前端开发面试基础总结
1.如何在 ES5 环境下 实现 let
实际上主要的区别在于,var 声明的变量由于不存在块级作用域所以可以在全局环境中调用,而 let 声明的变量由于存在块级作用域所以不能在全局环境中调用。
function(){
for(var i = 0; i < 5; i ++){
console.log(i); // 0 1 2 3 4
}
}()
console.log(i); // Uncaught ReferenceError: i is not defined
2.如何在 ES5 环境下 实现 const
实现 const 的关键在于 Object.defineProperty() 这个 API,这个 API 一直用于在一个对象上增加或修改属性,通过配置描述符,可以精确的控制属性行为。Object.defineProperty() 接收三个参数:
Object.defineProperty(obj, prop, desc);
| 参数 | 说明 |
|---|---|
| obj | 要在其定义属性的对象 |
| prop | 要定义或修改的属性名称 |
| descriptor | 将被定义或修改的属性描述符 |
| 属性描述符 | 说明 |
|---|---|
| value | 该属性对应的值。可以是任何有效的 Javascript 值,默认为 undefined |
| get | 一个给属性提供 getter 的方法,如果没有 getter 则为 undefined |
| set | 一个给属性提供 setter 的方法,如果没有 setter 则为 undefined,当属性值修改时,触发执行该方法 |
| writeable | 当且仅当该属性的 writerale 为 true 时,value 才能被赋值运算符改变,默认为 false |
| enumerable | enumerable 定义了对象的属性是否可以在 for…in 循环和 Object.keys() 中被枚举 |
| configurable | configurable特性表示对象的属性是否可以被删除,以及除 value 和 writeable 特性以外的其他特性是否可以被修改 |
那对于 const 不可修改的特性,我们可以通过设置 wirteable 属性实现:
function _const(key, value){
var desc = {
value,
writeable: false
}
Object.defineProperty(window, key ,desc);
}
_const('obj', {
a:1}); // 定义一个 a
obj.b = 2; // 可以正常赋值
obj = {
}; // 报错 Cannot redefine property: obj
3.手写 call()
call() 方法使用一个指定的 this 值和单独给出的一个或多个参数来调用一个函数。
语法:func.call( thisArg, arg1, arg2, ...);
call() 的原理主要是函数的 this 指向它的直接调用者,我们变更调用者即完成 this指向的变更:
// 变更函数的调用者实例
function foo(){
console.log(this.name);
}
let obj = {
name:'chenxishen'
}
obj.foo = foo; // 变更 foo 的调用者
obj.foo(); // chenxishen
基于以上原理 我们可以简单实现 call():
Function.prototype.myCall = function(thisArg, ...args){
thisArg.fn = this; // this指向调用call的对象,即我们要改变this指向的函数
return thisArg.fn(...args); // 执行函数并返回执行结果
}
但是我们有些细节需要处理:
Function.prototype.myCall = function(thisArg, ...args){
if(typeof this !== 'function'){
throw new TypeError('error');
}
const fn = Symbol('fn'); // 声明一个独有fn属性,防止fn覆盖原有属性
thisArg = thisArg || window; // 若没有传入this,则默认绑定window对象
thisArg[fn] = this; // this指向调用call的对象,即我们要改变this指向的函数
const result = thisArg[fn](...args); // 执行函数保存结果
delete thisArg[fn]; // 删除我们声明的 fn 属性
return result; // 返回执行结果
}
// 测试
foo.myCall(obj); // chenxishen
4.手写 apply()
apply() 方法调用一个具有给定 this 值得函数,以及作为一个数组(或类似数组对象)提供的参数。
语法:func.apply(thisArg, [ array ]);
apply() 和 call() 类似,区别在于 call() 接收参数列表,而 apply() 接收一个参数数组,所以我们在 call()的实现上简单修改一下传参即可:
Function.prototype.myApply = function(thisArg, args){
if(typeof this !== 'function'){
thow new TypeError('error');
}
const fn = Symbol('fn'); // 声明一个独有的fn属性,防止fn覆盖原有属性
thisArg = thisArg || window; // 如没有传入this,则默认绑定window对象
thisArg[fn] = this;// this指向apply调用的对象,即我们要改变this指向的函数
const result = thisArg[fn]( ...args); // 执行当前函数,解构传参
delete thisArg[fn]; // 删除我们声明的 fn 属性
reutrn result; // 返回结果
}
// 测试
foo.apply(obj, []); // chenxishen
5.手写 bind()
bind() 方法创建一个新的函数,在 bind() 被调用时,这个新函数的 this 被指定 为 bind() 的
第一个参数,而其余参数将作为新函数的参数,供调用时使用。
语法:function.bind(thisArg, arg1, arg2, ...)
