统计图表的Captioning和VQA——一些论文笔记
目录
-
- DVQA: Understanding Data Visualizations via Question Answering (CVPR2018)
- ChartOCR: Data Extraction from Charts Images via a Deep Hybrid Framework (WACV2021)
- Answering Questions about Data Visualizations using Efficient Bimodal Fusion
本文收集整理了统计图的信息提取任务相关的论文,持续更新。
DVQA: Understanding Data Visualizations via Question Answering (CVPR2018)
论文链接
研究条形统计图的VQA任务,提出了DVQA数据集,并给出了两个算法。
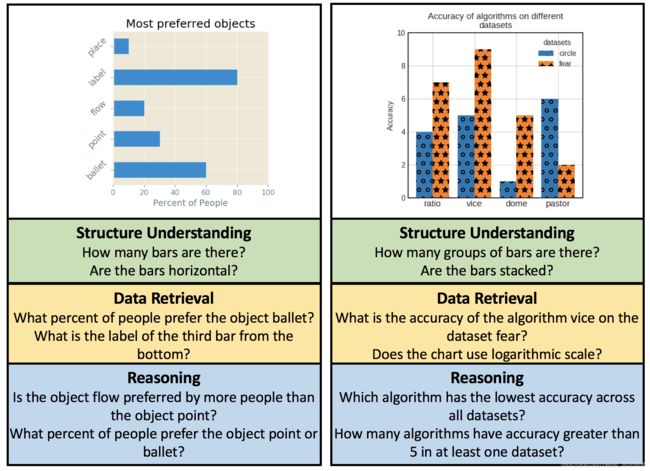 DVQA任务样例
DVQA任务样例
问题的主要挑战(相比于常规的VQA)
- 没有固定的词汇字典,统计图多用专有名词,缩写,连接词等。
- 词没有固定的语义,即词与对象之间没有一一对应关系,标签,图例中的词是任意的,是整个图的描述。
- VQA的对象属性是局部的,但统计图的属性是全局的,对象之间存在着普遍的联系。
本文的主要贡献
- 提出了DVQA数据集,其中包含了超过300万对关于柱状图的图像-问题对。它测试了理解图表的三种形式:a)结构理解;b)数据检索;c)推理。DVQA数据集将公开发布。
- 证明即使是SOTA的VQA算法都不能回答DVQA中的许多问题。此外,现有的基于静态和预定义词汇表的分类系统无法回答在训练过程中不会遇到的独特答案的问题。
- 提出了两种解决DVQA的算法。一种是端到端神经网络(MOM),它可以从柱状图中读取答案。第二种是使用动态本地字典编码条形图文本的模型(SANDY)。
DVQA数据集是用matplotlib生成的,具体过程以及数据统计略。
有两种题型:对于每个图表通用的一般疑问句,和对特定图表有效的特殊疑问句。
问题涵盖三个方面:a)结构理解、 b)数据检索、c)数据推理。例子见上图。
测试集有两种问题涵盖单词范围:Test-Familiar只包括训练集中有的单词、Test-Novel还包含新出现的单词。
图像模型都使用ImageNet预训练的ResNet-152 CNN, 输入448 × 448,输出14×14×2048 特征张量,除非另有说明。处理问题的模型都使用1024个单元的单层LSTM对问题进行编码,其中问题中的每个单词都嵌入到一个密集的300维表示中。
五个对照组Baseline:YES(全输出yes)、IMG(问题盲,即不输入问题,CNN直接通过MLP输出答案)、QUES(图像盲,LSTM直接通过MLP输出答案)、IMG+QUES、SAN-VQA(The Stacked Attention Network,堆叠注意力网络,VQA-v1数据集的SOTA)。
