写在前面
本文涉及面较广,篇幅较长,阅读完需要耗费一定的时间与精力,如果你带有较为明确的阅读目的,可以参考以下建议完成阅读:
- 如果你对预编译的理论知识已经了解,可以直接从【原来它是这样的】的章节开始进行阅读,这会让你对预编译有一个更直观的了解。
- 如果你对 Search Path 的工作机制感兴趣,可以直接从【关于第一个问题】的章节阅读,这会让你更深刻,更全面的了解到它们的运作机制,
- 如果您对 Xcode Phases 里的 Header 的设置感到迷惑,可以直接从【揭开 Public、Private、Project 的真实面目】的章节开始阅读,这会让你理解为什么说 Private 并不是真正的私有头文件
- 如果你想了解如何通过 hmap 技术提升编译速度,可以从【基于 hmap 优化 Search Path 的策略】的章节开始阅读,这会给你提供一种新的编译加速思路。
- 如果你想了解如何通过 VFS 技术进行 Swift 产物的构建,可以从 【关于第二个问题】章节开始阅读,这会让你理解如何用另外一种提升构建 Swift 产物的效率。
- 如果你想了解 Swift 和 Objective-C 是如何找寻方法声明的,可以从 【Swift 来了】的章节阅读,这会让你从原理上理解混编的核心思路和解决方案。
概述
随着 Swift 的发展,国内技术社区出现了一些关于如何实现 Swift 与 Objective-C 混编的文章,这些文章的主要内容还是围绕着指导开发者进行各种操作来实现混编的效果,例如在 Build Setting 中开启某个选项,在 podspec 中增加某个字段,而鲜有文章对这些操作背后的工作机制做剖析,大部分核心概念也都是一笔带过。
正是因为这种现状,很多开发者在面对与预期不符的行为时,亦或者遇到各种奇怪的报错时,都会无从下手,而这也是由于对其工作原理不够了解所导致的。
笔者在美团平台负责 CI/CD 相关的工作,这其中也包含了 Objective-C 与 Swift 混编的内容,出于让更多开发者能够进一步理解混编工作机制的目的,撰写了这篇技术文章。
废话不多说,我们开始吧!
预编译知识指北
#import 的机制和缺点
在我们使用某些系统组件的时候,我们通常会写出如下形式的代码:
#import #import 其实是 #include 语法的微小创新,它们在本质上还是十分接近的。#include 做的事情其实就是简单的复制粘贴,将目标 .h 文件中的内容一字不落地拷贝到当前文件中,并替换掉这句 #include,而 #import 实质上做的事情和 #include 是一样的,只不过它还多了一个能够避免头文件重复引用的能力而已。
为了更好的理解后面的内容,我们这里需要展开说一下它到底是如何运行的?
从最直观的角度来看:
假设在 MyApp.m 文件中,我们 #import 了 iAd.h 文件,编译器解析此文件后,开始寻找 iAd 包含的内容(ADInterstitialAd.h,ADBannerView.h),及这些内容包含的子内容(UIKit.h,UIController.h,UIView.h,UIResponder.h),并依次递归下去,最后,你会发现 #import 这段代码变成了对不同 SDK 的头文件依赖。

如果你觉得听起来有点费劲,或者似懂非懂,我们这里可以举一个更加详细的例子,不过请记住,对于 C 语言的预处理器而言, #import 就是一种特殊的复制粘贴。
结合前面提到的内容,在 AppDelegate 中添加 iAd.h:
#import
@implementation AppDelegate
//...
@end 然后编译器会开始查找 iAd/iAd.h 到底是哪个文件且包含何种内容,假设它的内容如下:
/* iAd/iAd.h */
#import
#import
#import 在找到上面的内容后,编译器将其复制粘贴到 AppDelegate 中:
#import
#import
#import
@implementation AppDelegate
//...
@end 现在,编译器发现文件里有 3 个 #import 语句 了,那么就需要继续寻找这些文件及其相应的内容,假设 ADBannerView.h 的内容如下:
/* iAd/ADBannerView.h */
@interface ADBannerView : UIView
@property (nonatomic, readonly) ADAdType adType;
- (id)initWithAdType:(ADAdType)type
/* ... */
@end那么编译器会继续将其内容复制粘贴到 AppDelegate 中,最终变成如下的样子:
@interface ADBannerView : UIView
@property (nonatomic, readonly) ADAdType adType;
- (id)initWithAdType:(ADAdType)type
/* ... */
@end
#import
#import
@implementation AppDelegate
//...
@end 这样的操作会一直持续到整个文件中所有 #import 指向的内容被替换掉,这也意味着 .m 文件最终将变得极其的冗长。
虽然这种机制看起来是可行的,但它有两个比较明显的问题:健壮性和拓展性。
健壮性
首先这种编译模型会导致代码的健壮性变差!
这里我们继续采用之前的例子,在 AppDelegate 中定义 readonly 为 0x01,而且这个定义的声明在 #import 语句之前,那么此时又会发生什么事情呢?
编译器同样会进行刚才的那些复制粘贴操作,但可怕的是,你会发现那些在属性声明中的 readonly 也变成了 0x01,而这会触发编译器报错!
@interface ADBannerView : UIView
@property (nonatomic, 0x01) ADAdType adType;
- (id)initWithAdType:(ADAdType)type
/* ... */
@end
@implementation AppDelegate
//...
@end面对这种错误,你可能会说它是开发者自己的问题。
确实,通常我们都会在声明宏的时候带上固定的前缀来进行区分。但生活里总是有一些意外,不是么?
假设某个人没有遵守这种规则,那么在不同的引入顺序下,你可能会得到不同的结果,对于这种错误的排查,还是挺闹心的。不过,这还不是最闹心的,因为还有动态宏的存在,心塞 ing。
所以这种靠遵守约定来规避问题的解决方案,并不能从根本上解决问题,这也从侧面反应了编译模型的健壮性是相对较差的。
拓展性
说完了健壮性的问题,我们来看看拓展性的问题。
Apple 公司对它们的 Mail App 做过一个分析,下图是 Mail 这个项目里所有 .m 文件的排序,横轴是文件编号排序,纵轴是文件大小。

可以看到这些由业务代码构成的文件大小的分布区间很广泛,最小可能有几 kb,最大的能有 200+ kb,但总的来说,可能 90% 的代码都在 50kb 这个数量级之下,甚至更少。
如果我们往该项目的某个核心文件(核心文件是指其他文件可能都需要依赖的文件)里添加了一个对 iAd.h 文件的引用,对其他文件意味着什么呢?
这里的核心文件是指其他文件可能都需要依赖的文件
这意味着其他文件也会把 iAd.h 里包含的东西纳入进来,当然,好消息是,iAd 这个 SDK 自身只有 25KB 左右的大小。