从语法上看似乎给 apply/ call 包裹了一层 function 就实现了 bind():
Function.prototype.myBind = function(thisArg, ...args){
return ()=>{
this.apply(thisArg,args);
}
}
但是我们忽略了以下几点
- bind() 除了 this 还接收其他参数,bind() 返回的函数也接收参数,这两部分的参数都要传给返回的函数
- new 的优先级,如果 bind() 绑定后的函数被 new 了,那么此时的 this 指向就发生了改变。此时的 this 就是当前函数的实例
- 没有保留原函数在原型链上的属性和方法
Function.prototype.myBind = function(thisArg, ...args){
if(typeof this !== 'function'){
throw new TypeError('Bind must be called on a function');
}
let self = this;
// new 优先级
let fbound = function(){
self.apply(this instanceof self ? this : thisArg, args.concat(Array.prototype.slice.call(arguments)));
}
// 继承 原型链上的方法
fbound.prototype = Object.create(self.prototype);
return fbound;
}
// 测试
const obj = {
name:'chenxishen'};
function foo(){
console.log(this.name);
console.log(arguments);
}
foo.myBind(obj, 'a', 'b', 'c')(); // chenxishen ['a','b','c']
6.手写一个防抖函数
防抖,即短时间内大量触发同一事件,只会执行一次函数,实现原理为设置一个定时器,约定在 xx 毫秒后再触发
事件处理,每次触发事件都会重新设置计时器,直到 xx 毫秒内无第二次操作,防抖常用于搜索框/滚动条的监听
事件处理,如果不做防抖,每输入一个字或滚动屏幕,都会触发事件处理,造成资源浪费。
function debounce (func, wait){
let timeout = null;
return function(){
let context = this;
let args = arguments;
if(timeout) clearTimeout(timeout);
timeout = setTimeout( ()=>{
func.apply(context, args)
}, wait);
}
}
7.手写一个节流函数
防抖是延迟执行, 而节流是间隔执行,函数节流即每个一段时间就执行一次,实现原理为设置一个定时器,约定
xx 毫秒后执行事件,如果时间到了,那么执行函数并重置定时器,和防抖的区别在于,防抖每次触发事件都重置
定时器,而节流是在定时器到时间后再清空定时器,
// 方法 1
function throttle(func, wait){
let timeout = null;
return function(){
let context = this;
let args = arguments;
if(!timeout){
timeout = setTimeout(() =>{
timeout = null;
func.apply(context, args);
})
}
}
}
// 方法 2
// 原理:使用两个时间戳,prev表示旧时间戳,now表示新时间戳,每次触发事件判断二者的时间差,
// 如果达到规定时间,执行函数并重置旧时间戳
function throttle2(func, wait){
var prev = 0;
return function(){
let now = Data.now();
let context = this;
let args = arguments;
if(now - prev > wait){
func.apply(context, args);
prev = now;
}
}
}
8.数组扁平化
对于 [1, [ 2, 3 ] , [1, 2, 3]] 这样多层嵌套的数组,我们如何将其扁平化的为 [ 1, 2, 3, 1, 2, 3] 这样的数组。
(1)ES6 的 flat()
const arr = [1, [ 2, 3 ] , [1, 2, 3]];
arr.flat( Infinity ) // [1, 2, 3, 1, 2, 3]
(2) 序列化正则
const arr = [1, [ 2, 3 ] , [1, 2, 3]];
const str = `[${
JSON.stringify(arr).replace(/(\[|\])/g, '')}]`;
JSON.parse( str ); // [1, 2, 3, 1, 2, 3]
(3) 递归
对于树状结构的数据,最直接的处理方法就是递归
const arr = [1, [ 2, 3 ] , [1, 2, 3]];
function flat ( arr ){
let result = [];
for(const item of arr){
item instanceof Array ? result = result.concat(flat(item)) :
result.push(item);
}
return result;
}
flat(arr) // [1, 2, 3, 1, 2, 3]
(4) Reduce() 递归
const arr = [1, [ 2, 3 ] , [1, 2, 3]];
function flat(arr){
return arr.reduce( (prev, cur) =>{
return prev.concat(cur instanceof Array ? flat(cur) : cur)
},[])
}
flat(arr) // [1, 2, 3, 1, 2, 3]
9.手写一个简单的 Promise
const PENDING = 'pending';
const FULFILLED = 'fulfilled';
const REJECTED = 'reject';
