Gap Statistic 间隔统计量
- Gap Statistic
- 聚类的紧支测度 measure of the compactness
- 间隔统计量GS
- Python 实现
- 测试
Gap Statistic
Gap statistic由Tibshirani等人提出,用以解决聚类问题确定所判定类的数目。
聚类的紧支测度 (measure of the compactness)
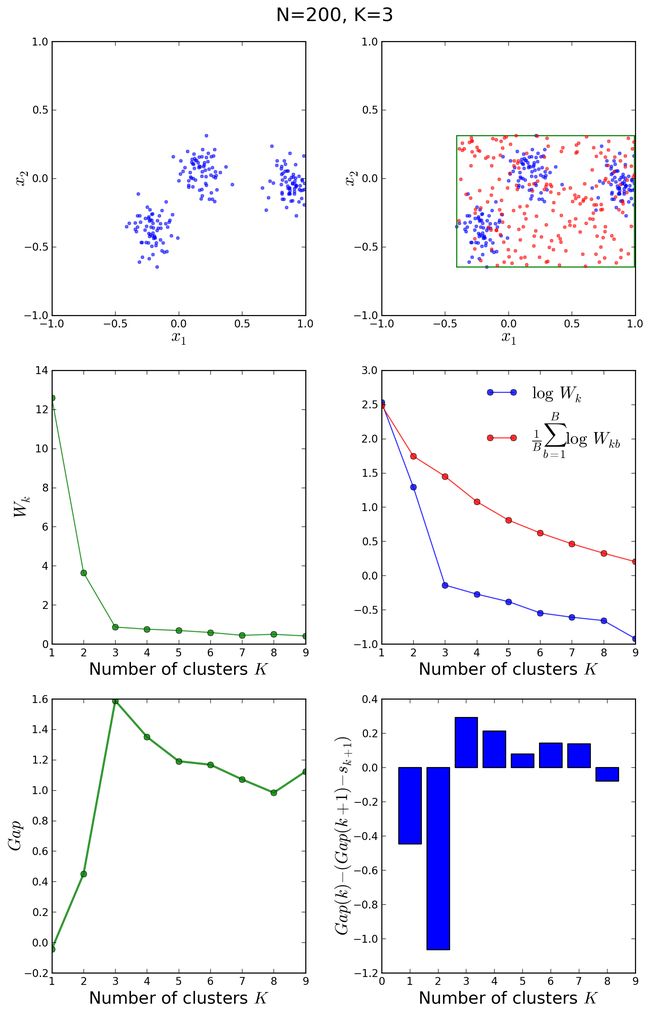
最简单的方法是使用类内样本点之间的欧式距离来表示,记为 Dk , DK 越小聚类的紧支性越好。Ref
Dk=∑xi∈Ck∑xj∈Ck||xi−xj||2=2nk∑xi∈Ck||xi−μk||2
标准化后:
Wk=∑k=1K12nkDk
Wk 是elbow method的基础,见下图。

间隔统计量(GS)
GS的基本思路是:引入参考的测度直,这个参考直可以有Monte Carlo采样的方法获得。
Gapn(k)=E∗nlogWk−logWkE∗nlogWk=(1/B)∑b=1Blog(W∗kb)
B是sampling的次数。为了修正MC带来的误差,我们计算 sk 也即标准差来矫正GS。
w′=(1/B)∑b=1Blog(W∗kb)sd(k)=(1/B)∑b(logW∗kb−w′)2‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾√sk=1+BB‾‾‾‾‾‾√sd(k)
选择满足 Gapk>=Gapk+1−sk+1 的最小的 k 作为最有的聚类个数。下图阐释了GS的过程。
Python 实现
import scipy
import scipy.cluster.vq
import scipy.spatial.distance
import numpy as np
EuclDist = scipy.spatial.distance.euclidean
def gapStat(data, resf=None, nrefs=10, ks=range(1,10)):
'''
Gap statistics
'''
# MC
shape = data.shape
if resf == None:
x_max = data.max(axis=0)
x_min = data.min(axis=0)
dists = np.matrix(np.diag(x_max-x_min))
rands = np.random.random_sample(size=(shape[0], shape[1], nrefs))
for i in xrange(nrefs):
rands[:,:,i] = rands[:,:,i]*dists+x_min
else:
rands = refs
gaps = np.zeros((len(ks),))
gapDiff = np.zeros(len(ks)-1,)
sdk = np.zeros(len(ks),)
for (i,k) in enumerate(ks):
(cluster_mean, cluster_res) = scipy.cluster.vq.kmeans2(data, k)
Wk = sum([EuclDist(data[m,:], cluster_mean[cluster_res[m],:]) for m in xrange(shape[0])])
WkRef = np.zeros((rands.shape[2],))
for j in xrange(rands.shape[2]):
(kmc,kml) = scipy.cluster.vq.kmeans2(rands[:,:,j], k)
WkRef[j] = sum([EuclDist(rands[m,:,j],kmc[kml[m],:]) for m in range(shape[0])])
gaps[i] = scipy.log(scipy.mean(WkRef))-scipy.log(Wk)
sdk[i] = np.sqrt((1.0+nrefs)/nrefs)*np.std(scipy.log(WkRef))
if i > 0:
gapDiff[i-1] = gaps[i-1] - gaps[i] + sdk[i]
return gaps, gapDiff测试
mean = (1, 2)
cov = [[1, 0], [0, 1]]
#np.random.multivariate_normal(1.1, [[0,1],[1,0]])
Nf = 1000;
dat1 = np.zeros((3000,2))
dat1[0:1000,:] = numpy.random.multivariate_normal(mean, cov, 1000)
mean = [5, 6]
dat1[1000:2000,:] = numpy.random.multivariate_normal(mean, cov, 1000)
mean = [3, -7]
dat1[2000:3000,:] = numpy.random.multivariate_normal(mean, cov, 1000)
plt.plot(dat1[::,0], dat1[::,1], 'b.', linewidth=1)
plt.legend()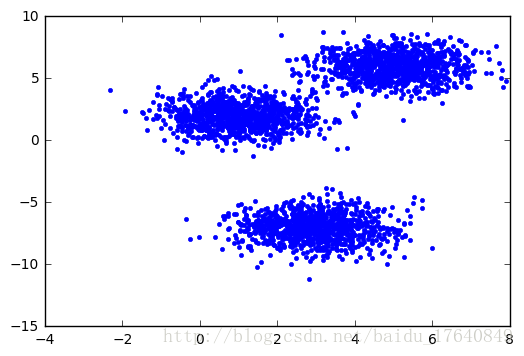
gaps,gapsDiff = gapStat(dat1)
%matplotlib inline
f, (a1,a2) = plt.subplots(2,1)
a1.plot(gaps, 'g-o')
a2.bar(np.arange(len(gapsDiff)),gapsDiff)
f.show()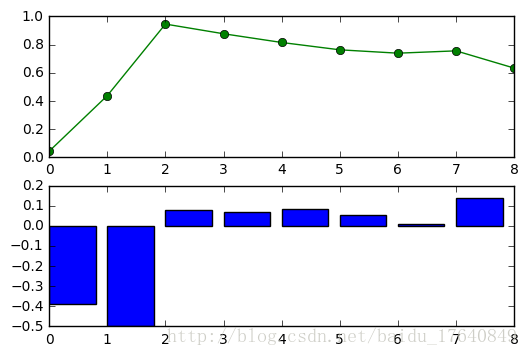
从图中可以看到k应该取3.