但你得知道 iAd 还会依赖 UIKit 这样的组件,这可是个 400KB+ 的大家伙

所以,怎么说呢?
在 Mail App 里的所有代码都需要先涵盖这将近 425KB 的头文件内容,即使你的代码只有一行 Hello World。
如果你认为这已经让人很沮丧的话,那还有更打击你的消息,因为 UIKit 相比于 macOS 上的 Cocoa 系列大礼包,真的小太多了,Cocoa 系列大礼包可是 UIKit 的 29 倍......
所以如果将这个数据放到上面的图表中,你会发现真正的业务代码在 File Size 轴上的比重真的太微不足道了。
所以这就是拓展性差带来的问题之一!
很明显,我们不可能用这样的方式引入代码,假设你有 M 个源文件且每个文件会引入 N 个头文件,按照刚才的解释,编译它们的时间就会是 M * N,这是非常可怕的!
备注:文章里提到的 iAd 组件为 25KB,UIKit 组件约为 400KB, macOS 的 Cocoa 组件是 UIKit 的 29 倍等数据,是 WWDC 2013 Session 404 Advances in Objective-C 里公布的数据,随着功能的不断迭代,以现在的眼光来看,这些数据可能已经偏小,在 WWDC 2018 Session 415 Behind the Scenes of the Xcode Build Process 中提到了 Foundation 组件,它包含的头文件数量大于 800 个,大小已经超过 9MB。
PCH(PreCompiled Header)是一把双刃剑
为了优化前面提到的问题,一种折中的技术方案诞生了,它就是 PreCompiled Header。
我们经常可以看到某些组件的头文件会频繁的出现,例如 UIKit,而这很容易让人联想到一个优化点,我们是不是可以通过某种手段,避免重复编译相同的内容呢?
而这就是 PCH 为预编译流程带来的改进点!
它的大体原理就是,在我们编译任意 .m 文件前, 编译器会先对 PCH 里的内容进行预编译,将其变为一种二进制的中间格式缓存起来,便于后续的使用。当开始编译 .m 文件时,如果需要 PCH 里已经编译过的内容,直接读取即可,无须再次编译。
虽然这种技术有一定的优势,但实际应用起来,还存在不少的问题。
首先,它的维护是有一定的成本的,对于大部分历史包袱沉重的组件来说,将项目中的引用关系梳理清楚就十分麻烦,而要在此基础上梳理出合理的 PCH 内容就更加麻烦,同时随着版本的不断迭代,哪些头文件需要移出 PCH,哪些头文件需要移进 PCH 将会变得越来越麻烦。
其次,PCH 会引发命名空间被污染的问题,因为 PCH 引入的头文件会出现在你代码中的每一处,而这可能会是多于的操作,比如 iAd 应当出现在一些与广告相关的代码中,它完全没必要出现在帮助相关的代码中(也就是与广告无关的逻辑),可是当你把它放到 PCH 中,就意味组件里的所有地方都会引入 iAd 的代码,包括帮助页面,这可能并不是我们想要的结果!
如果你想更深入的了解 PCH 的黑暗面,建议阅读 4 Ways Precompiled Headers Cripple Your Code ,里面已经说得相当全面和透彻。
所以 PCH 并不是一个完美的解决方案,它能在某些场景下提升编译速度,但也有缺陷!
Clang Module 的来临!
为了解决前面提到的问题,Clang 提出了 Module 的概念,关于它的介绍可以在 Clang 官网 上找到。
简单来说,你可以把它理解为一种对组件的描述,包含了对接口(API)和实现(dylib/a)的描述,同时 Module 的产物是被独立编译出来的,不同的 Module 之间是不会影响的。
在实际编译之时,编译器会创建一个全新的空间,用它来存放已经编译过的 Module 产物。如果在编译的文件中引用到某个 Module 的话,系统将优先在这个列表内查找是否存在对应的中间产物,如果能找到,则说明该文件已经被编译过,则直接使用该中间产物,如果没找到,则把引用到的头文件进行编译,并将产物添加到相应的空间中以备重复使用。
在这种编译模型下,被引用到的 Module 只会被编译一次,且在运行过程中不会相互影响,这从根本上解决了健壮性和拓展性的问题。
Module 的使用并不麻烦,同样是引用 iAd 这个组件,你只需要这样写即可。
@import iAd;在使用层面上,这将等价于以前的 #import 语句,但是会使用 Clang Module 的特性加载整个 iAd 组件。如果只想引入特定文件(比如 ADBannerView.h),原先的写法是 #import ,现在可以写成:
@import iAd.ADBannerView;通过这种写法会将 iAd 这个组件的 API 导入到我们的应用中,同时这种写法也更符合语义化(semanitc import)。
虽然这种引入方式和之前的写法区别不大,但它们在本质上还是有很大程度的不同,Module 不会“复制粘贴”头文件里的内容,也不会让 @import 所暴露的 API 被开发者本地的上下文篡改,例如前面提到的 #define readonly 0x01。
此时,如果你觉得前面关于 Clang Module 的描述还是太抽象,我们可以再进一步去探究它工作原理, 而这就会引入一个新的概念—— modulemap。
不论怎样,Module 只是一个对组件的抽象描述罢了,而 modulemap 则是这个描述的具体呈现,它对框架内的所有文件进行了结构化的描述,下面是 UIKit 的 modulemap 文件。
framework module UIKit {
umbrella header "UIKit.h"
module * {export *}
link framework "UIKit"
}这个 Module 定义了组件的 Umbrella Header 文件(UIKit.h),需要导出的子 Module(所有),以及需要 Link 的框架名称(UIKit),正是通过这个文件,让编译器了解到 Module 的逻辑结构与头文件结构的关联方式。
可能又有人会好奇,为什么我从来没看到过 @import 的写法呢?
这是因为 Xcode 的编译器能够将符合某种格式的 #import 语句自动转换成 Module 识别的 @import 语句,从而避免了开发者的手动修改。

唯一需要开发者完成的就是开启相关的编译选项。

对于上面的编译选项,需要开发者注意的是:
Apple Clang - Language - Modules 里 Enable Module 选项是指引用系统库的的时候,是否采用 Module 的形式。
而 Packaging 里的 Defines Module 是指开发者编写的组件是否采用 Module 的形式。
说了这么多,我想你应该对 #import, pch, @import 有了一定的概念。当然,如果我们深究下去,可能还会有如下的疑问:
- 对于未开启 Clang Module 特性的组件,Clang 是通过怎样的机制查找到头文件的呢?在查找系统头文件和非系统头文件的过程中,有什么区别么?
- 对于已开启 Clang Module 特性的组件,Clang 是如何决定编译当下组件的 Module 呢?另外构建的细节又是怎样的,以及如何查找这些 Module 的?还有查找系统的 Module 和非系统的 Module 有什么区别么?
为了解答这些问题,我们不妨先动手实践一下,看看上面的理论知识在现实中的样子。
原来它是这样的
在前面的章节中,我们将重点放在了原理上的介绍,而在这个章节中,我们将动手看看这些预编译环节的实际样子。
#import 的样子
假设我们的源码样式如下:
#import "SQViewController.h"
#import
@interface SQViewController ()
@end
@implementation SQViewController
- (void)viewDidLoad {
[super viewDidLoad];
ClassA *a = [ClassA new];
NSLog(@"%@", a);
}
- (void)didReceiveMemoryWarning {
[super didReceiveMemoryWarning];
}
@end 想要查看代码预编译后的样子,我们可以在 Navigate to Related Items 按钮中找到 Preprocess 选项

既然知道了如何查看预编译后的样子,我们不妨看看代码在使用 #import, PCH 和 @import 后,到底会变成什么样子?
这里我们假设被引入的头文件,即 ClassA 中的内如下:
@interface ClassA : NSObject
@property (nonatomic, strong) NSString *name;
- (void)sayHello;
@end通过 preprocess 可以看到代码大致如下,这里为了方便展示,将无用代码进行了删除。这里记得要将 Build Setting 中 Packaging 的 Define Module 设置为 NO,因为其默认值为 YES,而这会导致我们开启 Clang Module 特性。
@import UIKit;
@interface SQViewController : UIViewController
@end
@interface ClassA : NSObject
@property (nonatomic, strong) NSString *name;
- (void)sayHello;
@end
@interface SQViewController ()
@end
@implementation SQViewController
- (void)viewDidLoad {
[super viewDidLoad];
ClassA *a = [ClassA new];
NSLog(@"%@", a);
}
- (void)didReceiveMemoryWarning {
[super didReceiveMemoryWarning];
}
@end这么一看,#import 的作用还就真的是个 Copy & Write。
PCH 的真容
对于 CocoaPods 默认创建的组件,一般都会关闭 PCH 的相关功能,例如笔者创建的 SQPod 组件,它的 Precompile Prefix Header 功能默认值为 NO。

为了查看预编译的效果,我们将 Precompile Prefix Header 的值改为 YES,并编译整个项目,通过查看 Build Log,我们可以发现相比于 NO 的状态,在编译的过程中,增加了一个步骤,即 Precompile SQPod-Prefix.pch 的步骤。

通过查看这个命令的 -o 参数,我们可以知道其产物是名为 SQPod-Prefix.pch.gch 的文件。

这个文件就是 PCH 预编译后的产物,同时在编译真正的代码时,会通过 -include 参数将其引入。

又见 Clang Module
在开启 Define Module 后,系统会为我们自动创建相应的 modulemap 文件,这一点可以在 Build Log 中查找到。

它的内容如下:
framework module SQPod {
umbrella header "SQPod-umbrella.h"
export *
module * { export * }
}当然,如果系统自动生成的 modulemap 并不能满足你的诉求,我们也可以使用自己创建的文件,此时只需要在 Build Setting 的 Module Map File 选项中填写好文件路径,相应的 clang 命令参数是 -fmodule-map-file。

最后让我们看看 Module 编译后的产物形态。
这里我们构建一个名为 SQPod 的 Module ,将它提供给名为 Example 的工程使用,通过查看 -fmodule-cache-path 的参数,我们可以找到 Module 的缓存路径。