模型
Multi-Output Model (MOM)
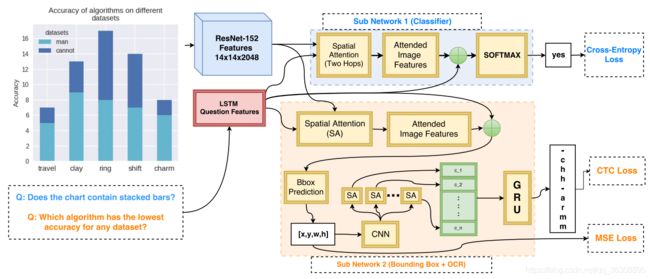 多输出模型(MOM)的DVQA。MOM使用两个子网:1)负责一般疑问句的分类子网(与SAN-VQA相同)2)负责特殊疑问句的OCR子网。
多输出模型(MOM)的DVQA。MOM使用两个子网:1)负责一般疑问句的分类子网(与SAN-VQA相同)2)负责特殊疑问句的OCR子网。
MOM的OCR子网络尝试预测包含正确标签的边界框,然后对该区域应用字符级解码器。边界框预测器被训练为使用均方误差(MSE)损失的回归任务。从该区域提取一个图像patch,将其大小调整为128 × 128,然后再进行一个小的3层CNN。由于文本在方框中的方向不同,我们采用n步空间注意机制对每个文本的相关特征来编码图像patch中可能的N个字符,其中N为可能的最大字符序列(在我们的实验中N = 8)。这些N个特征使用双向门控循环单元(GRU)进行编码,以捕获自然出现的单词中的字符级别相关性。GRU编码之后是一个分类层,它预测字符序列,使用CTC loss训练。
MOM必须决定是使用分类子网(即SAN-VQA)还是OCR子网来回答问题。为此训练一个单独的二进制分类器来确定哪些输出值得信任。这个分类器接受LSTM问题特征作为输入,以预测答案是一般还是特殊的。在DVQA中精度可达100%。
SANDY: SAN with DYnamic Encoding Model
本文对SAN进行了修改,创建具有动态编码模型的SANDY。SANDY使用了一个动态编码模型(DEM),该模型明确地对问题中特定于图表的单词进行编码,并可以直接生成特定于图表的答案。DEM是用于特定于图表的单词的动态本地字典。这本词典既用于编码单词,也用于编码答案。
为了创建一个本地字典,DEM假设它能够访问一个OCR系统,该系统为它提供条形图中所有文本区域的位置和字符串。给定这个方框集合,DEM为每个方框分配一个唯一的数字索引。它将索引0赋值给图像左下角的方框。然后,它将最接近第一个盒子的位置赋值为1。最接近1的方框没有被指定索引,然后被指定索引2,以此类推,直到图像中的所有方框都被指定索引。在我们的实现中,我们假设我们有一个完美的(oracle先验的) OCR系统用于输入,为此我们使用数据集的注释。训练数据中的图表没有超过30个文本标签,所以我们设置本地字典最多有M = 30个元素。本地字典扩充了N个元素的全局字典。这使DEM能够创建(M + N)单词字典,用于对问题中的每个单词进行编码。本地字典也用于扩充L个元素全局答案字典。这是通过向表示动态单词的分类器添加M个额外的类来实现的。如果这些类是预测的,则使用本地字典的适当索引分配输出字符串。我们测试了两个版本的SANDY。oracle版本直接使用来自DVQA数据集的注释来构建。OCR版本使用开源TesseractOCR。Tesseract的输出以三种方式进行预处理:1)我们只使用带有字母字符的单词,2)我们过滤单词检测的可信度小于50%,3)我们过滤单个字符的单词检测。