function Promise(executor){
let _that = this; // 缓存当前的Promise 实例
_that.status = PENDING; // 设置初始状态
_that.onFulfilledCallBack = []; // 存放所有成功的回调
_that.onRejectedCallBack = []; // 存放所有失败的回调
function resolve(value){
if(value instanceof Promise){
return value.then(resolve, reject);
}
if(_that.status === PENDING){
// 如果是初始状态,则置为成功态
_that.status = FULFILLED;
_that.value = value; // 成功后会得到一个值,这个值不能改
if(_that.onFulfilledCallBack.length > 0){
_that.onFulfilledCallBack.forEach(cb => cb(value))
}
}
}
function reject(reason){
if(_that.status === PENDING){
// 如果是初始态,则转成失败态
_that.status = REJECTED;
_that.value = reason;
if(_that.onRejectedCallBack.length > 0){
_that.onRejectedCallBack.forEach(cb => cb(reason) );
}
}
}
try{
executor(resolve, reject);
}catch(e){
reject(e);
}
}
Promise.prototype.then = function(onFulfilled, onRejected){
// 当then 不传参时 这样把默认值传给下一个 then
onFulfilled = typeof onFulfilled == 'function' ? onFulfilled : value => value;
onRejected = typeof onRejected == 'function' ? onRejected : reason => {
throw reason};
let self = this;
if(self.status == FULFILLED){
let a = onFulfilled(self.value);
}
if(self.status == REJECTED){
let a = onRejected(self.value);
}
if(self.status == PENDING){
self.onFulfilledCallBack.push(onFulfilled);
self.onRejectedCallBack.push(onRejected);
}
}
Promise.prototype.catch = function(onRejected){
this.then(null, onRejected);
}
10. JS 面向对象
在 JS 中一切皆对象,但 JS 并不是一种真正的面向对象的语言,因为它缺少类的概念,虽然 ES6 引入了 class 和 extends,使我们能够轻易的实现类和继承,但是 JS 并存在真实的类, JS 的类是通过函数以及原型链机制模拟的,我们现在来探讨下如何在 ES5 的环境下 利用函数和原型链实现 JS 面向对象的特性。
我们先了解下原型链的知识:
- 每个对象上都有__proto__属性,该属性指向其原型对象,在调用实例的方法和属性时,如果在实例对象上找不到就会去原型对象上找
- 构造函数的 prototype 属性也指向实例的原型对象
- 原型对象的 constructor 属性指向构造函数

(1)模拟实现 new
首先我们要知道 new 做了什么
- 创建一个新对象,并继承其构造函数的 prototype, 这一步是为了继承构造函数上的原型和方法
- 执行构造函数,方法内的 this 被指定为该新实例,这一步是为了执行构造函数内的赋值操作
-** 返回新实例**(规范操作,如果构造方法返回了一个对象,那么返回该对象,否则返回第一步创建的新对象)
// new 是关键字,这里我们用函数来模拟,new Foo(args) <=> myNew(Foo, args);
function myNew(foo, ...args){
// 创建新对象,并继承构造方法的 prototype 属性,这一步是为了把 obj 挂在原型链上,
// 相当于obj.__proto__ = Foo.prototype
let obj = Object.create(foo.prototype);
// 执行构造方法,并为其绑定新的this,这一步是为了让构造方法能进行this.name = name之类的操作,
// args是构造方法的入参,因为这里用 myNew 模拟,所以入参从myNew传入
let result = foo.apply(obj, args);
// 如果构造方法已经 return 了一个对象,那么就返回该对象,一般情况下,构造方法不会返回新实例,但使用者
// 可以选择返回新实例来覆盖 new 创建的对象,否则返回的 myNew 创建的新对象
return typeof result === 'object' && result !== null ? result : obj;
}
function Foo(name){
this.name = name;
}
const newObj= myNew(Foo, 'chenxishen');
console.log(newObj); // Foo {name: "chenxishen"}
console.log(newObj instanceof Foo); // true
(2)ES5 如何实现继承
ES6 里面可以直接用 extends 实现继承,但是我们在 ES5 中要从函数和原型链的角度上来实现继承。
一、原型链继承
原型链继承的原理很简单,直接让子类的原型对象指向父类实例,当子类实例找不到对应的属性和方法时,就会往它的原型对象,也就是父类实例上找,从而实现对父类的属性和方法的继承
// 父类
function Perent(){
this.name = 'chenxishen';
}
// 父类的原型方法