进入对应的路径后,我们可以看到如下的文件:

其中后缀名为 pcm 的文件就是构建出来的二进制中间产物。
现在,我们不仅知道了预编译的基础理论知识,也动手查看了预编译环节在真实环境下的产物,现在我们要开始解答之前提到的两个问题了!
打破砂锅问到底
关于第一个问题
对于未开启 Clang Module 特性的组件,Clang 是通过怎样的机制查找到头文件的呢?在查找系统头文件和非系统头文件的过程中,有什么区别么?
在早期的 Clang 编译过程中,头文件的查找机制还是基于 Header Seach Path 的,这也是大多数人所熟知的工作机制,所以我们不做赘述,只做一个简单的回顾。
Header Search Path 是构建系统提供给编译器的一个重要参数,它的作用是在编译代码的时候,为编译器提供了查找相应头文件路径的信息,通过查阅 Xcode 的 Build System 信息,我们可以知道相关的设置有三处 Header Search Path、System Header Search Path、User Header Search Path。

它们的区别也很简单,System Header Search Path 是针对系统头文件的设置,通常代指 <> 方式引入的文件,uUser Header Search Path 则是针对非系统头文件的设置,通常代指 "" 方式引入的文件,而 Header Search Path 并不会有任何限制,它普适于任何方式的头文件引用。
听起来好像很复杂,但关于引入的方式,无非是以下四种形式:
#import
#import "A/A.h"
#import
#import "A.h" 我们可以两个维度去理解这个问题,一个是引入的符号形式,另一个是引入的内容形式。
- 引入的符号形式:通常来说,双引号的引入方式(
“A.h”或者"A/A.h")是用于查找本地的头文件,需要指定相对路径,尖括号的引入方式()是全局的引用,其路径由编译器提供,如引用系统的库,但随着 Header Search Path 的加入,让这种区别已经被淡化了。 - 引入的内容形式:对于
X/X.h和X.h这两种引入的内容形式,前者是说在对应的 Search Path 中,找到目录 A 并在 A 目录下查找A.h,而后者是说在 Search Path 下查找A.h文件,而不一定局限在 A 目录中,至于是否递归的寻找则取决于对目录的选项是否开启了recursive模式

在很多工程中,尤其是基于 CocoaPods 开发的项目,我们已经不会区分 System Header Search Path 和 User Header Search Path,而是一股脑的将所有头文件路径添加到 Header Search Path 中,这就导致我们在引用某个头文件时,不会再局限于前面提到的约定,甚至在某些情况下,前面提到的四种方式都可以做到引入某个指定头文件。
Header Maps
随着项目的迭代和发展,原有的头文件索引机制还是受到了一些挑战,为此,Clang 官方也提出了自己的解决方案。
为了理解这个东西,我们首先要在 Build Setting 中开启 Use Header Map 选项。
![]()
然后在 Build Log 里获取相应组件里对应文件的编译命令,并在最后加上 -v 参数,来查看其运行的秘密:
$ clang -c SQViewController.m -o SQViewcontroller.o -v
在 console 的输出内容中,我们会发现一段有意思的内容:

通过上面的图,我们可以看到编译器将寻找头文件的顺序和对应路径展示出来了,而在这些路径中,我们看到了一些陌生的东西,即后缀名为 .hmap 的文件。
那 hmap 到底这是个什么东西呢?
当我们开启 Build Setting 中的 Use Header Map 选项后,会自动生成的一份头文件名和头文件路径的映射表,而这个映射表就是 hmap 文件,不过它是一种二进制格式的文件,也有人叫它为 Header Map。总之,它的核心功能就是让编译器能够找到相应头文件的位置。
为了更好的理解它,我们可以通过 milend 编写的小工具 hmap 来查其内容。
在执行相关命令(即 hmap print)后,我们可以发现这些 hmap 里保存的信息结构大致如下:

需要注意,映射表的键值并不是简单的文件名和绝对路径,它的内容会随着使用场景产生不同的变化,例如头文件引用是在 "..." 的形式,还是 <...> 的形式,又或是在 Build Phase 里 Header 的配置情况。

至此,我想你应该明白了,一旦开启 Use Header Map 选项后,Xcode 会优先去 hmap 映射表里寻找头文件的路径,只有在找不到的情况下,才会去 Header Search Path 中提供的路径遍历搜索。
当然这种技术也不是一个什么新鲜事儿,在 Facebook 的 buck 工具中也提供了类似的东西,只不过文件类型变成了 HeaderMap.java 的样子。
查找系统库的头文件
上面的过程让我们理解了在 Header Map 技术下,编译器是如何寻找相应的头文件的,那针对系统库的文件又是如何索引的呢?例如 #import
回想一下上一节 console 的输出内容,它的形式大概如下:
#include "..." search starts here:
XXX-generated-files.hmap (headermap)
XXX-project-headers.hmap (headermap)
#include <...> search starts here:
XXX-own-target-headers.hmap (headermap)
XXX-all-target-headers.hmap (headermap)
Header Search Path
DerivedSources
Build/Products/Debug (framework directory)
$(SDKROOT)/usr/include
$(SDKROOT)/System/Library/Frameworks(framework directory)我们会发现,这些路径大部分是用于查找非系统库文件的,也就是开发者自己引入的头文件,而与系统库相关的路径只有以下两个:
#include <...> search starts here:
$(SDKROOT)/usr/include
$(SDKROOT)/System/Library/Frameworks.(framework directory)当我们查找 Foundation/Foundation.h 这个文件的时候,我们会首先判断是否存在 Foundation 这个 Framework。
$SDKROOT/System/Library/Frameworks/Foundation.framework接着,我们会进入 Framework 的 Headers 文件夹里寻找对应的头文件。
$SDKROOT/System/Library/Frameworks/Foundation.framework/Headers/Foundation.h如果没有找到对应的文件,索引过程会在此中断,并结束查找。
以上便是系统库的头文件搜索逻辑。
Framework Search Path
到现在为止,我们已经解释了如何依赖 Header Search Path、hmap 等技术寻找头文件的工作机制,也介绍了寻找系统库(System Framework)头文件的工作机制。
那这是全部头文件的搜索机制么?答案是否定的,其实我们还有一种头文件搜索机制,它是基于 Framework 这种文件结构进行的。

对于开发者自己的 Framework,可能会存在 "private" 头文件,例如在 podspec 里用 private_header_files 的描述文件,这些文件在构建的时候,会被放在 Framework 文件结构中的 PrivateHeaders 目录。
所以针对有 PrivateHeaders 目录的 Framework 而言,Clang 在检查 Headers 目录后,会去 PrivateHeaders 目录中寻找是否存在匹配的头文件,如果这两个目录都没有,才会结束查找。
$SDKROOT/System/Library/Frameworks/Foundation.framework/PrivateHeaders/SecretClass.h不过也正是因为这个工作机制,会产生一个特别有意思的问题,那就是当我们使用 Framework 的方式引入某个带有 "Private" 头文件的组件时,我们总是可以以下面的方式引入这个头文件!

