读书笔记数据科学入门————可视化数据
本章摘要
数据可视化是数据科学家的重要部分。创建可视化的目的:探索数据,交流数据。
本章利用一个外置的matplotlib库的配置进行可视化的初步了解
matplotlib的配置
许多工具可以可视化数据,目前应用很广的是matplotlib库,在windows下配置该模块稍微比较麻烦,下面会一步一步讲解:
Matplotib 是python 的一个绘图库,里头有各种各样的绘图方法,可以用Matplotib 显示图像,放大图像,保存图像等等,对于OpenCV处理图像具有非常大的帮助。
如果是下载的库带有exe安装程序,可以直接进行安装,同时会定位到Python安装的位置。
如果下载的库是py文件那么需要用命令行进行安装:
Python第三方模块中一般会自带setup.py文件,在Windows环境下,我们只需要使用cmd命令:
cd c:\python\..
python setup.py install
那么所需要下载模块到底有哪些呢:
Numpy,SciPy,MatplotLib
下载Numpy,SciPy,MatplotLib这三个库的exe,注意,这里用的是exe,因为MatplotLib的使用需要以Numpy的支持,所以最好先装NumPy再装MatplotLib。下载地址:
NumPy: http://sourceforge.net/projects/numpy/files/NumPy/1.9.2/
SciPy: http://sourceforge.net/projects/scipy/files/scipy/0.15.1/
MatPlotLib: http://matplotlib.org/downloads.html
当出现各种报错的时候,然后进行测试的时候一般会出现很多问题都是确实某某模块的问题,这些模块举例如下:
1. No module name six
对于报这个错误的时候需要下载six模块
http://www.pythonhosted.org/six/
解压之后,进入解压目录,命令行执行 python setup.py install 就可以安装完成。
2. ImportError: matplotlib requires dateutil
https://pypi.python.org/pypi/python-dateutil/1.4.1
同样到解压目录下,执行 python setup.py install 同样可以安装成功,
3. ImportError: matplotlib requires pyparsinghttp://sourceforge.net/projects/pyparsing/files/pyparsing/pyparsing-2.0.3/
下载pyparsing-2.0.3.win32-py2.6.exe,双击运行,安装完成====
以上缺少的模块以及应对各种模块不同安装方法如上。
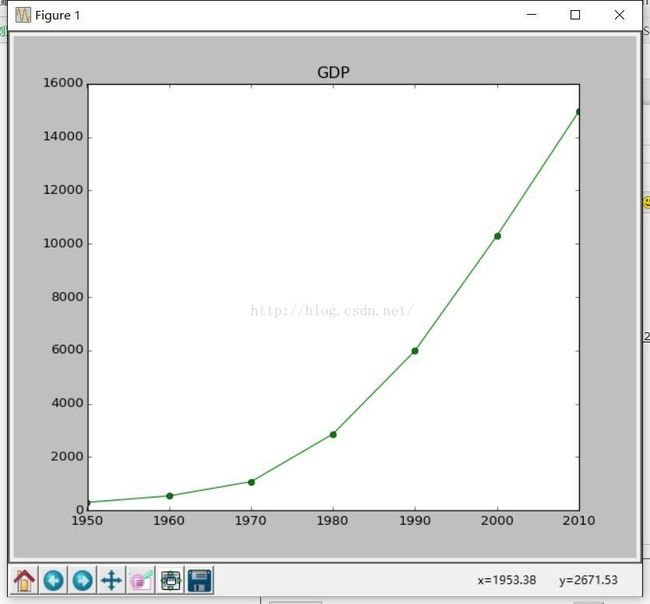
测试程序如下:
>>> from matplotlib import pyplot as plt
>>> years = [1950,1960,1970,1980,1990,2000,2010]
>>> gdp=[300.2,543.3,1075.9,2862.5,5979.6,10289.7,14958.3]
>>> plt.plot(years,gdp,color='green',marker='o',linestyle='solid')
>>> plt.title('GDP')
各种图形的绘制
条形图
>>> num_oscars=[5,11,3,8,10]
>>> xs = [i+0.1 for i,_ in enumerate(moveies)]
>>> from matplotlib import pyplot as plt
>>> plt.bar(xs,num_oscars)//设置条形图高度和宽度
>>> plt.xticks([i+0.5 for i,_ in enumerate(movies)],movies)//设置X轴的变量名字
([
>>> plt.show()

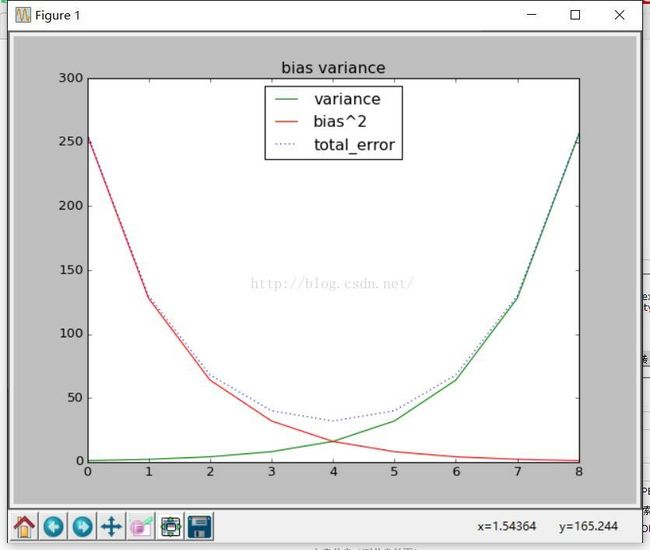
线图
>>> bias_squared=[256,128,64,32,16,8,4,2,1]
>>> total_error=[x+y for x,y in zip(variance,bias_squared)]
>>> total_error
[257, 130, 68, 40, 32, 40, 68, 130, 257]
>>> xs = [i for i,_ in enumerate(variance)]
>>> xs
[0, 1, 2, 3, 4, 5, 6, 7, 8]
[
>>> plt.plot(xs,bias_squared,'r-',label='bias^2')
[
>>> plt.legend(loc=9)
>>> plt.show()
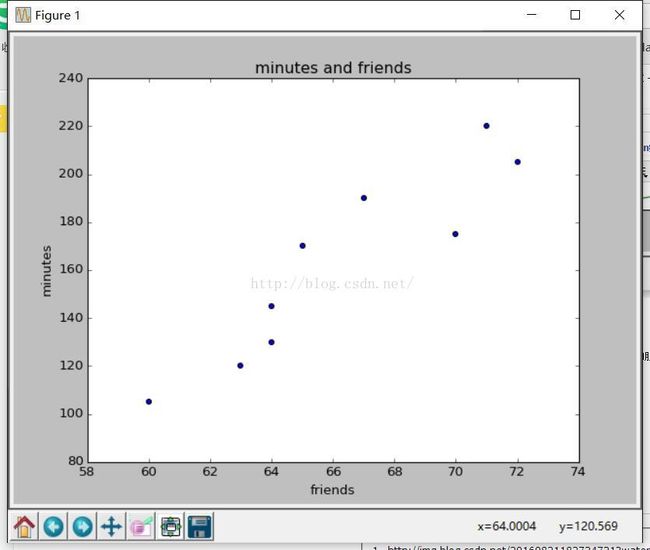
散点图
>>> minutes=[175,170,205,120,220,130,105,145,190]
>>> labels = ['a','b','c','d','e','f','g','h','i']
>>> plt.scatter(friends,minutes)
>>> plt.title('minutes and friends')
>>> plt.xlabel('friends')
>>> plt.ylabel('minutes')
>>> plt.show()