第37天 脏读 不可重复读 幻读 行级锁(共享锁,排它锁,死锁现象)表级锁 页级锁 innodb存储引擎 innodb三种行锁的算法 事务隔离级别 乐观锁与悲观 mvcc机制锁
脏读(无效的数据)
a事务把数据改完之后并没有提交,b事务读到这个改完数据之后的事务,
b事务读完之后,a事务又把数据做了一个回滚操作,这种现象叫脏读
不可重复读
a事务把数据读完拿去用了,b事务刚好直接把数据给改了,并且提交了,
a事务会发现之前读的数据不准确了
幻读现象
是不可重复读的一种特殊现象,
举例:假设一张表一共有10条数据,a事务把id大于3的数据name全部改成了xx,
就在刚刚改完的那一刻,b事务又插入一条数据,a事务改完之后,会发现有一条数据没有修改成功
以上现象都是并发带来的一些问题,mysql的底层机制已经帮忙解决好了
针对这些问题的解决,数据库设计了锁机制,事务隔离机制,mvcc多版本机制。
加锁会提高数据安全,降低运行效率
按锁的粒度划分,可分为行级锁、表级锁、页级锁。(mysql支持)
行级锁
特点:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突概率最低,并发也最高
支持引擎:innodb
行级锁定分为行共享锁(共享锁)与独行写锁(排他锁)
表级锁
特点:开销小,枷锁快;不会出现死锁;锁粒度大,发出锁冲突的概率最高,并发度低
支持引擎:myisam,memory,innodb
分类:表级锁定分为表共享读锁(共享锁)与表独占写锁(排他锁)
页级锁
特点:开销和加锁时间界与表锁和行锁之间;会出现死锁,锁定粒度界于表锁和行锁之间,并发度一般
行级锁
按锁级别划分,可分为共享锁、排他锁
行级锁之共享锁与排他锁
行级锁分为共享锁和排他锁两种。
排他锁又称为写锁,简称X锁,顾名思义,排他锁就是不能与其他所并存,如一个事务获取了一个数据行的排他锁,其他事务就不能再对该行加任何类型的其他他锁(共享锁和排他锁),但是获取排他锁的事务是可以对数据就行读取和修改。
共享锁又称为读锁,简称S锁,顾名思义,共享锁就是多个事务对于同一数据可以共享一把锁,获准共享锁的事务只能读数据,不能修改数据直到已释放所有共享锁,所以共享锁可以支持并发读(大家只能读不能改)。
与行处理相关的sql有:insert、update、delete、select,这四类sql在操作记录行时,可以为行加上锁,但需要知道的是:
对于insert、update、delete语句,InnoDB会自动给涉及的数据加锁,而且是排他锁(X);
代码演示:
开启两个cdm命令端(a端口,b端口)
a端口输入:
use test;
begin;
update blog set name = "666" where id = 1;
b端口输入:
use test;
update blog set name = "777" where id = 1;
a端口加了互斥锁,b端口就不能再加锁了,只有等a端口把锁释放了,b端口才能加锁
a端口输入命令后会直接卡住,当a端口输入commit或者rollback结束事务的后,
b端口的sql命令会直接运行并且会把id为1的name改成777
对于普通的select语句,InnoDB不会加任何锁,需要我们手动自己加,可以加两种类型的锁
1. 排他锁语法(X):select ... for update; -- 查出的记录行都会被锁住
代码演示:
开启两个cdm命令端(a端口,b端口)
a端口输入:
use test;
begin;
select * from blog where id = 3 for update; # 直接锁住id=3的字段
b端口输入:
use test;
begin;
select * from blog; # 查询blog表正常
update blog set name ="66" where id = 3;
a端口输入命令后会直接卡住,当a端口输入commit或者rollback结束事务的后,
b端口的sql命令会直接运行并且会把id为1的name改成666
select查询不受锁影响,如果我们只是为了锁住数据,不涉及增删改,那么就用select ... for update;来进行锁
注意:innodb锁如果有锁带索引的id字段,那么就锁命中的行
innodb锁如果没有带索引的id字段,那么就锁整个索引(没有命中索引,就相当于表锁)
2. 共享锁语法(S):select ... lock in share mode; -- 查出的记录行都会被锁住
代码演示:
开启两个cdm命令端(a端口,b端口)
a端口输入:
use test;
begin;
select * from blog where id = 4 lock in share mode; # 共享锁锁住id=4的字段
update blog set name = "yyy" where id = 4; # b端没有加共享锁的之前,可以直接在端口修改(可以加互斥锁)
update blog set name = "zzz" where id = 4; # b端加了共享锁之后,无法修改(无法加互斥锁)
b端口输入:
use test;
begin;
update blog set name = "xxx" where id = 4; # a端口加了共享锁之后,无法修改(无法加互斥锁)
select * from blog where id = 4 lock in share mode; # 共享锁锁住id=4的字段