怎么样,是不是很神奇,这个被描述为 "Private" 的头文件怎么就不私有了?
究其原因,还是由于 Clang 的工作机制,那为什么 Clang 要设计出来这种看似很奇怪的工作机制呢?
揭开 Public、Private、Project 的真实面目
其实你也看到,我在上一段的写作中,将所有 Private 单词标上了双引号,其实就是在暗示,我们曲解了 Private 的含义。
那么这个 "Private" 到底是什么意思呢?
在 Apple 官方的 Xcode Help - What are build phases? 文档中,我们可以看到如下的一段解释:
Associates public, private, or project header files with the target. Public and private headers define API intended for use by other clients, and are copied into a product for installation. For example, public and private headers in a framework target are copied into Headers and PrivateHeaders subfolders within a product. Project headers define API used and built by a target, but not copied into a product. This phase can be used once per target.
总的来说,我们可以知道一点,就是 Build Phases - Headers 中提到 Public 和 Private 是指可以供外界使用的头文件,且分别放在最终产物的 Headers 和 PrivateHeaders 目录中,而 Project 中的头文件是不对外使用的,也不会放在最终的产物中。
如果你继续翻阅一些资料,例如 StackOverflow - Xcode: Copy Headers: Public vs. Private vs. Project? 和 StackOverflow - Understanding Xcode's Copy Headers phase,你会发现在早期 Xcode Help 的 Project Editor 章节里,有一段名为 Setting the Role of a Header File 的段落,里面详细记载了三个类型的区别。
Public: The interface is finalized and meant to be used by your product’s clients. A public header is included in the product as readable source code without restriction.
Private: The interface isn’t intended for your clients or it’s in early stages of development. A private header is included in the product, but it’s marked “private”. Thus the symbols are visible to all clients, but clients should understand that they're not supposed to use them.
Project: The interface is for use only by implementation files in the current project. A project header is not included in the target, except in object code. The symbols are not visible to clients at all, only to you.
至此,我们应该彻底了解了 Public、Private、Project 的区别。简而言之,Public 还是通常意义上的 Public,Private 则代表 In Progress 的含义,至于 Project 才是通常意义上的 Private 含义。
那么 CocoaPods 中 Podspec 的 Syntax 里还有 public_header_files 和 private_header_files 两个字段,它们的真实含义是否和 Xcode 里的概念冲突呢?
这里我们仔细阅读一下官方文档的解释,尤其是 private_header_files 字段。
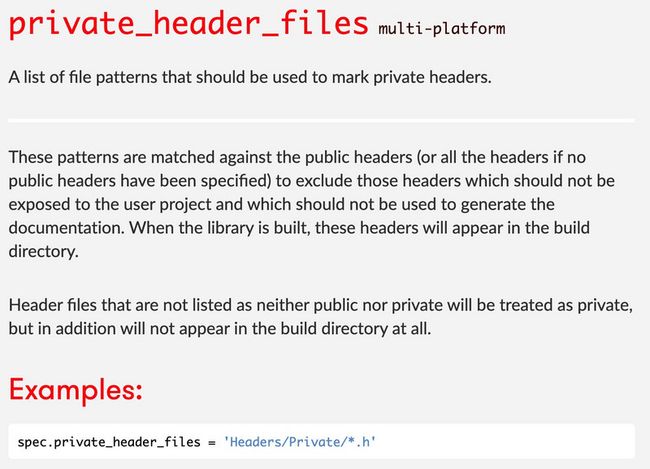
我们可以看到,private_header_files 在这里的含义是说,它本身是相对于 Public 而言的,这些头文件本义是不希望暴露给用户使用的,而且也不会产生相关文档,但是在构建的时候,会出现在最终产物中,只有既没有被 Public 和 Private 标注的头文件,才会被认为是真正的私有头文件,且不出现在最终的产物里。
其实这么看来,CocoaPods 对于 Public 和 Private 的理解是和 Xcode 中的描述一致的,两处的 Private 并非我们通常理解的 Private,它的本意更应该是开发者准备对外开放,但又没完全 Ready 的头文件,更像一个 In Progress 的含义。
所以,如果你真的不想对外暴露某些头文件,请不要再使用 Headers 里的 Private 或者 podspec 里的 private_header_files 了。
至此,我想你应该彻底理解了 Search Path 的搜索机制和略显奇怪的 Public、Private、Project 设定了!
基于 hmap 优化 Search Path 的策略
在查找系统库的头文件的章节中,我们通过 -v 参数看到了寻找头文件的搜索顺序:
#include "..." search starts here:
XXX-generated-files.hmap (headermap)
XXX-project-headers.hmap (headermap)
#include <...> search starts here:
XXX-own-target-headers.hmap (headermap)
XXX-all-target-headers.hmap (headermap)
Header Search Path
DerivedSources
Build/Products/Debug (framework directory)
$(SDKROOT)/usr/include
$(SDKROOT)/System/Library/Frameworks(framework directory)假设,我们没有开启 hmap 的话,所有的搜索都会依赖 Header Search Path 或者 Framework Search Path,那这就会出现 3 种问题:
- 第一个问题,在一些巨型项目中,假设依赖的组件有 400+,那此时的索引路径就会达到 800+ 个(一份 Public 路径,一份 Private 路径),同时搜索操作可以看做是一种 IO 操作,而我们知道 IO 操作通常也是一种耗时操作,那么,这种大量的耗时操作必然会导致编译耗时增加。
- 第二个问题,在打包的过程中,如果 Header Search Path 过多过长,会触发命令行过长的错误,进而导致命令执行失败的情况。
- 第三个问题,在引入系统库的头文件时,Clang 会将前面提到的目录遍历完才进入搜索系统库的路径,也就是
$(SDKROOT)/System/Library/Frameworks(framework directory),即前面的 Header Search 路径越多,耗时也会越长,这是相当不划算的。
那如果我们开启 hmap 后,是否就能解决掉所有的问题呢?
实际上并不能,而且在基于 CocoaPods 管理项目的状况下,又会带来新的问题。下面是一个基于 CocoaPods 构建的全源码工程项目,它的整体结构如下:
首先,Host 和 Pod 是我们的两个 Project,Pods 下的 Target 的产物类型为 Static Library。
其次,Host 底下会有一个同名的 Target,而 Pods 目录下会有 n+1 个 Target,其中 n 取决于你依赖的组件数量,而 1 是一个名为 Pods-XXX 的 Target,最后,Pods-XXX 这个 Target 的产物会被 Host 里的 Target 所依赖。
整个结构看起来如下所示:

此时我们将 PodA 里的文件全部放在 Header 的 Project 类型中。

在基于 Framework 的搜索机制下,我们是无法以任何方式引入到 ClassB 的,因为它既不在 Headers 目录,也不在 PrivateHeader 目录中。
可是如果我们开启了 Use Header Map 后,由于 PodA 和 PodB 都在 Pods 这个 Project 下,满足了 Header 的 Project 定义,通过 Xcode 自动生成的 hmap 文件会带上这个路径,所以我们还可以在 PodB 中以 #import "ClassB.h" 的方式引入。
而这种行为,我想应该是大多数人并不想要的结果,所以一旦开启了 Use Header Map,再结合 CocoaPods 管理工程项目的模式,我们极有可能会产生一些误用私有头文件的情况,而这个问题的本质是 Xcode 和 CocoaPods 在工程和头文件上的理念冲突造成的。
除此之外,CocoaPods 在处理头文件的问题上还有一些让人迷惑的地方,它在创建头文件产物这块的逻辑大致如下:
在构建产物为 Framework 的情况下
- 根据 podspec 里的
public_header_files字段的内容,将相应头文件设置为 Public 类型,并放在 Headers 中。 - 根据 podspec 里的
private_header_files字段的内容,将相应文件设置为 Private 类型,并放在 PrivateHeader 中。 - 将其余未描述的头文件设置为 Project 类型,且不放入最终的产物中。
- 如果 podspec 里未标注 Public 和 Private 的时候,会将所有文件设置为 Public 类型,并放在 Header 中。
- 根据 podspec 里的
在构建产物为 Static Library 的情况下
- 不论 podspec 里如何设置
public_header_files和private_header_files,相应的头文件都会被设置为 Project 类型。 - 在
Pods/Headers/Public中会保存所有被声明为public_header_files的头文件。 - 在
Pods/Headers/Private中会保存所有头文件,不论是public_header_files或者private_header_files描述到,还是那些未被描述的,这个目录下是当前组件的所有头文件全集。 - 如果 podspec 里未标注 Public 和 Private 的时候,
Pods/Headers/Public和Pods/Headers/Private的内容一样且会包含所有头文件。
- 不论 podspec 里如何设置
正是由于这种机制,还导致了另外一种有意思的问题。
在 Static Library 的状况下,一旦我们开启了 Use Header Map,结合组件里所有头文件的类型为 Project 的情况,这个 hmap 里只会包含 #import "A.h" 的键值引用,也就是说只有 #import "A.h" 的方式才会命中 hmap 的策略,否则都将通过 Header Search Path 寻找其相关路径。
而我们也知道,在引用其他组件的时候,通常都会采用 #import 的方式引入。至于为什么会用这种方式,一方面是这种写法会明确头文件的由来,避免问题,另一方面也是这种方式可以让我们在是否开启 Clang Module 中随意切换,当然还有一点就是,Apple 在 WWDC 里曾经不止一次建议开发者使用这种方式来引入头文件。
接着上面的话题来说,所以说在 Static Library 的情况下且以 #import 这种标准方式引入头文件时,开启 Use Header Map 并不会提升编译速度,而这同样是 Xcode 和 CocoaPods 在工程和头文件上的理念冲突造成的。

