2020前端面试真题( Vue )
JS部分
HTML + CSS
React
Vue
ES6
webpack,node.js,Git等
1.computed和watch的区别?
computed:
如果不使用计算属性,那么 message.split(’’).reverse().join(’’) 就会直接写到 template 里,那么在模版中放入太多声明式的逻辑会让模板本身过重,尤其当在页面中使用大量复杂的逻辑表达式处理数据时,会对页面的可维护性造成很大的影响,而且计算属性如果依赖不变的话,它就会变成缓存,computed 的值就不会重新计算。而且他返回的是一个值,同时也不能进行异步操作。所以就有了watch。
watch也是用来监听数据的变化的,watch与computed的区别就是它支持异步,不支持缓存。而且watch在第一次监听的时候不会触发,想要触发必须得在第二个参数上面配置(immeiate)。此外还有另外一个参数是deep,可以用来深度监听一个数组或者是对象。
2. v-if 和 v-show 区别
详情链接
3.vue中的key 官网
key主要用在 Vue 的虚拟 DOM 算法,在新旧 nodes 对比时辨识 VNodes。如果不使用 key,Vue 会使用一种最大限度减少动态元素并且尽可能的尝试就地修改/复用相同类型元素的算法。而使用 key 时,它会基于 key 的变化重新排列元素顺序,并且会移除 key 不存在的元素。所以key 的作用主要是为了高效的更新虚拟 DOM。
4.vue路由懒加载方式 vue官网介绍
- vue异步组件
{
path: '/path',
name: 'componentName',
component: resolve => require(['@/componentPath'], resolve),
}
- import按需加载(官方写法)
能够被webpack自动代码分割
允许将不同的组件打包到一个异步块中,使用命名chunk(特殊注释语法)。
Webpack 会将任何一个异步模块与相同的块名称组合到相同的异步块中。
const comA = () => import('url')
const Foo = () => import(/* webpackChunkName: "group-foo" */ './Foo.vue')
const Bar = () => import(/* webpackChunkName: "group-foo" */ './Bar.vue')
const Baz = () => import(/* webpackChunkName: "group-foo" */ './Baz.vue')
- webpack提供的require.ensure()
vue-router配置路由,使用webpack的require.ensure技术,也可以实现按需加载。
这种情况下,多个路由指定相同的chunkName,会合并打包成一个js文件。
{
path: '/home', name: 'home',
component: r =>require.ensure([], () => r(require('@/components/home')), 'demo')
}
5. Vue的性能优化
6. nextTick知道吗,实现原理是什么
链接
7.介绍一下Vue中父子组件生命周期的执行顺序 Vue生命周期图解
- 加载渲染过程
父 beforeCreate -> 父 created -> 父 beforeMount -> 子 beforeCreate -> 子 created -> 子 beforeMount -> 子 mounted -> 父 mounted
- 子组件更新过程
父 beforeUpdate -> 子 beforeUpdate -> 子 updated -> 父 updated
- 父组件更新过程
父 beforeUpdate -> 父 updated
- 销毁过程
父 beforeDestroy -> 子 beforeDestroy -> 子 destroyed -> 父 destroyed
8.Vue父子组件的通信方式有哪些 链接
9.Vue中响应式的原理(数据的双向绑定)
Vue的响应式原理也就是数据的双向绑定原理,数据双向绑定主要是指:数据变化更新视图,视图变化更新数据。
Vue 主要通过以下 4 个步骤来实现数据双向绑定的:
-
实现一个监听器 Observer:对数据对象进行遍历,包括子属性对象的属性,利用 Object.defineProperty() 对属性都加上 setter 和 getter。这样的话,给这个对象的某个值赋值,就会触发 setter,那么就能监听到了数据变化。
-
实现一个解析器 Compile:解析 Vue 模板指令,将模板中的变量都替换成数据,然后初始化渲染页面视图,并将每个指令对应的节点绑定更新函数,添加监听数据的订阅者,一旦数据有变动,收到通知,调用更新函数进行数据更新。
-
实现一个订阅者 Watcher:Watcher 订阅者是 Observer 和 Compile 之间通信的桥梁 ,主要的任务是订阅 Observer 中的属性值变化的消息,当收到属性值变化的消息时,触发解析器 Compile 中对应的更新函数。
-
实现一个订阅器 Dep:订阅器采用 发布-订阅 设计模式,用来收集订阅者 Watcher,对监听器 Observer 和 订阅者 Watcher 进行统一管理。
10.vue中 computed 的使用及其原理 链接
Vue 响应式系统的核心理念是“依赖”,DOM 节点之所以随数据而变化,是因为节点依赖于数据,
计算属性之所以随数据而变化,是因为计算属性依赖于数据。做好响应式的关键就在于处理好依赖关系。
11.Vue 中 computed 和 watcher 的区别
- watcher 顾名思义就是监听数据变化,它监听的数据来自 props、data、computed 的数据。他有两个参数分别是 newValue 和 oldValue。watcher 默认是浅监听,如果想要深度监听的话可以加一个deep:true;
- computed 用于处理复杂的逻辑运算,比较适合对多个变量或者对象进行处理后返回一个结果值
- computed 支持缓存,只有依赖数据发生改变,才会重新进行计算;watcher 不支持缓存,数据变,直接会触发相应的操作
- computed 不支持异步,当computed内有异步操作时无效,无法监听数据的变化。watch 支持异步。
12.v-on可以绑定多个方法吗
如果需要绑定多个不同类型的事件的话,可以以对象的键值对形式,比如在v-on上绑定一个click和mouseover事件,我们可以使用v-on=“{click:方法名,mouseover:方法名}”
如果需要绑定多个相同类型的事件的话,直接以逗号分隔方法名,比如绑定click事件,我们可以写@click="方法1,方法2"
13.vue组件中data为什么必须是一个函数?