Parent.prototype.getName = function(){
return this.name;
}
// 子类
function Child(){
}
// 让子类的原型对象指向父类实例,这样一来在child实例中找不到的属性和方法就会到原型对象(父类实例上找)
Child.prototype = new Parent();
// 根据原型链规则,顺便绑定一下constructor,这一步不影响继承,只是在用到constructor时会需要
Child.prototype.constructor = Child;
// 然后 child 实例就能访问到父类及其原型上的 name 属性和 getName() 方法
const child = new Child();
console.log(child.name); // chenxishen
console.log(child.getName()); // chenxishen
原型链继承的缺点:
- 由于所有的 Child 实例原型都指向同一个 Parent 实例,因此对某个 Child 实例的父类引用类型变量修改会影响所有的 Child 实例。
- 在创建子类实例时无法向父类构造传参,即没有实现 super() 功能
二、构造函数继承
构造函数继承,即在子类的构造函数中执行父类的构造函数,并为其绑定子类的 this,让父类的构造函数把成员属性和方法都挂载到子类的 this 上去,这样既能避免实例直接共享一个原型实例,又能向父类构造方法传参
function Parent(name){
this.name = [name];
}
Parent.prototype.getName = function(){
return this.name;
}
function Child(){
// 执行父类构造方法并绑定子类的this,使得父类中的属性能够赋值到子类的this 上
Parent.call(this, 'chenxishen');
}
// 测试
const child1 = new Child();
const child2 = new Child();
child1.name[0] = 'foo';
console.log(child1.name); // [ 'foo' ]
console.log(child2.name); // [ 'chenxishen' ]
console.log(child2.getName()); // error child2.getName is not a function
构造函数继承的缺点:
继承不到父类原型上的属性和方法
三、组合式继承
既然原型链继承和构造函数继承各有可以互补的优缺点,那么我们可以结合起来用:
function Parent(name){
this.name = [name];
}
Parent.prototype.getName = function(){
return this.name;
}
function Child(){
// 构造函数继承
Parent.call(this, 'chenxishen');
}
// 原型链继承
Child.prototype = new Parent();
Child.prototype.constructor = Child;
// 测试
const child1 = new Child();
const child2 = new Child();
child1.name[0] = 'foo';
console.log(child1.name); // [ 'foo' ]
console.log(child2.name); // [ 'chenxishen' ]
console.log(child2.getName()); // [ 'chenxishen' ]
组合式继承的缺点:
每次创建子类实例都执行了两次构造函数( Parent.call() 和 new Parent() ), 虽然这不影响对父类的继承,
但是子类创建实例时,原型中会存在两份相同的属性和方法,这并不优雅。
四、寄生式组合继承
为了解决构造函数被执行两次的问题,我们将指向父类实例改为** 指向父类原型**,减去一次构造函数的执行
function Parent(name){
this.name = [ name ];
}
Parent.prototype.getName = function(){
return this.name;
}
function Child(){
// 构造函数继承
Parent.call(this, 'chenxishen');
}
// 原型链继承
// Child.prototype = new Parent();
Child.prototype = Parent.prototype; // 将指向父类实例改为指向父类原型
Child.prototype.constructor = Child;
// 测试
const child1 = new Child();
const child2 = new Child();
child1.name[0] = 'foo';
console.log(child1.name); // [ 'foo' ]
console.log(child2.name); // [ 'chenxishen' ]
console.log(child2.getName()); // [ 'chenxishen' ]
但是这个方式存在一个问题,由于子类原型和父类原型指向同一个对象,我们对子类原型的操作会影响到父类的原型,例如给 Child.prototype 增加一个 getName() 方法,那么会导致 Parent.prototype 也会增加会覆盖一个 getName() 方法,为了解决这个问题,我们给 Parent.prototype 做一个浅拷贝
function Parent(name){
this.name = [ name ];
}
Parent.prototype.getName = function(){
return this.name;
}
function Child(){
// 构造函数继承
Parent.call(this, 'chenxishen');
}
// 原型链继承
// Child.prototype = new Parent();
// 将指向父类实例改为指向父类原型
Child.prototype = Object.create(Parent.prototype);