这样来看的话,虽然 hmap 有种种优势,但是在 CocoaPods 的世界里显得格格不入,也无法发挥自身的优势。
那这就真的没有办法解决了么?
当然,问题是有办法解决的,我们完全可以自己动手做一个基于 CocoaPods 规则下的 hmap 文件。
举一个简单的例子,通过遍历 PODS 目录里的内容去构建索引表内容,借助 hmap 工具生成 header map 文件,然后将 Cocoapods 在 Header Search Path 中生成的路径删除,只添加一条指向我们自己生成的 hmap 文件路径,最后关闭 Xcode 的 Ues Header Map 功能,也就是 Xcode 自动生成 hmap 的功能,如此这般,我们就实现了一个简单的,基于 CocoaPods 的 Header Map 功能。
同时在这个基础上,我们还可以借助这个功能实现不少管控手段,例如:
- 从根本上杜绝私有文件被暴露的可能性。
- 统一头文件的引用形式
- ...
目前,我们已经自研了一套基于上述原理的 cocoapods 插件,它的名字叫做 cocoapods-hmap-prebuilt,是由笔者与同事共同开发的。
说了这么多,让我们看看它在实际工程中的使用效果!
经过全源码编译的测试,我们可以看到该技术在提速上的收益较为明显,以美团和点评 App 为例,全链路时长能够提升 45% 以上,其中 Xcode 打包时间能提升 50%。
关于第二个问题
对于已开启 Clang Module 特性的组件,Clang 是如何决定编译当下组件的 Module 呢?另外构建的细节又是怎样的,以及如何查找这些 Module 的?还有查找系统的 Module 和非系统的 Module 有什么区别么?
首先,我们来明确一个问题, Clang 是如何决定编译当下组件的 Module 呢?
以 #import 为例,当我们遇到这个头文件的时候:
首先会去 Framework 的 Headers 目录下寻找相应的头文件是否存在,然后就会到 Modules 目录下查找 modulemap 文件。

此时,Clang 会去查阅 modulemap 里的内容,看看 NSString 是否为 Foundation 这个 Module 里的一部分。
// Module Map - Foundation.framework/Modules/module.modulemap
framework module Foundation [extern_c] [system] {
umbrella header "Foundation.h"
export *
module * {
export *
}
explicit module NSDebug {
header "NSDebug.h"
export *
}
}很显然,这里通过 Umbrella Header,我们是可以在 Foundation.h 中找到 NSString.h 的。
// Foundation.h
…
#import
#import
#import
… 至此,Clang 会判定 NSString.h 是 Foundation 这个 Module 的一部分并进行相应的编译工作,此时也就意味着 #import 会从之前的 textual import 变为 module import。
Module 的构建细节
上面的内容解决了是否构建 Module,而这一块我们会详细阐述构建 Module 的过程!
在构建开始前,Clang 会创建一个完全独立的空间来构建 Module,在这个空间里会包含 Module 涉及的所有文件,除此之外不会带入其他任何文件的信息,而这也是 Module 健壮性好的关键因素之一。
不过,这并不意味着我们无法影响到 Module 的唯一性,真正能影响到其唯一性的是其构建的参数,也就是 Clang 命令后面的内容,关于这一点后面还会继续展开,这里我们先点到为止。
当我们在构建 Foundation 的时候,我们会发现 Foundation 自身要依赖一些组件,这意味着我们也需要构建被依赖组件的 Module。

但很明显的是,我们会发现这些被依赖组件也有自己的依赖关系,在它们的这些依赖关系中,极有可能会存在重复的引用。

此时,Module 的复用机制就体现出来优势了,我们可以复用先前构建出来的 Module,而不必一次次的创建或者引用,例如 Drawin 组件,而保存这些缓存文件的位置就是前面章节里提到的保存 pcm 类型文件的地方。
先前我们提到了 Clang 命令的参数会真正影响到 Module 的唯一性,那具体的原理又是怎样的?
Clang 会将相应的编译参数进行一次 Hash,将获得的 Hash 值作为 Module 缓存文件夹的名称,这里需要注意的是,不同的参数和值会导致文件夹不同,所以想要尽可能的利用 Module 缓存,就必须保证参数不发生变化。
$ clang -fmodules —DENABLE_FEATURE=1 …
## 生成的目录如下
98XN8P5QH5OQ/
CoreFoundation-2A5I5R2968COJ.pcm
Security-1A229VWPAK67R.pcm
Foundation-1RDF848B47PF4.pcm
$ clang -fmodules —DENABLE_FEATURE=2 …
## 生成的目录如下
1GYDULU5XJRF/
CoreFoundation-2A5I5R2968COJ.pcm
Security-1A229VWPAK67R.pcm
Foundation-1RDF848B47PF4.pcm这里我们大概了解了系统组件的 module 构建机制,这也是开启 Enable Modules(C and Objective-C) 的核心工作原理。
神秘的 Virtual File System(VFS)
对于系统组件,我们可以在 /Applications/Xcode.app/Contents/Developer/Platforms/iPhoneSimulator.platform/Developer/SDKs/iPhoneSimulator14.2.sdk/System/Library/Frameworks 目录里找到它的身影,它的目录结构大概是这样的:
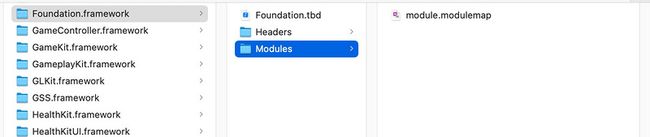
也就是说,对于系统组件而言,构建 Module 的整个过程是建立在这样一个完备的文件结构上,即在 Framework 的 Modules 目录中查找 modulemap,在 Headers 目录中加载头文件。
那对于用户自己创建的组件,Clang 又是如何构建 Module 的呢?
通常我们的开发目录大概是下面的样子,它并没有 Modules 目录,也没有 Headers 目录,更没有 modulemap 文件,看起来和 Framework 的文件结构也有着极大的区别。

在这种情况下,Clang 是没法按照前面所说的机制去构建 Module 的,因为在这种文件结构中,压根就没有 Modules 和 Headers 目录。
为了解决这个问题,Clang 又提出了一个新的解决方案,叫做 Virtual File System(VFS)。
简单来说,通过这个技术,Clang 可以在现有的文件结构上虚拟出来一个 Framework 文件结构,进而让 Clang 遵守前面提到的构建准则,顺利完成 Module 的编译,同时 VFS 也会记录文件的真实位置,以便在出现问题的时候,将文件的真实信息暴露给用户。
为了进一步了解 VFS,我们还是从 Build Log 中查找一些细节!

在上面的编译参数里,我们可以找到一个 -ivfsoverlay 的参数,查看 Help 说明,可以知道其作用就是向编译器传递一个 VFS 描述文件并覆盖掉真实的文件结构信息。
-ivfsoverlay Overlay the virtual filesystem described by file over the real file system 顺着这个线索,我们去看看这个参数指向的文件,它是一个 yaml 格式的文件,在将内容进行了一些裁剪后,它的核心内容如下:
{
"case-sensitive": "false",
"version": 0,
"roots": [
{
"name": "XXX/Debug-iphonesimulator/PodA/PodA.framework/Headers",
"type": "directory",
"contents": [
{ "name": "ClassA.h", "type": "file",
"external-contents": "XXX/PodA/PodA/Classes/ClassA.h"
},
......
{ "name": "PodA-umbrella.h", "type": "file",
"external-contents": "XXX/Target Support Files/PodA/PodA-umbrella.h"
}
]
},
{
"contents": [
"name": "XXX/Products/Debug-iphonesimulator/PodA/PodA.framework/Modules",
"type": "directory"
{ "name": "module.modulemap", "type": "file",
"external-contents": "XXX/Debug-iphonesimulator/PodA.build/module.modulemap"
}
]
}
]
}结合前面提到的内容,我们不难看出它在描述这样一个文件结构:
借用一个真实存在的文件夹来模拟 Framework 里的 Headers 文件夹,在这个 Headers 文件夹里有名为 PodA-umbrella.h 和 ClassA.h 等的文件,不过这几个虚拟文件与 external-contents 指向的真实文件相关联,同理还有 Modules 文件夹和它里面的 module.modulemap 文件。
通过这样的形式,一个虚拟的 Framework 目录结构诞生了!此时 Clang 终于能按照前面的构建机制为用户创建 Module 了!
Swift 来了
没有头文件的 Swift
前面的章节,我们聊了很多 C 语言系的预编译知识,在这个体系下,文件的编译是分开的,当我们想引用其他文件里的内容时,就必须引入相应的头文件。