这是由于JavaScript的特性导致的,在component中,data必须是以函数的形式存在,不可以是对象。
在组件中的data写出一个函数,数据以函数返回值的形式定义,这样每次复用组件的时候,都会返回一份新的data,相当于每个组件实例都有自己私有的数据空间,他们只需要负责维护各自的数据,不会造成混乱。而单纯写成对象形式的话,就是所有的组件实例共用一个data,这样改一个全都改了。
14.请说下封装 vue 组件的过程?
- 首先建立组件的模板,先把架子搭起来,然后考虑好组件的样式和基本逻辑结构。
- 准备好组件的数据输入,即分析好逻辑,确定好 props里面的数据、类型
- 准备好组件的数据输出,即根据组件逻辑,做好要暴露出来的方法
- 封装完毕后,直接调用即可。
15.vue中router-link和传统a链接的区别
• a标签相当于重新打开一个新的网页,从一张页面跳转到另一张页面,单单从这里来说就违背了多视图的单页Web应用这个概念。 通过a标签进行跳转,页面会被重新渲染,即,体现为视觉上的“闪烁”(如果是本地的项目基本看不出来)
• 组件支持用户在具有路由功能的应用中 (点击) 导航。 通过 to 属性指定目标地址,默认渲染成带有正确链接的 a 标签,可以通过配置 tag 属性生成别的标签.。 通过router-link进行跳转不会跳转到新的页面,也不会重新渲染,它会选择路由所指的组件进行渲染,避免了重复渲染的“无用功”。
总结:对比 a,router-link组件避免了不必要的重渲染,它只更新变化的部分从而减少DOM性能消耗
16.说一下VueRouter 的 hash 模式和 history的区别
VueRouter 路由的存在是因为出于对单页面应用的开发,需要引入前端路由系统。它的实现实际上是利用浏览器自身的 hash 和 history 两种模式,核心就在于改变页面视图的同时不会向后端发送请求。默认为hash模式,通过onhashchange方法进行URL地址栏的判断,也就是监听#后面的值的变化做出响应,它的兼容性更好,对低版本浏览器和IE浏览器都支持;
history模式是 H5新推出的API,简洁美观;它的pushState 和 replaceState 方法可以实现将 url 替换并且不刷新页面,这就要求前后端的URL必须一致,如果后端缺少对该路径的路由处理,就会 404 ,而hash模式而言,只有#之前的内容会被包含在请求之中,即使没有做到对路由的全覆盖,也不会返回404错误
17.keep-alive 组件有什么作用?