Child.prototype.constructor = Child;
// 测试
const child1 = new Child();
const child2 = new Child();
child1.name[0] = 'foo';
console.log(child1.name); // [ 'foo' ]
console.log(child2.name); // [ 'chenxishen' ]
console.log(child2.getName()); // [ 'chenxishen' ]
到这里我们就完成了 ES5 环境下的继承的实现,这种继承方式称为寄生组合式继承,是目前最成熟的继承方式, babel对ES6 继承的转换也是使用了寄生组合式继承。
我们现在回顾一下实现过程:
一开始最容易想到的就是原型链继承,通过把子类实例的原型指向父类实例来继承父类的属性和方法,但原型链继承的缺点在于对子类实例继承的引用类型的修改会影响到所有实例对象 以及 无法向构造函数传参,因为我们引入了构造函数继承,通过在子类构造函数中调用父类构造函数并传入子类 this 来获取父类的属性和方法,但构造函数继承也存在缺陷,构造函数继承不能继承父类原型链上的属性和方法。所以我们综合了两种继承的优点,提出了组合式继承,但组合式继承也有新的问题,它每次创建子类实例都执行了两次父类的构造方法,我们通过将子类原型指向父类实例改为子类原型指向父类原型的浅拷贝来解决这一问题,也就是最终实现—寄生组合式继承。
11. V8 引擎机制
(1)V8 如何执行一段 JS 代码
- 预解析:检查语法错误但不生成 AST
- 生成 AST:经过词法/语法分析,生成抽象语法树
- 生成字节码:基线编译器将 AST 转换成字节码
- 生成机器码:优化编译器将字节码转换成优化过得机器码,此外在逐行执行字节码的过程中,如果一段代码经常被执行,那么 V8 会将这段代码直接转换成机器码保存起来,下次执行就不必经过字节码,优化了执行速度。
(2)介绍一下引用计数和标记清除
- 引用计数:给一个变量赋值引用类型,则该对象的引用次数 +1,如果这个变量变成了其他值,那么该对象的引用次数-1,垃圾回收期器会回收引用次数为 0 的对象。但是当对象循环引用时,会导致引用次数永远无法归零,造成内存无法释放。
- 标记清除:垃圾收集器先给内存中所有的对象加上标记,然后从根节点开始遍历,去掉引用的对象和运行环境中对象的标记,剩下的被标记的对象就是无法访问的等待回收的对象。
(3)V8 如何进行垃圾回收
栈内存回收:栈内存调用栈上下文切换后就被回收,比较简单。
堆内存回收:V8 的堆内存分为新生代内存和老生代内存,新生代内存时临时分配的内存,存在时间短,老生代存在时间长。
新生代内存回收机制:新生代内存容量小,64位系统下仅有 32M,新生代内存分为 From、To 两部分,进行垃圾回收时,先扫描 From,将非存活对象回收,将存活对象顺序复制到 To 中,之后调换 From/To, 等待下一次回收。
老生代内存回收机制:
- 晋升:如果新生代的变量经过多次回收依然存在,那么就会被放入老生代内存中。
- 标记清除:老生代内存会遍历 所有的对象打上标记,然后对正在使用的或被强引用的对象取消标记,回收被标记的对象。
- 整理内存碎片:把对象挪到内存的一端
(4)JS相较于C++等语言为什么慢,V8做了哪些优化
JS的问题:
- 动态类型:导致每次存取属性/寻求方法时候,都需要先检查类型,此外动态类型也很难再编译阶段进行优化
- 属性存取:C++、Java等语言中的方法、属性是存储在数组中的,仅需要数组位移就可以 获取,而 JS 存储在对象中,每次获取都要进行哈希查询
V8 的优化:
- 优化 JIT(及时编译):相较于 C++/ Java 这类编译型语言, JS一边解释一边执行,效率低。V8 对这个过程进行了优化,如果一段代码被执行多次,那么 V8会把这段代码转换为机器码缓存下来,下次运行时直接使用机器码
- 隐藏类:对于 C++ 这类语言来说,仅需几个指令就能通过偏移量获取变量信息,而 JS 需要进行字符串匹配,效率低,V8借用了类和偏移位置的思想,将对象划分为不同的组,即隐藏类。
- 内嵌缓存:即缓存对象查询的记过。常规查询的过程是:获取隐藏类地址 -> 根据属性名查找偏移值 -> 计算该属性地址,内嵌缓存就是对这一过程结果的缓存。
- 垃圾回收管理:请看上文。
12. 浏览器缓存策略
(1)介绍一下浏览器缓存位置和优先级
- Service Worker
- Memory Cache (内存缓存)
- Disk Cache (硬盘缓存)
- Push Cache (推送缓存)
- 以上缓存都没命中就会进行网络请求
(2)说说不通缓存间的差别
1.Service Worker:
和Web Worker类似,是独立的线程,我们可以在这个线程中缓存文件,在主线程需要的时候读取这里的文件,Service Worker使我们可以自由选择缓存哪些文件以及文件的匹配、读取规则,并且缓存是持续性的。
2.Memory Cache
即内存缓存,内存缓存不是持续性的,缓存会随着进程释放而释放
3.Disk Cache
即硬盘缓存,相较于内存缓存,硬盘缓存的持续性和容量更优,它会根据 HTTP header 的字段判断哪些资源需要缓存
4.Push Cache
即推送缓存,是HTTP /2 的内容,目前应用较少
(3)介绍一下浏览器缓存策略
强缓存(不要向服务器询问的缓存)
设置Expires
即过期时间,例如 Express: Thu, 26 Dec 2019 10:30;22 GMT ,表示缓存会在这个时间后失效,这个过期日期是绝对日期,如果修改了本地日期,或者本地日期与服务器日期不一致,那么将导致缓存过期时间错误
设置Cache-Control
HTTP /1.1 新增字段, Cache-Control 可以通过 max-age 字段来设置过期时间,例如 Cache-Control:max-age=3600 ,除此之外 Cache-Control还能设置 private/no-cache 等多种字段
协商缓存(需要向服务器询问缓存是否已经过期)
Last-Modified
即最后修改时间,浏览器第一次请求资源时,服务器会在响应头上加上 Last-Modified,当浏览器再次请求该资源时,浏览器会在请求头上带上 IF-Modified-Since 字段,字段的值就是之前服务器返回的最后修改时间,服务器对比这两个时间,若相同则返回 304,否则返回新资源,并更新 Last-Modified .
