华为云杯”2020人工智能创新应用大赛总结与分析
华为云杯”2020人工智能创新应用大赛总结与分析
目录
赛题背景
数据简介与评判指标
数据分析
数据概览与初步分析
数据增强
模型设计与训练
基本结构
BackBone选取
Loss选取
优化器选取
训练trick
后处理
膨胀预测
阈值划定
结果与参考文献
***转载请注明出处****
-
赛题背景
西安,古称长安、镐京,陕西省会、副省级市,是世界历史名城、中国四大古都之一、中华文明和中华民族重要发祥地,是国家重要的科研、教育、工业基地,亦是丝绸之路起点城市和“一带一路”核心区。
西安国家民用航天产业基地成立于2006年11月,是陕西省、西安市政府联合中国航天科技集团公司建设的航天技术产业和国家战略性新兴产业聚集区,也是西安建设国际化大都市的城市功能承载区。2010年6月26日,被国务院批复为国家级陕西航天经济技术开发区。
此次赛题结合西安以及西安航天基地以航天卫星遥感产业为特色,旨在解决道路路网信息自动提取问题。本次比赛依托陕西航天工业雄厚的综合实力和坚实的发展基础,充分发挥航天科技对国家战略性新兴产业的引领作用,立足航天产业,发展人工智能新兴产业,推动军民融合,带动产城融合,在谋求错位发展中建设世界一流航天产业新城。
本赛题任务是基于高分辨可见光遥感卫星影像,提取复杂场景的道路与街道网络信息,将影像的逐个像素进行前、背景分割,检测所有道路像素的对应区域。
-
数据简介与评判指标
大赛数据集来源于北京二号卫星,空间分辨率为0.8米,分为训练集和测试集2个数据集,分别包含3景遥感影像,其中训练集2景影像的尺寸分别为40391×33106、34612×29810。测试集不公开只参与线上评测。参赛者可自行将训练集切分为小图,并划分为训练集和验证集以用于模型调优。数据集下载地址:https://ma-competitions-bj4.obs.cn-north-4.myhuaweicloud.com/xian/2020/data.zip
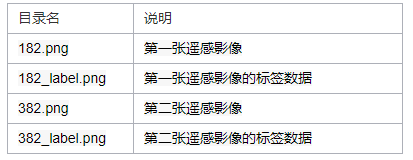
Data.zip解压后目录结构说明如下:
评价指标:平均交并比即MIOU,计算公式如下图:
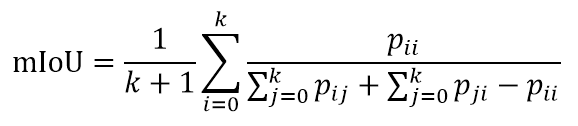
其中,k表示像素所属的类别,pij表示本属于类别i且被预测为类别j的像素数据,pii表示真正的数量,pij和pji分别表示假正和假负的数量。
-
数据分析
-
数据概览与初步分析
数据集共两张空间分辨率为0.8m的遥感影像图,尺寸大小分别是40391*33106和34612*29810。影像全图如下所示。
382.png
182.png
初步观察分析可以从影像上分析出一下几点内容:
- 影像是大尺寸图片并不能直接输入神经网络进行训练,因此要选用合适的图像切割发方式将影像切割成合适尺寸的图像。影像的切割方式大致有三种选择:规则网格切割、滑动窗口切割以及随机切割。这里我选择的是滑动窗口对图像进行切割,以448为步长才切成512*512尺寸的图片;
- 有影像的区域并不是正矩形,周围存在黑边,黑边在影像中占据的面积并不小,因此对于切割后的数据去除掉全黑的图像;
- 两张影像在颜色上存在肉眼可见的色差,因此拟考虑在数据增强中添加色彩增强相关部分降低模型对色彩上的敏感程度;
- 仔细查看数据集可以发现影像中的区域以城市乡镇为主,说明影像中会存在路网密集区和路网稀疏区,这可能会导致标签中的类别不平衡。