vue在切换页面的时候会将原来的组件注销掉然后渲染新的组件,看似一样实则每次打开的都是新页面。如果我们需要在页面切换的时候,不让他重新渲染,就可以使用 keep-alive 组件包裹需要保存的组件。
对于 keep-alive 组件来说,它拥有两个独有的生命周期钩子函数,分别为 activated 和 deactivated 。
用 keep-alive 包裹的组件在切换时不会进行销毁,而是缓存到内存中并执行 deactivated 钩子函数,根据缓存渲染后会执行 actived 钩子函数。
假设一个页面比较长,每次切换重新渲染的话都要在页面顶端开始浏览,这对用户来说不太友好。如果我们使用keep-alive每次切换页面前将状态存到内存中,然后返回时再从内存中读取,每次打开都是上次浏览的地方,相对体验比较好
18.对Vue的理解
Vue是一个用于创建用户界面的开源JavaScript框架,也是一个创建单页应用的Web应用框架。Vue所关注的核心是MVC模式中的视图层,同时,它也能方便地获取数据更新,并通过组件内部特定的方法实现视图与模型的交互。
vue的核心特性
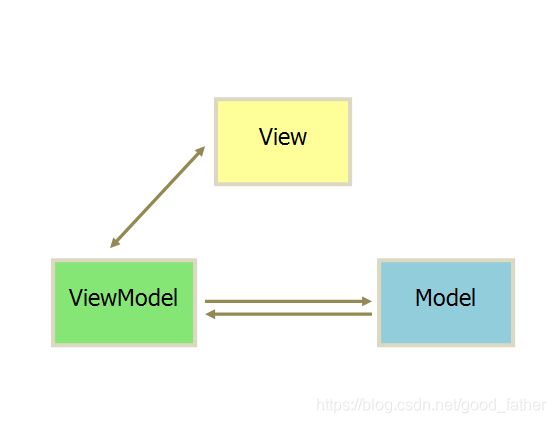
1.数据驱动(MVVM)
MVVM表示的是 Model-View-ViewModel
- Model:模型层,负责处理业务逻辑以及和服务器端进行交互
- View:视图层:负责将数据模型转化为UI展示出来,可以简单的理解为HTML页面
- ViewModel:视图模型层,用来连接Model和View,是Model和View之间的通信桥梁
2.组件化
1.什么是组件化?
一句话来说就是把图形、非图形的各种逻辑均抽象为一个统一的概念(组件)来实现开发的模式,在Vue中每一个.vue文件都可以视为一个组件
2.组件化的优势
- 降低整个系统的耦合度,在保持接口不变的情况下,我们可以替换不同的组件快速完成需求,例如输入框,可以替换为日历、时间、范围等组件作具体的实现
- 调试方便,由于整个系统是通过组件组合起来的,在出现问题的时候,可以用排除法直接移除组件,或者根据报错的组件快速定位问题,之所以能够快速定位,是因为每个组件之间低耦合,职责单一,所以逻辑会比分析整个系统要简单
- 提高可维护性,由于每个组件的职责单一,并且组件在系统中是被复用的,所以对代码进行优化可获得系统的整体升级
3.指令系统
指令 (Directives) 是带有 v- 前缀的特殊属性作用:当表达式的值改变时,将其产生的连带影响,响应式地作用于 DOM
常用的指令
- 条件渲染指令 v-if
- 列表渲染指令v-for
- 属性绑定指令v-bind
- 事件绑定指令v-on
- 双向数据绑定指令v-model
3.Vue跟传统开发的区别
- Vue所有的界面事件,都是只去操作数据的
- Vue所有界面的变动,都是根据数据自动绑定出来的
4.Vue和React对比
相同点
- 都有组件化思想
- 都支持服务器端渲染
- 都有Virtual DOM(虚拟dom)
- 数据驱动视图
- 都有支持native的方案:Vue的weex、React的React native
- 都有自己的构建工具:Vue的vue-cli、React的Create React App
区别 - 数据变化的实现原理不同。react使用的是不可变数据,而Vue使用的是可变的数据
- 组件化通信的不同。react中我们通过使用回调函数来进行通信的,而Vue中子组件向父组件传递消息有两种方式:事件和回调函数
- diff算法不同。react主要使用diff队列保存需要更新哪些DOM,得到patch树,再统一操作批量更新DOM。Vue 使用双向指针,边对比,边更新DOM
19.说说你对SPA(单页应用)的理解?
单页应用与多页应用的区别
| 单页面应用(SPA) | 多页面应用(MPA) | |
|---|---|---|
| 组成 | 一个主页面和多个页面片段 | 多个主页面 |
| 刷新方式 | 局部刷新 | 整页刷新 |
| url模式 | 哈希模式 | 历史模式 |
| SEO搜索引擎优化 | 难实现,可使用SSR方式改善 | 容易实现 |
| 数据传递 | 容易 | 通过url、cookie、localStorage等传递 |
| 页面切换 | 速度快,用户体验良好 | 切换加载资源,速度慢,用户体验差 |
| 维护成本 | 相对容易 | 相对复杂 |
单页应用优缺点
优点:
1.具有桌面应用的即时性、网站的可移植性和可访问性
2.用户体验好、快,内容的改变不需要重新加载整个页面
3.良好的前后端分离,分工更明确
缺点:
1.不利于搜索引擎的抓取
2.首次渲染速度相对较慢
如何给SPA做SEO?