** Etag**
HTTP / 1.1 新增字段,表示文件唯一标识,只要文件内容改动, Etag 就会重新计算。缓存流程和 Last-Modified 一样,服务器发送 Etag 字段 -.> 浏览器再次请求发送 IF-None-Match -> 如果 Etag 值不匹配,说明文件已经改变,返回新资源并更新 Etag,若匹配则返回 304.
两者对比:
- Etag 比 Last-Modified 更准确,如果我们打开文件但并没有修改,Last-Modified 也会改变,并且 Last-Modified的单位时间为一秒,如果一秒内修改完了文件,那么还是会命中缓存。
- 如果什么缓存策略都没有设置,那么浏览器会取响应头中的 Date 减去 Last-Modified 值得 10% 作为缓存时间
13. 排序算法
(1)手写冒泡排序
function bubbleSort( arr ){
for(let i = 0; i < arr.length; i++){
for(let j = 0; j < arr.length - i; j++){
if(arr[j] > arr [j+1]){
let temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
}
return arr;
}
(2)如何优化一个冒泡排序
冒泡排序总执行 (N-1)+( N-2) + (N-3)+…+2+1 趟,但是如果运行到某一个躺时排序已经完成,或者输入的是一个有序的数组,那么后边的比较就都是多余的,为了避免这种情况,我们增加一个 flag,判断排序是否在中途就已经完成(也就是判断有无发生元素交换)
function bubbleSort( arr ){
let flag = true;
for(let i = 0; i < arr.length; i++){
for(let j = 0; j < arr.length - i -1; j++){
if(arr[j] > arr[j+1]){
flag = false;
let temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
if(flag) break;
}
return arr;
}
(3)手写快速排序
快排的基本步骤:
- 选取基准元素
- 比基准元素小的元素放到左边,大的放右边
- 在左右子数组中重复步骤一二,直到数组只剩下一个元素
- 向上逐级合并数组
function quickSort(arr){
if(arr.length < = 1) return arr;
const middle= arr.length / 2 | 0;
const midValue= arr.splice(middle, 1);
const leftArr = [];
const rightArr = [];
arr.forEach(val => {
val > midValue ? rightArr.push(val) : leftArr.push(val);
})
return [...quickSort(leftArr),midValue, ...quickSort(rightArr)];
}
(4)如何优化一个快速排序
原地排序
上面这个排序只是让我们先熟悉一下快排,实际上我们不能这样写,如果每次都开两个数组会消耗很多内存空间,数据量大的时候可能会造成内存溢出,我们要避免开新的内存空间,即原地完成排序
我们可以用元素交换来取代开新数组,在每一次分区的时候直接再原数组上交换元素,将小于基准数的元素挪到数组开头,以 [5, 1, 4, 2, 3] 为例:
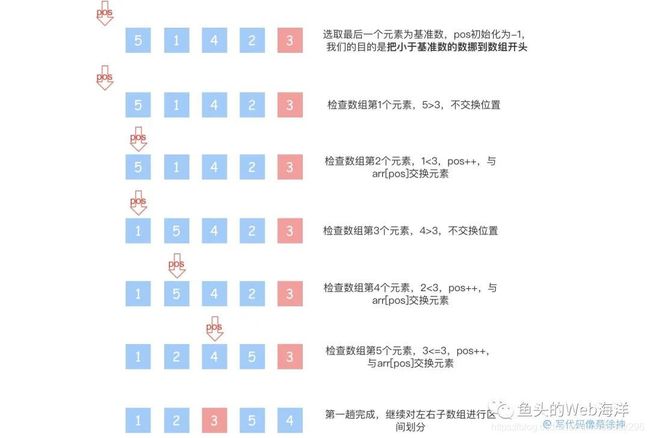
我们定义了一个 pos 指针,标识等待置换的元素的位置,然后逐一遍历数组元素,遇到比基准数小的就和 arr[pos] 交换位置,然后 pos++,代码实现:
// 这个left和right代表区分后新数组的区间下标,因为这里没开新数组,所以需要left/right来确认新数组的位置
function quickSort(arr, left, right){
if(left < right){
let pos = left -1; // pos即 被置换的位置,第一趟为 -1
for(let i= left; i <= right; i++){
// 循环遍历数组,置换元素
let middle = arr[right]; // 选取数组最后一位作为基准数
// 若小于等于基准数,pos++,并置换元素,这里使用小于等于而不是小于,其实是为了避免因为重复数据而进入死循环
if(arr[i] <= middle){
pos++;
let temp = arr[pos];
arr[pos] = arr[i];
arr[i] = temp;
}
}
// 一趟排序完成后,pos 位置即基准数的位置,以pos的位置分隔数组
quickSort(arr, left, pos - 1);