-
数据增强
数据增强的目的是为了增加样本的多样性,避免模型的过拟合。数据增强库很多,如:skimage、imgaug、opencv、Albumentations以及Augmentor等。在这里我选择的是Albumentations。
在此次大赛中我所用到的数据增强有很多,我主要将其分为三大类:形态变换、颜色变换以及其他变换。形态变换主要是为了对图像上的结构信息进行调整与改变从而达到数据增广的目的。如下图左侧的为原始图像,右侧为经过形态变换(网格失真)后的图像,可以看到两张影像上的道路部分发生一些改变,右侧的道路部分有些细微的扭曲,而道路的扭曲对于真是的情况来说是可能存在的,可以避免让模型误认为细长的颜色相同的区域就是道路,在一定程度上增加了样本的多样性。
颜色变换主要有随机调整色相饱和度、随机打乱通道顺序、RGB色彩偏移、随机调整亮度和对比度。其中随机打乱通道顺序避免不同库在读取图片时颜色通道不一致输入模型带来的影响,降低模型对色彩的依赖。随机调整亮度和对比度避免遥感影像因为天气影响带来的过曝或是欠曝导致影像亮度不一致的情况,在此加入是为了避免验证集上的遥感影像亮度对比度可能存在一定差别的因素。
其他变换主要有随机添加高斯噪声、中值滤波、cutout等,主要是为了提高模型的泛化能力。

-
模型设计与训练
-
基本结构
基本结构选择了2015年在MICCAI会议上发表的Unet。Unet结构简单,大体上可以分为两个部分,分别是用于提取特征的编码区和对特征进行解码还原的解码器。编码器和解码器之间存在skip connnection。即在解码器部分会融合编码器中的部分输出,这样实际上是将多尺度特征融合在了一起,实现了网络对图像特征的多尺度特征识别。
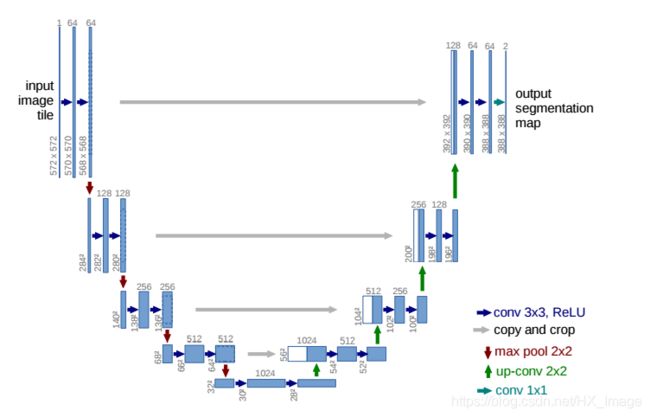
在本地实验也尝试过其他结构如:DeepLabV3、LinkNet、FPN等,但各有优缺点,如DeepLabV3训练效果比Unet略高,但是训练时间比Unet长,本人本地并没有好的GPU资源可以用于模型训练,而且大赛分配ModelArts资源宝贵,因此选择了训练速度快,精度较好的Unet作为基本结构。
-
BackBone选取
Unet用于特征提取的编码器部分结构较为简单,只有几层卷积网络顺次连接而成,为了提取更加丰富全面的特征我们可以更换编码器的结构用于提取更丰富的特征,常见的方法是从分类效果好的网络结构中选择合适的层作为backbone,以用于特征提取。在比赛过程中一共测试了8种backbone,包括resnet_34、resetnet50、se_resnet50、se_resnext50_32x4d、efficient-b0、efficient-b1、efficient-b2、efficient-b5。部分测试结果如下图:
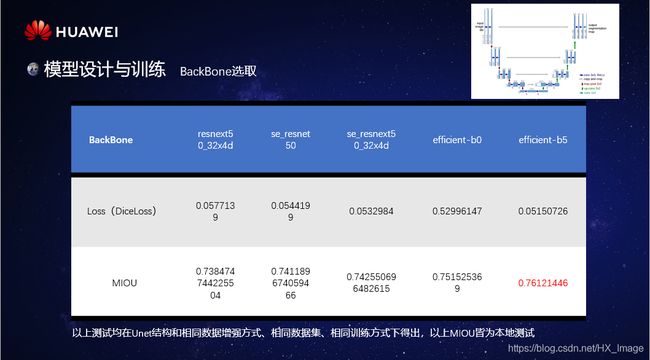
最终选择最好的efficient-b5作为backbone。
-
Loss选取
大赛的最终评价指标时miou,在二分类中iou等于miou,因此在Loss选取的时候选择了以iou作为优化方向的损失函数,Lovasz损失函数和Focal损失函数。添加Focal的主要目的是在数据裁切和增强部分并没有对样本的类别不均衡做处理,添加Focal是为了解决正负样本不均衡的问题。

