global gl_num
for i in range(num):
mutex.acquire() # 开启互斥锁
gl_num += 1
mutex.release() # 关闭互斥锁
print("子线程2中sum2结果为:%d" % gl_num)
def main():
# 创建2个子线程并开始执行
t1 = threading.Thread(target=sum1, args=(1000000,))
t2 = threading.Thread(target=sum2, args=(1000000,))
t1.start()
t2.start()
# 2秒钟后执行下面的语句
time.sleep(2)
print("主线程中结果为:%d" % gl_num)
if __name__ == "__main__":
main()
1 互斥锁的位置对函数执行情况的影响
添加互斥锁的目的是为了使得互斥锁开启和关闭之间的代码成为一个整体,也就是说,CPU 要么不执行该代码;要么执行完毕后再执行其他内容;不会出现执行一半突然 CPU 去执行其他内容,之后再执行剩余部分的情况发生。即实现原子操作。
1.1 情况一
上述两个 sum 函数中互斥锁的位置均为:
mutex.acquire() # 开启互斥锁
for i in range(num):
gl_num += 1
mutex.release() # 关闭互斥锁
即将整个 for循环 视为原子操作。
由于 sum 函数的函数体几乎就只是一个 for循环 ,所以相当于整个函数为一个原子操作。
执行结果为:
![]()
但是如果去掉 time.sleep(2),则执行结果就变成了:
![]()
1.2 情况二
上述两个 sum 函数中互斥锁的位置均为:
for i in range(num):
mutex.acquire() # 开启互斥锁
gl_num += 1
mutex.release() # 关闭互斥锁
即仅仅将 gl_num += 1 视为原子操作。
在这种情况下执行结果为:
![]()
因为在这种情况下两个线程中的函数是宏观上同时执行(微观上交替执行)的,即交替地对全局变量 gl_num 进行循环自加,所以 sum1(num) 中的结果中也掺杂了 sum2(num) 部分的自加操作。
2 线程之间的执行情况
以下内容在互斥锁为:
for i in range(num):
mutex.acquire() # 开启互斥锁
gl_num += 1
mutex.release() # 关闭互斥锁
的情况下进行讨论。
2.1 情况一
两个函数中的参数分别为:sum1(1000000) sum2(1000000),有 time.sleep(2) 的情况下,执行结果为:
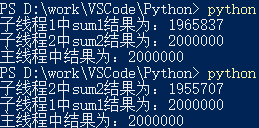
2.2 情况二
两个函数中的参数分别为:sum1(1000000) sum2(1000000),没有 time.sleep(2) 的情况下,执行结果为:
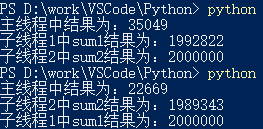
2.3 结论
从上面的结果可以看出,两个子线程和主线程谁先执行完毕是不清楚的。即线程与线程之间是独立运行的,运行的时间取决该线程的复杂程度,不一定先启用线程就一定先执行完毕。但是要注意的是,主线程一定是在所有的子线程都执行完毕并结束之后再结束主线程的(上面的运行结果中虽然有的先打印了主线程的结果,但是并没有结束主线程,而是等到其他子线程结束之后再结束主线程的)。