而对于 Swift 这门语言来说,它并没有头文件的概念,对于开发者而言,这确实省去了写头文件的重复工作,但这也意味着,编译器会进行额外的操作来查找接口定义并需要持续关注接口的变化!
为了更好的解释 Swift 和 Objective-C 是如何寻找到彼此的方法声明的,我们这里引入一个例子,在这个例子由三个部分组成:
- 第一部分是一个 ViewController 的代码,它里面包含了一个 View,其中 PetViewController 和 PetView 都是 Swift 代码。
- 第二部分是一个 App 的代理,它是 Objective-C 代码。
- 第三个部分是一段单测代码,用来测试第一个部分中的 ViewController,它是 Swift 代码。
import UIKit
class PetViewController: UIViewController {
var view = PetView(name: "Fido", frame: frame)
…
}#import "PetWall-Swift.h"
@implementation AppDelegate
…
@end@testable import PetWall
class TestPetViewController: XCTestCase {
}它们的关系大致如下所示:

为了能让这些代码编译成功,编译器会面对如下 4 个场景:
首先是寻找声明,这包括寻找当前 Target 内的方法声明(PetView),也包括来自 Objective-C 组件里的声明(UIViewController 或者 PetKit)。
然后是生成接口,这包括被 Objective-C 使用的接口,也包括被其他 Target (Unit Test)使用的 Swift 接口。
第一步 - 如何寻找 Target 内部的 Swift 方法声明
在编译 PetViewController.swift 时,编译器需要知道 PetView 的初始化构造器的类型,才能检查调用是否正确。
此时,编译器会加载 PetView.swift 文件并解析其中的内容, 这么做的目的就是确保初始化构造器真的存在,并拿到相关的类型信息,以便 PetViewController.swift 进行验证。

编译器并不会对初始化构造器的内部做检查,但它仍然会进行一些额外的操作,这是什么意思呢?
与 Clang 编译器不同的是,Swiftc 编译的时候,会将相同 Target 里的其他 Swift 文件进行一次解析,用来检查其中与被编译文件关联的接口部分是否符合预期。
同时我们也知道,每个文件的编译是独立的,且不同文件的编译是可以并行开展的,所以这就意味着每编译一个文件,就需要将当前 Target 里的其余文件当做接口,重新编译一次。等于任意一个文件,在整个编译过程中,只有 1 次被作为生产 .o 产物的输入,其余时间会被作为接口文件反复解析。

不过在 Xcode 10 以后,Apple 对这种编译流程进行了优化。
在尽可能保证并行的同时,将文件进行了分组编译,这样就避免了 Group 内的文件重复解析,只有不同 Group 之间的文件会有重复解析文件的情况。

而这个分组操作的逻辑,就是刚才提到的一些额外操作。
至此,我们应该了解了 Target 内部是如何寻找 Swift 方法声明的了。
第二步 - 如何找到 Objective-C 组件里的方法声明
回到第一段代码中,我们可以看到 PetViewController 是继承自 UIViewController,而这也意味着我们的代码会与 Objective-C 代码进行交互,因为大部分系统库,例如 UIKit 等,还是使用 Objective-C 编写的。
在这个问题上,Swift 采用了和其他语言不一样的方案!
通常来说,两种不同的语言在混编时需要提供一个接口映射表,例如 JavaScript 和 TypeScript 混编时候的 .d.ts 文件,这样 TypeScript 就能够知道 JavaScript 方法在 TS 世界中的样子。
然而,Swift 不需要提供这样的接口映射表, 免去了开发者为每个 Objective-C API 声明其在 Swift 世界里样子,那它是怎么做到的呢?
很简单,Swift 编译器将 Clang 的大部分功能包含在其自身的代码中,这就使得我们能够以 Module 的形式,直接引用 Objective-C 的代码。

既然是通过 Module 的形式引入 Objective-C,那么 Framework 的文件结构则是最好的选择,此时编译器寻找方法声明的方式就会有下面三种场景:
- 对于大部分的 Target 而言,当导入的是一个 Objective-C 类型的 Framework 时,编译器会通过 modulemap 里的 Header 信息寻找方法声明。
- 对于一个既有 Objective-C,又有 Swift 代码的 Framework 而言,编译器会从当前 Framework 的 Umbrella Header 中寻找方法声明,从而解决自身的编译问题,这是因为通常情况下 modulemap 会将 Umbrella Header 作为自身的 Header 值。
- 对于 App 或者 Unit Test 类型的 Target,开发者可以通过为 Target 创建 Briding Header 来导入需要的 Objective-C 头文件,进而找到需要的方法声明。
不过我们应该知道 Swift 编译器在获取 Objective-C 代码过程中,并不是原原本本的将 Objective-C 的 API 暴露给 Swift,而是会做一些 “Swift 化” 的改动,例如下面的 Objective-C API 就会被转换成更简约的形式。

这个转换过程并不是什么高深的技术,它只是在编译器上的硬编码,如果感兴趣,可以在 Swift 的开源库中的找到相应的代码 - PartsOfSpeech.def
当然,编译器也给与了开发者自行定义 “API 外貌” 的权利,如果你对这一块感兴趣,不妨阅读我的另一篇文章 - WWDC20 10680 - Refine Objective-C frameworks for Swift,那里面包含了很多重塑 Objective-C API 的技巧。
不过这里还是要提一句,如果你对生成的接口有困惑,可以通过下面的方式查看编译器为 Objective-C 生成的 Swift 接口。

第三步 - Target 内的 Swift 代码是如何为 Objective-C 提供接口的
前面讲了 Swift 代码是如何引用 Objective-C 的 API,那么 Objective-C 又是如何引用 Swift 的 API 呢?
从使用层面来说,我们都知道 Swift 编译器会帮我们自动生成一个头文件,以便 Objective-C 引入相应的代码,就像第二段代码里引入的 PetWall-Swift.h 文件,这种头文件通常是编译器自动生成的,名字的构成是 组件名-Swift 的形式。

但它到底是怎么产生的呢?
在 Swift 中,如果某个类继承了 NSObject 类且 API 被 @objc 关键字标注,就意味着它将暴露给 Objective-C 代码使用。
不过对于 App 和 Unit Test 类型的 target 而言,这个自动生成的 Header 会包含访问级别为 Public 和 internal 的 API,这使得同一 Target 内的 Objective-C 代码也能访问 Swift 里 internal 类型的 API,这也是所有 Swift 代码的默认访问级别。
但对于 Framework 类型的 Target 而言,Swift 自动生成的头文件只会包含 Public 类型的 API,因为这个头文件会被作为构建产物对外使用,所以像 internal 类型的 API 是不会包含在这个文件中。
注意,这种机制会导致在 Framework 类型的 Target 中,如果 Swift 想暴露一些 API 给内部的 Objective-C 代码使用,就意味着这些 API 也必须暴露给外界使用,即必须将其访问级别设置为 Public。
那么编译器自动生成的 API 到底是什么样子,有什么特点呢?