Dice+BCELoss主要是优化速度快,但是后期BCELoss会变得非常小,近似与只有DiceLoss,而且在线上线下差距大,测试结果不稳定。Lovasz+FocalLoss前期损失下降平缓,测试时较为稳定,线上线下差距小。
-
优化器选取
优化器选择的时Radam+Lookahead,即Ranger。此组合变相的提供了不需要调参的warmUp,在快速优化的同时保持了模型的稳定性,且对学习率不敏感。
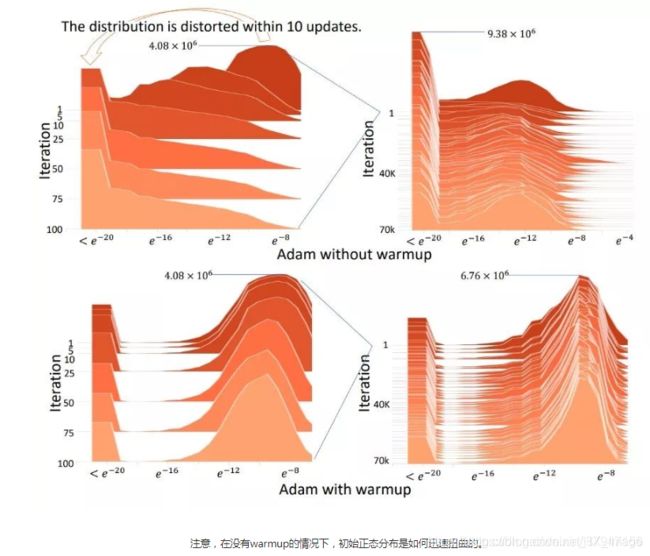
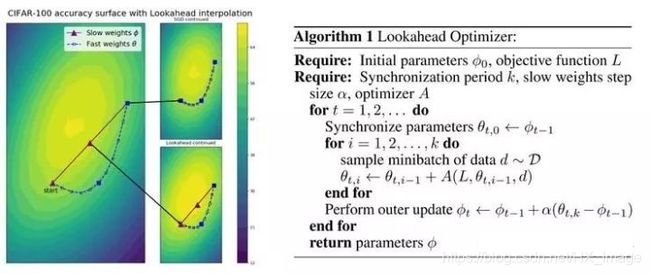
-
训练trick
多尺度训练,对于每一batch,保持batch内的图片尺寸相同,不同batch间的尺寸存在区别,使用多个尺寸的图片对模型进行训练,提高泛化性。
学习率调整,使用带重启的余弦退火最为学习率调整的方式,使得模型对探索较好的局部最优。

-
后处理
-
膨胀预测
膨胀预测的主要思想是每次预测仅仅保留图片的中心部分,其余地方舍弃,而舍 弃的地方通过滑动切割的思想也会成为其他预测图的中心区域,该方法避免因边界的 特征提取问题而产生拼接痕接,影响最终分割效果。

阈值划定
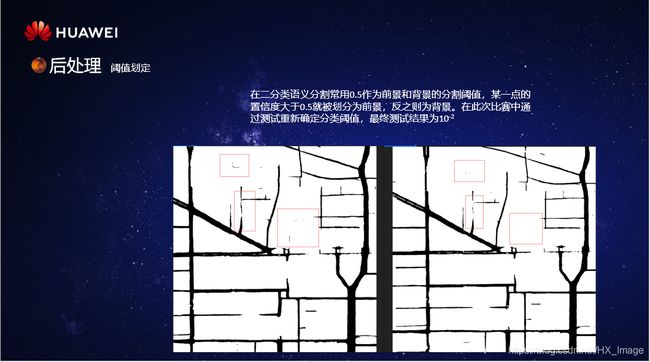
在二分类语义分割常用0.5作为前景和背景的分割阈值,某一点的置信度大于0.5就被划分为前景,反之则为背景。在此次比赛中通过测试重新确定分类阈值,最终测试结果为10-2
下图左侧为正常0.5作为分割阈值,有图为以10-2作为分割阈值。
-
结果与参考文献
最终提交结果为当模型,无TTA等测试时增强操作,模型参数为120M,单张图片(4048*6144)推理时间小于10s(2070super)。
参考文献:
- EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
- U-Net: Convolutional Networks for Biomedical Image Segmentation
- Focal Loss for Dense Object Detection, Tsung-Yi Lin, 2018
- The Lovász-Softmax loss: A tractable surrogate for the optimization of the intersection-over-union measure in neural networks
- Albumentations: Fast and Flexible Image Augmentations
- https://github.com/qubvel/segmentation_models.pytorch
- Stochastic Gradient Descent with Warm Restarts
- Lookahead Optimizer: k steps forward , 1 step back
- Radam:ON THE VARIANCE OF THE ADAPTIVE LEARNING RATE AND BEYOND
- 代码:https://github.com/Hsomething/2020_huawei_road_segmetation