quickSort(arr, pos + 1, right);
}
return arr; // 数组只包含1或0个元素时,即left >= right,递归终止
}
// 测试
let arr = [6,2,3,1,5,8,4];
console.log( quickSort(arr, 0, arr.length-1)); // [ 1, 2, 3, 4, 5, 6, 8 ]
三路快排
上面这个快排还谈不上优化,应该说是第一个快排的纠正写法,其实还有两个问题我们还能优化一下:
- 有序数组的情况:如果输入的数组是有序的,而取基准点时也顺序取,就可能导致基准点一侧的子数组一直为空,使得时间复杂度退化到 O(n2)
- 大量重复数据的情况:例如输入的数据时 [1, 2, 2, 2, 3] ,无论基准点取 1、2 还是 3,都会导致基准点两侧数组大小不平衡,影响快排效率
对于第一个问题,我们可以通过在去基准点的时候随机化来解决,对于第二个问题,我们可以使用 三路快排的方式来优化,比方说上面的 [1, 2, 2, 2, 3],我们基准点取2,在分区的时候,将数组元素分为 小于2 | 等于2 | 大于2 三个区域,其中等于基准点的部分不再进入下一次排序,这样就大大提高了快速排序。
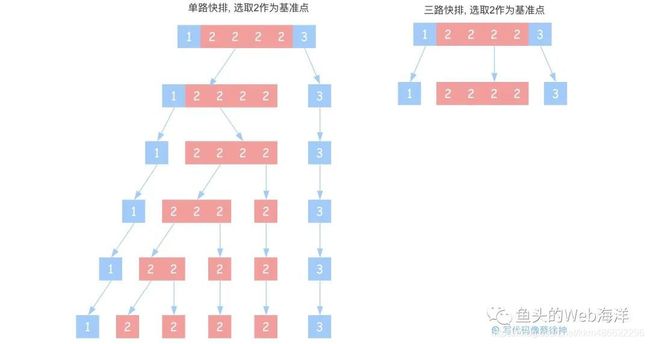
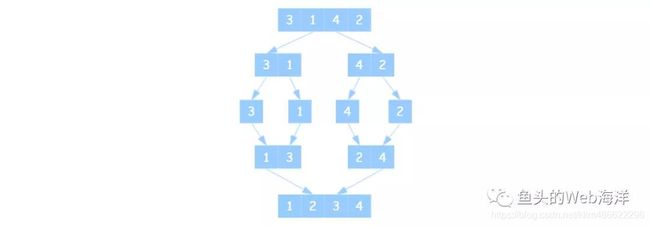
(5)手写归并排序
归并排序和快排的思路类似,都是递归分治,区别在于快排边分区边排序,而归并在于分区完成后才会排序。
function mergeSort(arr){
if(arr.length <= 1) return arr;
const midIndex = arr.length / 2 | 0;
const leftArr = arr.slice(0, midIndex);
const rightArr = arr.slice(midIndex, arr.length);
return merge(mergeSort(leftArr), mergeSort(ringtArr); // 先划分 后合并
}
// 合并
function merge(leftArr, rightArr){
const result = [];
while(leftArr.length && rightArr.length){
leftArr[0] <= rightArr[0] ? result.push(leftArr.shift()) : result.push(rightArr.shift());
}
while(left.length) result.push(leftArr,shift());
while(rightArr.length) result.push(rightArr.shift());
return result;
}
(6)手写堆排序
堆是一颗特殊的树,只要满足这棵树是完全二叉树和堆中每一个子节点的值都大于或小于其左右孩子节点这两个条件,那么就是一个堆,根据堆中每一个节点的值都大于或小于其左右孩子节点,又分为大根堆和小根堆。
堆排序的流程:
- 初始化大(小)根堆,此时根节点为最大(小)堆,将根节点与最后一个节点(数组最后一个元素)交换
- 除开最后一个节点,重新调整大(小)根堆,使根节点为最大(小)值
- 重复步骤二,直到堆中元素剩一个,排序完成
以 [1, 5, 4, 2, 3] 为例 构筑大根堆:

// 堆排序
const heapSort = array =>{
// 我们用数组储存这个大根堆,数组就是堆本身
// 初始化大根堆,从第一个非叶子结点开始
for(let i = Math.floor(array.length / 2 -1); i >= 0; i--){
heapify(array, i, array.length);
}
// 排序,每一次 for 循环找出一个当前的最大值,数组长度减一
for(let i = Math.floor(array.length - 1); i > 0; i--){
// 根节点与最后一个节点交换
swap(array, 0, i);
// 从根节点开始调整,并且最后一个节点已经成为当前最大值,不需要再参与比较,所以第三个参数为 i,
// 即比较到最后一个结点的前一个即可
heapify(array, 0, i);
}
return array;
}
// 交换两个节点
const swap = (array, i, j) => {
let temp = array[i];
array[i] = array[j];
array[j] = temp;
}
// 将 i 结点以下的堆 整理为大根堆,注意这一步实现的基础上是:
// 假设结点 i 以下的子堆已经是一个大根堆, heapify 函数实现的
// 功能是实际上是:找到结点 i 在包括结点i 的堆中的正确位置
