上两集回顾:
在第一集(点击可参阅详情)中,我们通过性能故障排查解决了Hadoop2.6.0版本的瓶颈问题;
在第二集(点击可参阅详情)中,我们将集群由Hadoop2.6.0版本升级到Hadoop3.2.1版本,且启用联邦模式,解决了Hadoop的第二次瓶颈;
本次,我们将分享一下在联邦模式下如何解决router延迟较大的问题。
下面,enjoy:
一、基于非联邦和联邦模式的测试
在成功将Hadoop2.6.0版本升级到Hadoop3.2.1版本,且启用联邦模式后,当前集群等于有了两个Namenode,不仅总的节点数扩展到了900+,系统的运行也顺畅了许多。
但是两个月后,随着客户每日新增数据的不断攀升,系统所承载的数据总体量也随之愈来愈大,我们发现router出现了延迟较大的问题。
基于此,我们准备在非联邦和联邦模式之下进行对比测试,我们首先将当前集群分为两个子集群,分别为cluster1,cluster2。随后我们对同一组文件的各种操作进行了测试。测试目录为/data/test,当前目录挂载的router的/data/test,并在cluster1的/data/test。
测试结果如下:
1.非联邦模式(cluster1)

2.联邦模式(router模式)

从上面的测试结果中可以观察出,涉及到与元数据的操作(即与Namenode交互的操作)相比于直接操作Namenode与router转发有着明显的差距。
二、 router延迟测试
对于测试发现的问题,我们又做了进一步分析。分析了router的堆栈信息和相关代码之后,我们有了如下几个发现:
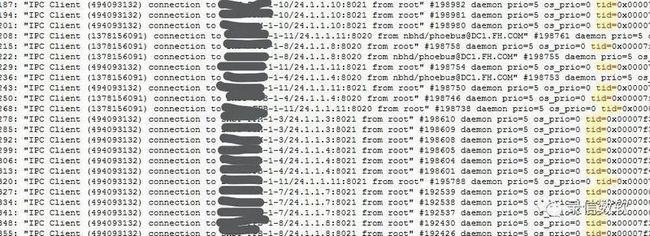
1. 每个router有2800多个链接进入并等待处理

2.部分链接在wait等待处理,实则已经休眠
如下图红框标注的这2800个链接,在wait等待另外一些线程去处理,实际上已经休眠了。

3.导致部分链接休眠的线程实则是在与对应链接的NameNode做转发
4.深入分析这个IP,发现只有一个线程在工作,其余线程都处在空闲状态
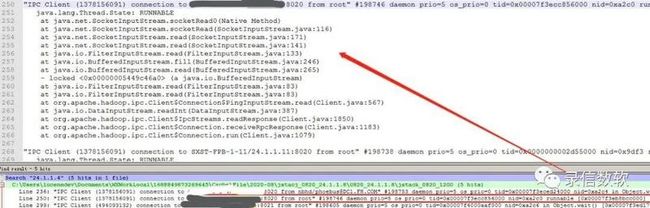
下图为空闲的线程:

三、router延迟原因的排查&解决
1.router延迟的现象分析
在之前的测试中,我们发现router的任务处理逻辑可能存在一定问题。明明已经有2800个链接接入进来,却没有进行并行处理,反而都在排队等着单个线程串行处理。
因此,根据目前的处理逻辑,无论系统中有多少个客户端链接进入,router都是采用单个线程逐个处理的串行方式执行,导致后进入的任务需等待前一个任务执行完毕才能进去处理队列,并且不论进入的链接数有多少,系统每次只能在队列之中选择其中一个任务进行执行。
2.router源码分析
由于考虑到目前这种处理进程可能涉及到router的执行逻辑,因此我们对router源码进行了分析,希望可以查找出原因。
通过观察源码可以发现,同一个remoteId只会创建一个链接:
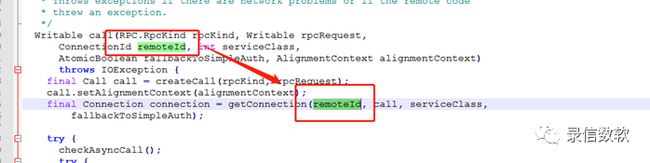
通过进一步挖掘,我们发现remoteId就是NameNode的地址,跟线程名字也是吻合的,如下图所示:

同时我们还发现,client对于同一个server,只会建立一次长链接,通过如下方法区分出不同的请求:

而remoteId也即ConnectionId的构成:

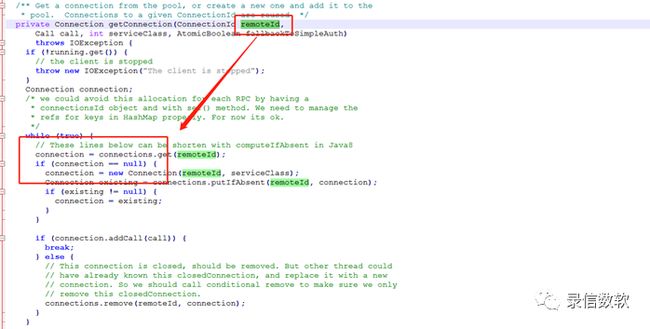
基于此,我们决定修改router源码,将router原本的单线程逐个处理的执行逻辑进行修改,增加一定的并行处理能力,修改方法如下:
创建connectdId并行处理,修改下图绿框处源码,改动connectdId,增加一定的并行。但是需要注意的是,对于这部分的修改仅用于router部分,不要用于真正的client部分,避免建立太多的长链接。

四、总 结
总结一下,HDFS在启用联邦模式之后router延迟变大的问题主要是由于router在任务处理逻辑上的设计缺陷,router对于任务链接的处理是采取单个依次串行处理的方式,这就造成了大量进入链接的积压。
而针对于这个问题的解决方案就是为router增加一部分并行处理的能力,避免任务链接的堆积。
PS:更多干货实践欢迎在微信中关注“录信数软”