-
SSR服务端渲染
将组件或页面通过服务器生成html,再返回给浏览器,如nuxt.js -
静态化
目前主流的静态化主要有两种:
(1)一种是通过程序将动态页面抓取并保存为静态页面,这样的页面的实际存在于服务器的硬盘中
(2)另外一种是通过WEB服务器的 URL Rewrite的方式,它的原理是通过web服务器内部模块按一定规则将外部的URL请求转化为内部的文件地址,一句话来说就是把外部请求的静态地址转化为实际的动态页面地址,而静态页面实际是不存在的。这两种方法都达到了实现URL静态化的效果 -
使用Phantomjs针对爬虫处理
原理是通过Nginx配置,判断访问来源是否为爬虫,如果是则搜索引擎的爬虫请求会转发到一个node server,再通过PhantomJS来解析完整的HTML,返回给爬虫。
20.Vue的生命周期
| 生命周期 | 描述 | 作用 |
|---|---|---|
| beforeCreate | 组件实例被创建之初 | 执行时组件实例还未创建,通常用于插件开发中执行一些初始化任务 |
| created | 组件实例已经完全创建 | 组件初始化完毕,各种数据可以使用,常用于异步数据获取 |
| beforeMount | 组件挂载之前 | 未执行渲染、更新,dom未创建 |
| mounted | 组件挂载到实例上去之后 | 初始化结束,dom已创建,可用于获取访问数据和dom元素 |
| beforeUpdate | 组件数据发生变化,更新之前 | 更新前,可用于获取更新前各种状态 |
| updated | 数据数据更新之后 | 更新后,所有状态已是最新 |
| beforeDestroy | 组件实例销毁之前 | 销毁前,可用于一些定时器或订阅的取消 |
| destroyed | 组件实例销毁之后 | 组件已销毁,作用同上 |
| activated keep-alive | 缓存的组件激活时 | |
| deactivated keep-alive | 缓存的组件停用时调用 | |
| errorCaptured | 捕获一个来自子孙组件的错误时被调用 |
具体分析
beforeCreate -> created
- 初始化vue实例,进行数据观测
created
- 完成数据观测,属性与方法的运算,watch、event事件回调的配置
- 可调用methods中的方法,访问和修改data数据触发响应式渲染dom,可通过computed和watch完成数据计算
- 此时vm.$el 并没有被创建
created -> beforeMount
- 判断是否存在el选项,若不存在则停止编译,直到调用vm.$mount(el)才会继续编译
- 优先级:render > template > outerHTML
- vm.el获取到的是挂载DOM的
beforeMount
- 在此阶段可获取到vm.el
- 此阶段vm.el虽已完成DOM初始化,但并未挂载在el选项上
beforeMount -> mounted
- 此阶段vm.el完成挂载,vm.$el生成的DOM替换了el选项所对应的DOM
mounted
- vm.el已完成DOM的挂载与渲染,此刻打印vm.$el,发现之前的挂载点及内容已被替换成新的DOM
beforeUpdate
- 更新的数据必须是被渲染在模板上的(el、template、render之一)
- 此时view层还未更新
- 若在beforeUpdate中再次修改数据,不会再次触发更新方法
updated
- 完成view层的更新
- 若在updated中再次修改数据,会再次触发更新方法(beforeUpdate、updated)
beforeDestroy
- 实例被销毁前调用,此时实例属性与方法仍可访问
destroyed
- 完全销毁一个实例。可清理它与其它实例的连接,解绑它的全部指令及事件监听器
并不能清除DOM,仅仅销毁实例
数据请求在created和mouted的区别
created是在组件实例一旦创建完成的时候立刻调用,这时候页面dom节点并未生成mounted是在页面dom节点渲染完毕之后就立刻执行的触发时机上created是比mounted要更早的两者相同点:都能拿到实例对象的属性和方法讨论这个问题本质就是触发的时机,放在mounted请求有可能导致页面闪动(页面dom结构已经生成),但如果在页面加载前完成则不会出现此情况建议:放在create生命周期当中
21.为什么Vue中的v-if和v-for不建议一起用?
二者的作用
- v-if 指令用于条件性地渲染一块内容。这块内容只会在指令的表达式返回 true值的时候被渲染
- v-for 指令基于一个数组来渲染一个列表。v-for 指令需要使用 item in items 形式的特殊语法,其中 items 是源数据数组或者对象,而 item 则是被迭代的数组元素的别名,在 v-for 的时候,建议设置key值,并且保证每个key值是独一无二的,这便于diff算法进行优化
优先级
v-for优先级是比v-if高 : 也就是说,在组件中,Vue会先遍历数组,在进行条件判断,会造成不必要的性能损耗。
注意事项
- 永远不要把 v-if 和 v-for 同时用在同一个元素上,带来性能方面的浪费(每次渲染都会先循环再进行条件判断)
- 如果避免出现这种情况,则在外层嵌套template(页面渲染不生成dom节点),在这一层进行v-if判断,然后在内部进行v-for循环
- 如果条件出现在循环内部,可通过计算属性computed提前过滤掉那些不需要显示的项