// 后面将写一个 for 循环,从第一个非叶子结点开始,对每一个非叶子结点
// 都执行 heapify 操作,所以就满足了结点 i 以下子堆已经是一个 大顶堆
const heapify = (array, i ,length) => {
let temp = array[i]; // 当前父结点
// j < length 的目的是对结点 i 以下的结点全部做顺序调整
for(let j = 2 * i + i; j < length; j = 2 * j + 1){
temp = array[i]; // 将 array[i]取出,整个过程相当于找到了 array[i]应处于的位置
if(j + 1 < length && array[j] < array[j + 1]){
j++; // 找到两个孩子中较大的一个,再与父节点比较
}
if(temp < array[j]){
swap(array, i, j); // 如果父节点小于子节点:交换,否则抛出
i = j; // 交换后,temp 下标变为 j
}else{
break;
}
}
}
(7)归并、快排、堆排有什么区别
| 排序 | 时间复杂度(最好情况) | 时间复杂度(最坏情况) | 空间复杂度 | 稳定性 |
|---|---|---|---|---|
| 快速排序 | O(nlogn) | O(n^2) | O(logn)- O(n) | 不稳定 |
| 归并排序 | O(nlogn) | O(nlogn) | O(n) | 稳定 |
| 堆排序 | O(nlogn) | O(nlogn) | O(1) | 不稳定 |
其实从表格中我们可以看到,就时间复杂度而言,快排没有很大的优势,然而我为什么快排会成为最常用的排序手段,这是因为时间复杂度只能说明随着数量量的增加,算法时间代价增长的趋势,并不直接代表实际执行时间,实际运行时间还包括了很多常数参数的差别,此外在面对不同类型数据(比如有序数据,大量重复数据)时,表现也不同 ,综合来说,快排的时间效率是最高的。
在实际运用中,并不只使用一种排序手段,例如 V8 的 Array .sort() 就采用的 当 n<10时,采用插入排序,当 n>10时,采用三路快排的排序策略
说明 :上面的所有都是纯手敲,如果有错别字抱歉,代码都是楼主跑了没问题,才粘贴上去的
参文档
小册: https://juejin.im/book/5bdc715fe51d454e755f75ef/section/5c024ecbf265da616a476638
前端每日一问: https://github.com/sanyuan0704/sanyuan0704.github.io
如何在 ES5 环境下实现一个const ?: https://juejin.im/post/5ce3b2d451882533287a767f
异步编程二三事 | Promise/async/Generator实现原理解析 | 9k字: https://juejin.im/post/5e3b9ae26fb9a07ca714a5cc
V8 是怎么跑起来的 —— V8 的 JavaScript 执行管道: https://juejin.im/post/5dc4d823f265da4d4c202d3b
JavaScript 引擎 V8 执行流程概述: https://juejin.im/post/5df1ed1f6fb9a015fd69b78d
聊聊V8引擎的垃圾回收: https://juejin.im/post/5ad3f1156fb9a028b86e78be#heading-10
为什么V8引擎这么快?: https://zhuanlan.zhihu.com/p/27628685
必须明白的浏览器渲染机制: https://juejin.im/post/5ce120fbe51d4510a50334fa
浏览器缓存机制剖析: https://juejin.im/post/58eacff90ce4630058668257
HTTP|GET 和 POST 区别?网上多数答案都是错的: https://juejin.im/entry/597ca6caf265da3e301e64db
MDN的文档: https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers
http发展史(http0.9、http1.0、http1.1、http2、http3)
梳理笔记: https://juejin.im/post/5dbe8eba5188254fe019dabb#heading-9
看图学HTTPS: https://juejin.im/post/5b0274ac6fb9a07aaa118f49#heading-5
js算法-快速排序(Quicksort): https://segmentfault.com/a/1190000017814119
JS实现堆排序: https://www.jianshu.com/p/90bf2dcd6a7b