python爬虫之之Requests库使用以及网络视频图片的爬取和存储
通常我们上网是由用户端计算机发送请求给目标计算机,将目标计算机的数据下载到本地的过程。例如我们通过浏览器谷歌搜索某个内容便是向浏览器提交请求,然后下载网页代码将该请求解析成网页呈现。而爬虫就是模拟我们浏览器发送请求的过程,并根据自己设置的爬取规则提取有用的数据最终将数据放在数据库或文件中。

互联网中最有价值的便是数据,比如淘宝的商品信息,各大求职网站上的职位信息等等。这些数据对我们了解行业信息十分重要。而爬虫就是用来高效地挖掘这些宝藏,掌握了爬虫技能,你就能免费获得许多有价值的数据。当然我们在爬取网页内容的时候也要遵循法律,不能任意爬取私密信息。一般网站都会发布公告Robots协议,告知所有爬虫网站的爬取策略,哪些页面可以抓取,哪些不行。一般会包含在网站根目录下,文件为robots.txt。
# Robots协议基本语法 ,*代表所有,/代表根目录
User‐agent: *
Disallow: /下面我们将介绍爬虫常用的几个库以及常用的爬虫库。
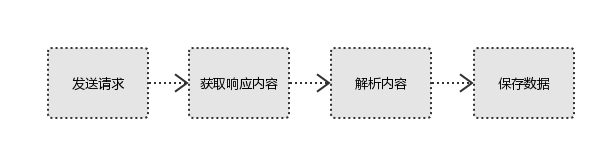
我们首先介绍HTTP协议:
HTTP协议
HTTP,Hypertext Transfer Protocol,超文本传输协议。HTTP是一个基于“请求与响应”模式的、无状态的应用层协议。HTTP协议采用URL作为定位网络资源的标识,URL格式如下:
http://host[:port][path]
host: 合法的Internet主机域名或IP地址
port: 端口号,缺省端口为80
path: 请求资源的路径
URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源。
HTTP协议对资源访问操作通过URL和命令管理资源,操作独立无状态,网络通道及服务器成为了黑盒子,常见的操作方法包括:
GET 请求获取URL位置的资源
HEAD 请求获取URL位置资源的响应消息报告,即获得该资源的头部信息
POST 请求向URL位置的资源后附加新的数据
PUT 请求向URL位置存储一个资源,覆盖原URL位置的资源
PATCH 请求局部更新URL位置的资源,即改变该处资源的部分内容
DELETE 请求删除URL位置存储的资源
![]()
PATCH 和 PUT 的区别:
假设URL位置有一组数据UserInfo,包括UserID、UserName等20个字段
需求:用户修改了UserName,其他不变
• 采用PATCH,仅向URL提交UserName的局部更新请求
• 采用PUT,必须将所有20个字段一并提交到URL,未提交字段被删除
PATCH的最主要好处:节省网络带宽
Requests库
Requests库官方链接地址 :http://www.python-requests.org
Requests库的常用方法:
![]()
requests.request() 构造一个请求,支撑以下各方法的基础方法
requests.get() 获取HTML网页的主要方法,对应于HTTP的GET
requests.head() 获取HTML网页头信息的方法,对应于HTTP的HEAD
requests.post() 向HTML网页提交POST请求的方法,对应于HTTP的POST
requests.put() 向HTML网页提交PUT请求的方法,对应于HTTP的PUT
requests.patch() 向HTML网页提交局部修改请求,对应于HTTP的PATCH
requests.delete() 向HTML页面提交删除请求,对应于HTTP的DELETE
![]()

Request:用户将自己的信息通过浏览器(socket client)发送给服务器(socket server)
Response:服务器接收请求,分析用户发来的请求信息,然后返回数据(返回的数据中可能包含其他链接,如:图片,js,css等),Response对象包含服务器返回的所有信息,也包含请求的Request信息。
requests.request(method, url, **kwargs)
∙ method : 请求方式,对应get/put/post等7种
∙ url : 拟获取页面的url链接
∙ **kwargs: 控制访问的参数,共13个
**kwargs参数列表:
params:字典或字节序列,作为参数增加到url中。
kv = {'key1': 'value1', 'key2': 'value2'}
r = requests.request('GET', 'http://www.baidu.com/ws', params=kv)
print(r.url)
http://www.baidu.com/ws?key1=value1&key2=value2data: 字典、字节序列或文件对象,作为Request的内容
>>> kv = {'key1': 'value1', 'key2': 'value2'}>>> r = requests.request('POST', 'http://www.baidu.com/ws', data=kv)>>> body = '主体内容'>>> r = requests.request('POST', 'http://www.baidu.com/ws', data=body)
json : JSON格式的数据,作为Request的内容
kv = {'key1': 'value1'}>>> r = requests.request('POST', 'http://www.baidu.com/ws', json=kv)
headers : 字典,HTTP定制头,通过设置'user‐agent'参数可以让限制性网页将爬虫访问视为电脑用户的正常访问。比较重要的参数
python爬虫的限制:
来源审查:判断User‐Agent进行限制
检查来访HTTP协议头的User‐Agent域,只响应浏览器或友好爬虫的访问
>>> hd = {'user‐agent': 'Chrome/10'}>>> r = requests.request('POST', 'http://www.baidu.com/ws', headers=hd)
cookies : 字典或CookieJar,Request中的cookie
auth : 元组,支持HTTP认证功能
files : 字典类型,传输文件
>> fs = {'file': open('data.xls', 'rb')}>>> r = requests.request('POST', 'http://www.baidu.com/ws', files=fs)