a端口共享锁锁住id=4的字段,b端口对id=4的字段进行修改,直接卡住(update默认加互斥锁),
b端没有加共享锁的之前,a端口可以直接在端口修改name="yyy"。(事务a端口可以对数据加互斥锁)
当b端口加了共享锁之后,a端口将name修改成"zzz"直接卡住(b端口加了共享锁,a端口无法再加互斥锁)
死锁
代码演示:
开启两个cdm命令端(a端口,b端口)
a端口输入:
use test;
begin;
select * from blog where id = 4 lock in share mode; # 共享锁锁住id=4的字段(第一步)
update blog set name = "yyy" where id = 2; # b端口共享锁锁住id=2的字段,加互斥锁直接卡住(第三步)
b端口输入:
use test;
begin;
select * from blog where id = 2 lock in share mode; # 共享锁锁住id=2的字段(第二步)
update blog set name = "xxx" where id = 4; # a端口锁住id=4的字段,加互斥锁直接卡住(第四步)
a事务锁住了b事务,b事务锁住了a事务,出现该现象就是是死锁现象。
出现死锁现象,mysql会强制关闭一个事务,另一个事务会直接执行成功。
并发有也可能会造成死锁现象(如下图所示)
高并发情况下产生的死锁现象

数据库锁机制总结
1.一旦事务1对数据A加了排它锁
那么其他事务无法对数据A加任何锁
只有事务1可以操作数据A,而且可以读也可以写
2.一旦事务1对数据A加了共享锁
那么其他事务可以对数据A加锁,但只能加共享锁
一旦多个事务都给数据A加了共享锁,大家都只能读不能改
(特例,如果只有一把共享锁,持有共享锁的事务可以读也可以写)
Innodb存储引擎
InnoDB三大特点:事务,外键,行级锁
在Mysql中,行级锁并不是直接锁记录,而是锁索引。InnoDB 行锁是通过给索引项加锁实现的,而索引分为主键索引和非主键索引两种。
1、如果一条sql 语句操作了主键索引,Mysql 就会锁定这条语句命中的主键索引(或称聚集索引);
2、如果一条语句操作了非主键索引(或称辅助索引),MySQL会先锁定该非主键索引,再锁定相关的主键索引。
3、如果没有索引,InnoDB 会通过隐藏的聚集索引来对记录加锁。也就是说:如果不通过索引条件检索数据,那么InnoDB将对表中所有数据加锁,实际效果跟表级锁一样。
Innodb有三种行锁的算法
记录锁 间隙锁 next-key
1、Record Lock:单个行记录上的锁。
2、Gap Lock:间隙锁,锁定一个范围,但不包括记录本身。GAP锁的目的,是为了防止同一事务的两次当前读,出现幻读的情况。
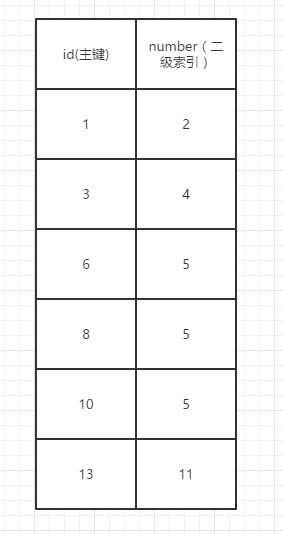
间隙锁
假设我们现在锁的是number=4,那么间隙锁锁的就是(2-4),(4-5)
假设我们现在锁的是number=13,那么间隙锁锁的就是(11之后的数字)
假设我们现在锁的是number=2,那么间隙锁锁的就是(2之前的数字),(2-4)
3、Next-Key Lock:等于Record Lock结合Gap Lock,也就说Next-Key Lock既锁定记录本身也锁定一个范围,特别需要注意的是,InnoDB存储引擎还会对辅助索引下一个键值加上gap lock
事务隔离机制四种级别(了解)
由低到高依次为Read uncommitted 、Read committed 、Repeatable read 、Serializable ,这四个级别可以逐个解决脏读 、不可重复读 、幻读 这几类问题。

需要强调的是:我们确实可以采用提高事务的隔离级别的方式来解决脏读、不可重复读、幻读等问题,但与此同时,事务的隔离级别越高,并发能力也就越低。Repeatable read是mysql默认的隔离机制,next-key行级锁可以解决幻读问题。
乐观锁与悲观锁
悲观锁与乐观锁相当于锁的使用方式
考虑到效率问题,现在主要是使用乐观锁
悲观锁
悲观锁相当于在使用sql语句执行命令的时候,会直接使用互斥锁。悲观锁的优点:保证数据安全;缺点:降低了数据库的使用效率
乐观锁
在数据库中,乐观锁的实现有两种方式
1、使用版本号实现
每一行数据多一个字段version,每次更新数据对应版本号+1,
原理:读出数据,将版本号一同读出,之后更新,版本号+1,提交数据版本号大于数据库当前版本号,则予以更新,否则认为是过期数据,重新读取数据
2、使用时间戳实现
每一行数据多一个字段time
原理:读出数据,将时间戳一同读出,之后更新,提交数据时间戳等于数据库当前时间戳,则予以更新,否则认为是过期数据,重新读取数据
在乐观锁与悲观锁的选择上面,主要看下两者的区别以及适用场景就可以了。
1、乐观锁并未真正加锁,效率高。一旦锁的粒度掌握不好,更新失败的概率就会比较高,容易发生业务失败。
2、悲观锁依赖数据库锁,效率低。更新失败的概率比较低。
mvcc机制
在MVCC并发控制中,读操作可以分成两类:快照读 (snapshot read)与当前读 (current read)。
快照读
读取的是记录的可见版本 (有可能是历史版本),不用加锁。
当前读
读取的是记录的最新版本,并且,当前读返回的记录,都会加上锁,保证其他事务不会再并发修改这条记录。