文本摘要常用数据集和方法研究综述
[1]侯圣峦,张书涵,费超群.文本摘要常用数据集和方法研究综述[J].中文信息学报,2019,33(05):1-16.
文章目录
-
- LCSTS
-
- 数据集定义
- NLPCC
-
- 数据集定义
- 自建数据集及其对应方法
-
- 基于统计的方法
- 基于图模型的方法
- 基于词法链的方法
- 基于篇章结构的方法
- 基于机器学习的方法

为了解决抽取式摘要方法缺少训练数据的问题,已有方法通常将用于生成式文本摘要的数据集进行简单转换,例如, Cheng等【参考文献6】将CNN/ Daily Mail数据集中的每篇文本中句子与生成式摘要句计算匹配度,匹配度较高的句子作为抽取式摘要句,构成抽取式摘要方法的数据集。
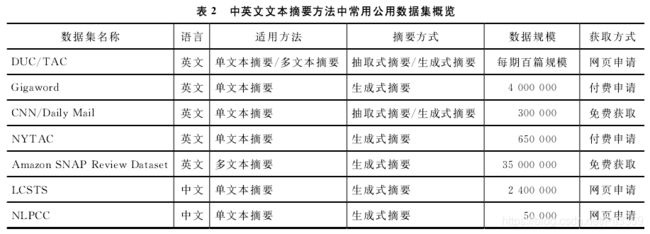
数据集Gigaword、 CNN/ Daily mail、 LASTS等都是十万级规模,可满足深度神经网络训练的需求。
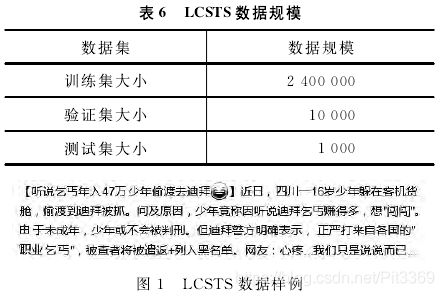
LCSTS
LCSTS(large scale Chinese short text summa rization dataset)链接:http://icrc.hitsz,educn/article/Show/139.html. 是【23—Hu B Chen Q, Zhu F. LCSTS:A large scale Chinese short text summarization dataset】从新浪微博获取的短文本新闻摘要数据库,规模超过200万。
随着微博等社交媒体软件的普及,部分工作提出了面向社交媒体文本的文本摘要算法。由于中文社交媒体文本大都是短文本,具有篇幅较短、存在较多噪声等特点,传统的文本摘要方法在这类文本上往往效果较差。
数据集定义

【24—Ma s, Sun X, XuJ, et al. Improving semantic relevance for Sequence-to- Sequence learning of Chinese social media text summarization】提出面向中文社交媒体短文本摘要的方法,基于深度学习的抽取式摘要,采用循环神经网络的“编码器–解码器”和“注意力”机制。较Hu等【23】的方法有所提升。
NLPCC
自然语言处理与中文计算会议( CCF Conference on Natural Language Processing &.Chinese Computing, NLPCO)是由中国计算机学会(CCF)举办的自然语言文本测评会议,包括文本摘要、情感分析、自动问答等任务。 http://tcci.ccf.org.cn/conference
数据集定义
特点:新闻文本不分领域、不分类型,篇幅较长。