timeout : 设定超时时间,秒为单位,比较重要的参数
>>> r = requests.request('GET', 'http://www.baidu.com', timeout=10)proxies : 字典类型,设定访问代理服务器,可以增加登录认证
allow_redirects : True/False,默认为True,重定向开关
stream : True/False,默认为True,获取内容立即下载开关
verify : True/False,默认为True,认证SSL证书开关
cert : 本地SSL证书路径
requests.get(url, params=None, **kwargs)
∙ url : 拟获取页面的url链接
∙ params : url中的额外参数,字典或字节流格式,可选
∙ **kwargs: 12个控制访问的参数
requests.head(url, **kwargs)
requests.post(url, data=None, json=None, **kwargs)
requests.put(url, data=None, **kwargs)
requests.patch(url, data=None, **kwargs)
requests.delete(url, **kwargs)
Requests 库的post()方法:
# 向URL POST一个字典自动编码为form(表单)>>> payload = {'key1': 'value1', 'key2': 'value2'}>>> r = requests.post('http://httpbin.org/post', data = payload)>>> print(r.text){ ..."form": {"key2": "value2","key1": "value1"},}
# 向URL POST一个字符串自动编码为data>>> r = requests.post('http://httpbin.org/post', data = 'ABC')>>> print(r.text){ ..."data": "ABC""form": {},}
Response 对象属性![]()
r.status_code HTTP请求的返回状态,200表示连接成功,404表示失败。
r.text HTTP响应内容的字符串形式,即,url对应的页面内容,并且根据r.encoding显示网页内容。
r.encoding 从HTTP header中猜测的响应内容编码方式,如果header中不存在charset,则认为编码为ISO‐8859‐1。
r.apparent_encoding 从内容中分析出的响应内容编码方式(备选编码方式)。
r.content HTTP响应内容的二进制形式。
由于网络爬虫是一种非正常的网页访问方式,存在很大的风险,因此异常处理非常重要。
Requests库的异常处理方法
![]()
requests.ConnectionError 网络连接错误异常,如DNS查询失败、拒绝连接等
requests.HTTPError HTTP错误异常
requests.URLRequired URL缺失异常
requests.TooManyRedirects 超过最大重定向次数,产生重定向异常
requests.ConnectTimeout 连接远程服务器超时异常
requests.Timeout 请求URL超时,产生超时异常
![]()
例如:
r.raise_for_status() # 如果不是200,产生异常 requests.HTTPError根据上面我们介绍到的爬虫流程,可以总结出Requests库爬取网页内容的通用流程框架。
import requests
def getHTMLText(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except :
return "产生异常"
if __name__ == "__main__":
url = "http://www.baidu.com"
print(getHTMLText)
示例:网络视频图片的爬取和存储
import requests
import re
import time
import hashlib
def get_page(url):
print('GET %s' %url)
try:
response=requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return response.content
except Exception:
pass
def parse_index(res):
obj=re.compile('class="items.*? 0:
movie_url=res[0]
return movie_url
def save(movie_url):
response=requests.get(movie_url,stream=False)
if response.status_code == 200:
m=hashlib.md5()
m.update(('%s%s.mp4' %(movie_url,time.time())).encode('utf-8'))
filename=m.hexdigest()
with open(r'./movies/%s.mp4' %filename,'wb') as f:
f.write(response.content)
f.flush()
def main():
index_url='http://www.xiaohuar.com/list-3-{0}.html'
for i in range(5):
print('*'*50,i)
#爬取主页面
index_page=get_page(index_url.format(i,))
#解析主页面,拿到视频所在的地址列表
detail_urls=parse_index(index_page)
#循环爬取视频页
for detail_url in detail_urls:
#爬取视频页
detail_page=get_page(detail_url)
#拿到视频的url
movie_url=parse_detail(detail_page)
if movie_url:
#保存视频
save(movie_url)
if __name__ == '__main__':
main()
扫描二维码学习了解更多关于python、机器学习、Linux系统以及开源软件的知识