上面是截取了一段自动生成的头文件代码,左侧是原始的 Swift 代码,右侧是自动生成的 Objective-C 代码,我们可以看到在 Objective-C 的类中,有一个名为 SWIFT_CLASS 的宏,将 Swift 与 Objective-C 中的两个类进行了关联。
如果你稍加注意,就会发现关联的一段乱码中还绑定了当前的组件名(PetWall),这样做的目的是避免两个组件的同名类在运行时发生冲突。
当然,你也可以通过向 @objc(Name) 关键字传递一个标识符,借由这个标识符来控制其在 Objective-C 中的名称,如果这样做的话,需要开发者确保转换后的类名不与其他类名出现冲突。

这大体上就是 Swift 如何像 Objective-C 暴露接口的机理了,如果你想更深入的了解这个文件的由来,就需要看看第四步。
第四步 - Swift Target 如何生成供外部 Swift 使用的接口
Swift 采用了 Clang module 的理念,并结合自身的语言特性进行了一系列的改进。
在 Swift 中,Module 是方法声明的分发单位,如果你想引用相应的方法,就必须引入对应的 Module,之前我们也提到了 Swift 的编译器包含了 Clang 的大部分内容,所以它也是兼容 Clang Module 的。
所以我们可以引入 Objective-C 的 Module,例如 XCTest,也可以引入 Swift Target 生成的 Module,例如 PetWall。
import XCTest
@testable import PetWall
class TestPetViewController: XCTestCase {
func testInitialPet() {
let controller = PetViewController()
XCTAssertEqual(controller.view.name, "Fido")
}
}在引入 swift 的 Module 后,编译器会反序列化一个后缀名为 .swiftmodule 的文件,并通过这种文件里的内容来了解相关接口的信息。
例如,以下图为例,在这个单元测试中,编译器会加载 PetWall 的 Module,并在其中找寻 PetViewController 的方法声明,由此确保其创建行为是符合预期的。

这看起来很像第一步中 Target 寻找内部 Swift 方法声明的样子,只不过这里将解析 Swift 文件的步骤,换成了解析 Swiftmodule 文件而已。
不过需要注意的是,这个 Swfitmodule 文件并不是文本文件,它是一个二进制格式的内容,通常我们可以在构建产物的 Modules 文件夹里寻找到它的身影。

在 Target 的编译的过程中,面向整个 Target 的 Swiftmodule 文件并不是一下产生的,每一个 Swift 文件都会生成一个 Swiftmodule 文件,编译器会将这些文件进行汇总,最后再生成一个完整的,代表整个 Target 的 Swiftmodule,也正是基于这个文件,编译器构造出了用于给外部使用的 Objective-C 头文件,也就是第三步里提到的头文件。

不过随着 Swift 的发展,这一部分的工作机制也发生了些许变化。
我们前面提到的 Swiftmodule 文件是一种二进制格式的文件,而这个文件格式会包含一些编译器内部的数据结构,不同编译器产生的 Swiftmodule 文件是互相不兼容的,这也就导致了不同 Xcode 构建出的产物是无法通用的,如果对这方面的细节感兴趣,可以阅读 Swift 社区里的两篇官方 Blog:Evolving Swift On Apple Platforms After ABI Stability 和 ABI Stability and More,这里就不展开讨论了。
为了解决这一问题,Apple 在 Xcode 11 的 Build Setting 中提供了一个新的编译参数 Build Libraries for Distribution,正如这个编译参数的名称一样,当我们开启它后,构建出来的产物不会再受编译器版本的影响,那它是怎么做到这一点的呢?
为了解决这种对编译器的版本依赖,Xcode 在构建产物上提供了一个新的产物,Swiftinterface 文件。

这个文件里的内容和 Swiftmodule 很相似,都是当前 Module 里的 API 信息,不过 Swiftinterface 是以文本的方式记录,而非 Swiftmodule 的二进制方式。
这就使得 Swiftinterface 的行为和源代码一样,后续版本的 Swift 编译器也能导入之前编译器创建的 Swiftinterface 文件,像使用源码的方式一样使用它。
为了更进一步了解它,我们来看看 Swiftinterface 的真实样子,下面是一个 .swift 文件和 .swiftinterface 文件的比对图。

在 Swiftinterface 文件中,有以下点需要注意
- 文件会包含一些元信息,例如文件格式版本,编译器信息,和 Swift 编译器将其作为模块导入所需的命令行子集。
- 文件只会包含 Public 的接口,而不会包含 Private 的接口,例如 currentLocation。
- 文件只会包含方法声明,而不会包含方法实现,例如 Spacesship 的 init、fly 等方法。
- 文件会包含所有隐式声明的方法,例如 Spacesship 的 deinit 方法 ,Speed 的 Hashable 协议。
总的来说,Swiftinterface 文件会在编译器的各个版本中保持稳定,主要原因就是这个接口文件会包含接口层面的一切信息,不需要编译器再做任何的推断或者假设。
好了,至此我们应该了解了 Swift Target 是如何生成供外部 Swift 使用的接口了。
这四步意味着什么?
此 Module 非彼 Module
通过上面的例子,我想大家应该能清楚的感受到 Swift Module 和 Clang Module 不完全是一个东西,虽然它们有很多相似的地方。
Clang Module 是面向 C 语言家族的一种技术,通过 modulemap 文件来组织 .h 文件中的接口信息,中间产物是二进制格式的 pcm 文件。
Swift Module 是面向 Swift 语言的一种技术,通过 Swiftinterface 文件来组织 .swift 文件中的接口信息,中间产物二进制格式的 Swiftmodule 文件。

所以说理清楚这些概念和关系后,我们在构建 Swift 组件的产物时,就会知道哪些文件和参数不是必须的了。
例如当你的 Swift 组件不想暴露自身的 API 给外部的 Objective-C 代码使用的话,可以将 Build Setting 中 Swift Compiler - General 里的 Install Objective-C Compatiblity Header 参数设置为 NO,其编译参数为 SWIFT_INSTALL_OBJC_HEADER,此时不会生成

而当你的组件里如果压根就没有 Objective-C 代码的时候,你可以将 Build Setting 中 Packaging 里 Defines Module 参数设置为 NO,它的编译参数为 DEFINES_MODULE, 此时不会生成

Swift 和 Objective-C 混编的三个“套路”
基于刚才的例子,我们应该理解了 Swift 在编译时是如何找到其他 API 的,以及它又是如何暴露自身 API 的,而这些知识就是解决混编过程中的基础知识,为了加深影响,我们可以将其绘制成 3 个流程图。
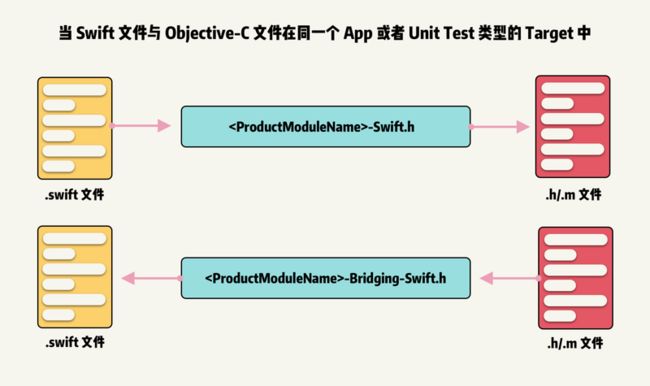
当 Swift 和 Objective-C 文件同时在一个 App 或者 Unit Test 类型的 Target 中,不同类型文件的 API 寻找机制如下:
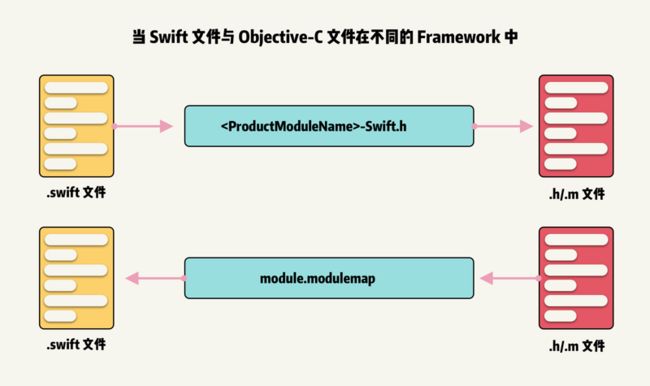
当 Swift 和 Objective-C 文件在不同 Target 中,例如不同 Framework 中,不同类型文件的 API 寻找机制如下:
当 Swift 和 Objective-C 文件同时在一个Target 中,例如同一 Framework 中,不同类型文件的 API 寻找机制如下:
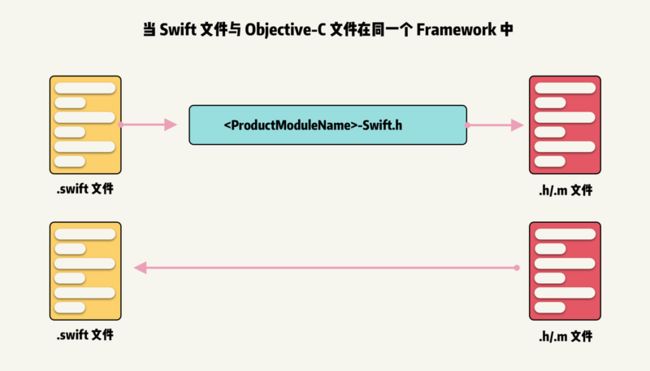
对于第三个流程图,需要做以下补充说明:
- 由于 Swiftc,也就是 Swift 的编译器,包含了大部分的 Clang 功能,其中就包含了 Clang Module,借由组件内已有的 modulemap 文件,Swift 编译器就可以轻松找到相应的 Objective-C 代码。
- 相比于第二个流程而言,第三个流程中的 modulemap 是组件内部的,而第二个流程中,如果想引用其他组件里的 Objective-C 代码,需要引入其他组件里的 modulemap 文件才可以。
- 所以基于这个考虑,并未在流程 3 中标注 modulemap。
构建 Swift 产物的新思路
在前面的章节里,我们提到了 Swift 找寻 Objective-C 的方式,其中提到了,除了 App 或者 Unit Test 类型的 Target 外,其余的情况下都是通过 Framework 的 Module Map 来寻找 Objective-C 的 API,那么如果我们不想使用 Framework 的形式呢?
目前来看,这个在 Xcode 中是无法直接实现的,原因很简单,Build Setting 中 Search Path 选项里并没有 modulemap 的 Search Path 配置参数。