在此数据集上,【25—莫鹏,胡珀,黄湘冀,等。基于超图的文本摘要与关键词协同抽取研究】提出基于超图的文本摘要和关键词生成方法
将句子作为超边(hyperedge),将词作为节点(vertice)构建超图(hypergraph)。
利用超图中句子与词之间的高阶信息来生成摘要和关键词。
【文献26—Xu H, Cao Y, Shang Y, et al. Adversarial reinforcement learning for Chinese text summarization】针对已有的利用极大似然估计来优化的生成式摘要模型存在的准确率低的问题,提出了
一种基于对抗增强学习的中文文本摘要方法,提升了基于深度学习方法在中文文本摘要上的准确率。
方法在LCSTS和NLPCC2015数据集上进行了测评。
自建数据集及其对应方法
基于统计的方法
常用的特征:句子所在位置、TF-IDF、n-gram等
文献27【An effective sentence-extraction technique using contextual information and statistical approaches for text summarization. Pattern Recognition letters,2008.】,提出一种基于上下文特征和统计特征的摘要句提取方法
将每两个相邻的句子合并为一个二元语言模型伪句子( Bi-Gram pseudo sentence,BGPS),BGPS包含比单个句子更多的特征根据统计方法对BGPS进行重要程度打分,选取分值较高的BGPS对应的句子作为摘要句。
基于统计的文本摘要方法较为直观,抽取的特征相对简单,因此方法较易实现,但准确率较低。这类方法同样适用于中文文本摘要任务。
基于图模型的方法
文献【Comments oriented document summarization:understanding documents with readers’ feedback】中,对于web文本,不仅考虑文本内容本身,还将读者的评论信息加入文本摘要抽取
将评论作为节点,评论之间的关系作为边,利用图模型对评论的重要程度进行打分。两种方法:
- 通过评论的关键词来对候选摘要句进行打分;
- 将原文本和评论组成一个“伪文本”,对其进行打分。
文献29【林莉媛,王中卿,李寿山,等.基于PageRank的中文多文档文本情感摘要[J]. 中文信息学报,2014】,提出基于情感信息的PageRank多文本情感摘要方法,考虑了情感和主题两方面信息,数据集来自亚马逊中文网https://www.amazon.cn,收集15个产品的评论语料,每个产品包括200条评论,自建了包括15个主题的多文本摘要数据集。选取48个句子作为该主题的摘要句。
基于词法链的方法
文献31【Chen Y wang x, Guan Y. Automatic text summarization based on lexical chains】,首次将词法链应用到中文,提出了基于词法链的中文文本摘要。
首先利用HowNet作为词法链构建知识库,然后识别强词法链,最后基于启发式规则选取摘要句。
文献32【Yu L, Ma J, Ren F,et al. Automatic text summarization based on lexical chains and structural features 】,提出了基于词法链和结构特征的中文文本摘要方法。
同样利用HowNet构建词法链,结构特征包括句子的位置(如是否为首句)等。利用词法链特征和结构特征进行加权对句子的重要程度进行打分,选取摘要句。
文献33【Wu X,Xic F, Wu U, et al. PNFS; personalized web news filtering and summarization】,提出了个性化Web新闻的过滤和摘要系统PNFS
总结并提取能够刻画新闻主题的关键词。
关键词的提取利用基于词法链的方法[34],利用词之间的语义相关性进行语义消歧并构建词法链。
传统词法链主要由名词和名词短语构成,缺少动词等所包含的语义信息。文献35,提出了全息词法链,包括名词、动词、形容词三类词法链,包括了文章的主要语义信息。根据句子中的全息词法链中的词特征,利用逻辑回归、支持向量机等机器学习方法学习摘要句。
基于篇章结构的方法
文献36【王继成,武港山,周源远,等.一种篇章结构指导的中文Web文档自动摘要方法】,提出中文Web文本自动摘要方法,首先分析段落之间的语义关联,将语义相近的段落合并,划分出主题层次,进而得到篇章结构。在篇章结构的指导下,使用统计的方法,结合启发式规则进行关键词和关键句子的提取,最终生成中文Web文本的摘要。
基于机器学习的方法
文献37【Hu P, He T, Ji D. Chinese text summarization based on thematic area detection】,提出了基于主题的中文单文本摘要方法
首先通过段落聚类发现文本所反映的主题,然后从每一个主题中选取与主题语义相关性最大的一句话作为摘要句,最后根据选取的摘要句在原文本中的顺序组成最终的摘要。
文献38【Baumel T, Cohen R, Elhadad M. Query-chain focused summarization】,提出了基于LDA主题模型的新型文本摘要任务:面向查询的更新摘要方法。
- 更新摘要是:已经提取出来摘要句,在避免冗余的前提下,将新内容加入摘要中。
- 面向查询的摘要:提取出与查询相关的重要句子作为摘要句。
综合以上两点:用户的第n条查询语句得到的结果要在前n-1条查询语句结果的摘要上进行更新摘要。
文献40【庞超,尹传环.基于分类的中文文本摘要方法.计算机科学,2018】,结合循环神经网络的“编码器–解码器”结构和基于分类的结构,提出了一种理解式文本摘要方法。同时在此结构中使用了“注意力”机制,提升了模型对于文本内容的表达能力。
。
文献40【庞超,尹传环.基于分类的中文文本摘要方法.计算机科学,2018】,结合循环神经网络的“编码器–解码器”结构和基于分类的结构,提出了一种理解式文本摘要方法。同时在此结构中使用了“注意力”机制,提升了模型对于文本内容的表达能力。