为什么一定需要 modulemap 的 Search Path 呢?
基于前面了解到的内容,Swiftc 包含了 Clang 的大部分逻辑,在预编译方面,Swiftc 只包含了 Clang Module 的模式,而没有其他模式,所以 Objective-C 想要暴露自己的 API 就必须通过 modulemap 来完成。
而对于 Framework 这种标准的文件夹结构,modulemap 文件的相对路径是固定的,它就在 Modules 目录中,所以 Xcode 基于这种标准结构,直接内置了相关的逻辑,而不需要将这些配置再暴露出来。
从组件的开发者角度来看,他只需要关心 modulemap 的内容是否符合预期,以及路径是否符合规范。
从组件的使用者角度来看,他只需要正确的引入相应的 Framework 就可以使用到相应的 API。
这种只需要配置 Framework 的方式,避免了配置 Header Search Path,也避免了配置 Static Library Path,可以说是一种很友好的方式,如果再将 modulemap 的配置开放出来,反而显得多此一举。
那如果我们抛开 Xcode,抛开 Framework 的限制,还有别的办法构建 Swift 产物么?
答案是肯定有的,这就需要借助前面所说的 VFS 技术!
假设我们的文件结构如下所示:
├── LaunchPoint.swift
├── README.md
├── build
├── repo
│ └── MyObjcPod
│ └── UsefulClass.h
└── tmp
├── module.modulemap
└── vfs-overlay.yaml其中 LaunchPoint.swift 引用了 UsefulClass.h 中的一个公开 API,并产生了依赖关系。
另外,vfs-overlay.yaml 文件重新映射了现有的文件目录结构,其内容如下:
{
'version': 0,
'roots': [
{ 'name': '/MyObjcPod', 'type': 'directory',
'contents': [
{ 'name': 'module.modulemap', 'type': 'file',
'external-contents': 'tmp/module.modulemap'
},
{ 'name': 'UsefulClass.h', 'type': 'file',
'external-contents': 'repo/MyObjcPod/UsefulClass.h'
}
]
}
]
}至此,我们通过如下的命令,便可以获得 LaunchPoint 的 Swiftmodule、Swiftinterface 等文件,具体的示例可以查看我在 Github 上的链接 - manually-expose-objective-c-API-to-swift-example
swiftc -c LaunchPoint.swift -emit-module -emit-module-path build/LaunchPoint.swiftmodule -module-name index -whole-module-optimization -parse-as-library -o build/LaunchPoint.o -Xcc -ivfsoverlay -Xcc tmp/vfs-overlay.yaml -I /MyObjcPod那这意味着什么呢?
这就意味着,只提供相应的 .h 文件和 .modulemap 文件就可以完成 Swift 二进制产物的构建,而不再依赖 Framework 的实体。同时,对于 CI 系统来说,在构建产物时,可以避免下载无用的二进制产物(.a 文件),这从某种程度上会提升编译效率。
如果你没太理解上面的意思,我们可以展开说说。
例如,对于 PodA 组件而言,它自身依赖 PodB 组件,在使用原先的构建方式时,我们需要拉取 PodB 组件的完整 Framework 产物,这会包含 Headers 目录,Modules 目录里的必要内容,当然还会包含一个二进制文件(PodB),但在实际编译 PodA 组件的过程中,我们并不需要 B 组件里的二进制文件,而这让拉取完整的 Framework 文件显得多余了。

而借助 VFS 技术,我们就能避免拉取多余的二进制文件,进一步提升 CI 系统的编译效率。
总结
感谢你的耐心阅读,至此,整篇文章终于结束了,通过这篇文章,我想你应该:
- 理解 Objective-C 的三种预编译的工作机制,其中 Clang Module 做到了真正意义上的语义引入,提升了编译的健壮性和扩展性。
- 在 Xcode 的 Search Path 的各种技术细节使用到了 hmap 技术,通过加载映射表的方式避免了大量重复的 IO 操作,可以提升编译效率。
- 在处理 Framework 的头文件索引时,总是会先搜索 Headers 目录,再搜索 PrivateHeader 目录。
- 理解 Xcode Phases 构建系统中,Public 代表公开头文件,Private 代表不需要使用者感知,但物理存在的文件, 而 Project 代表不应让使用者感知,且物理不存在的文件。
- 不使用 Framework 的情况下且以
#import这种标准方式引入头文件时,在 CocoaPods 上使用 hmap 并不会提升编译速度。 - 通过
cocoapods-hmap-built插件,可以将大型项目的全链路时长节省 45% 以上,Xcode 打包环节的时长节省 50% 以上。 - Clang Module 的构建机制确保了其不受上下文影响(独立编译空间),复用效率高(依赖决议),唯一性(参数哈希化)。
- 系统组件通过已有的 Framework 文件结构实现了构建 Module 的基本条件 ,而非系统组件通过 VFS 虚拟出相似的 Framework 文件 结构,进而具备了编译的条件。
- 可以粗浅的将 Clang Module 里的
.h/m,.moduelmap,.pch的概念对应为 Swift Module 里的.swift,.swiftinterface,.swiftmodule的概念 理解三种具有普适性的 Swift 与 Objective-C 混编方法
- 同一 Target 内(App 或者 Unit 类型),基于
-Swift.h -Bridging-Swift.h - 同一 Target 内,基于
-Swift.h - 不同 Target 内,基于
-Swift.h module.modulemap。
- 同一 Target 内(App 或者 Unit 类型),基于
- 利用 VFS 机制构建,可以在构建 Swift 产物的过程中避免下载无用的二进制产物,进一步提升编译效率。
参考文档
- Apple - WWDC 2013 Advances in Objective-C
- Apple - WWDC 2018 Behind the Scenes of the Xcode Build Process
- Apple - WWDC 2019 Binary Frameworks in Swift
- Apple - WWDC 2020 Distribute binary frameworks as Swift packages
- Swift org - Evolving Swift On Apple Platforms After ABI Stability
- Swift org - ABI Stability and More
- StackOverflow - #import using angle brackets < > and quote marks “ ”
- StackOverflow - Xcode: Copy Headers: Public vs. Private vs. Project?
- StackOverflow - Understanding Xcode's Copy Headers phase
- Xcode Help - What are build phases?
- Xcode Build Settings
- Big Nerd Ranch - Manual Swift: Understanding the Swift/Objective-C Build Pipeline
- Big Nerd Ranch - Build Log Groveling for Fun and Profit: Manual Swift Continued
- Big Nerd Ranch - Build Log Groveling for Fun and Profit, Part 2: Even More Manual Swift
- Quality Coding - 4 Ways Precompiled Headers Cripple Your Code
- try! Swift Tokyo 2018 - Exploring Clang Modules
- milen.me - Swift, Module Maps & VFS Overlays
作者简介
- 思琦,笔名 SketchK,美团点评 iOS 工程师,目前负责移动端 CI/CD 方面的工作及平台内 Swift 技术相关的事宜。
- 旭陶,美团 iOS 工程师,目前负责 iOS 端开发提效相关事宜。
- 霜叶,2015 年加入美团,先后从事过 Hybrid 容器、iOS 基础组件、iOS 开发工具链和客户端持续集成门户系统等工作。
| 想阅读更多技术文章,请关注美团技术团队(meituantech)官方微信公众号。
| 在公众号菜单栏回复【2020年货】、【2019年货】、【2018年货】、【2017年货】、【算法】等关键词,可查看美团技术团队历年技术文章合集。