训练过程略
本文首先把生成答案与真实答案相同看作正确的。为了更好地评估MOM,本文使用编辑距离(edit distance)来度量它的性能,编辑距离表示为MOM(±1)。只要它生成的答案与正确答案相比在一个编辑距离之内或更小,就看作是正确的。
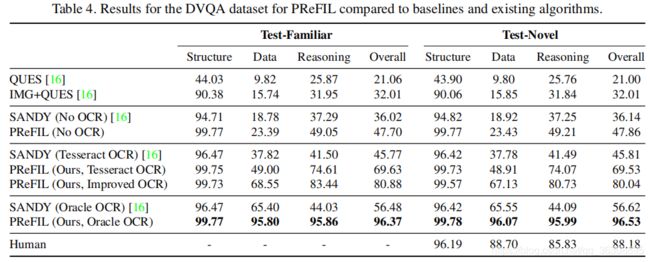
结果
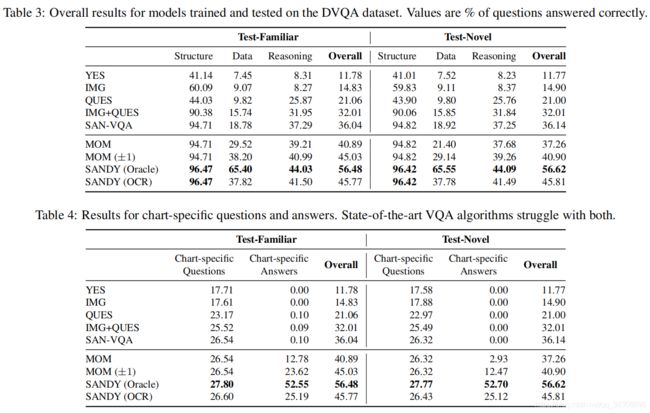
ChartOCR: Data Extraction from Charts Images via a Deep Hybrid Framework (WACV2021)
论文链接
代码和数据集
研究在统计图中提取数据信息。
本文的主要贡献
- 提出了CharOCR,一种结合了深度学习和基于规则方法优点的深度混合框架。ChartOCR在所有三种主要图表类型的图表数据提取任务上实现了SOTA。结果表明,将深度框架和基于规则的方法相结合,可以获得较好的泛化能力,并获得准确、语义丰富的中间结果。
- 为这些图表类型设计了新的评估指标。
- 引入了ExcelChart400K数据集。
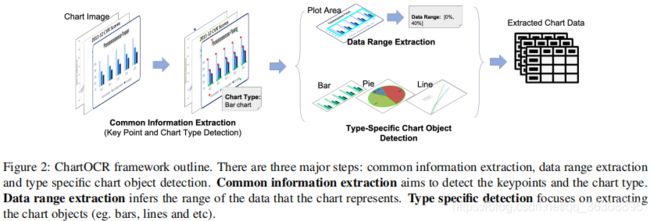
模型
-
常规信息提取 目的是检测关键点和图表类型。
关键点检测 在这一步,我们提取图表组件的关键点独立于图表样式。有了通用的关键点检测模型,我们不再需要针对不同的图表训练单独的目标检测模块。对于未见过的样式的图表图像,我们只需要通过增加更多反映新的图表样式的样本来微调现有的关键点检测模型。根据图表类型的不同,关键点的定义略有不同。对于柱状图,关键点是每个柱的左上角和右下角。在折线图中,关键点是线上的轴点。对于饼图,关键点是中心点加上弧线上的交点,弧线将图分割成多个扇区。

使用沙漏网络来提供关键位置的像素级概率图。在关键点检测分支的倒数第二层采用角点池化层,沿水平和垂直方向增加接受野。(以彩色浏览最佳)
关键点检测网络的输出是一个突出关键点位置像素点的概率图。概率图有3个通道来预测左上角、右下角和背景的位置。输出概率图的大小与输入图像相同。关键点检测网络的倒数第二层是采用的角点池化层
CornerNet[15]。角点池化层在水平方向和垂直方向分别执行max-pool,这有助于卷积层更好地定位关键点位置。我们遵循CornerNet的设置,将损失函数定义为概率映射损失和关键点坐标平滑L1损失的总和。
图表类型检测 我们在沙漏网络的直接输出上增加了一个额外的卷积层,将关键点特征映射卷积成更小的尺寸,例如:(32×32)。然后我们对它应用max-pooling来得到一个一维向量。然后,我们将中间特征向量提供给全连接层,以预测图表类型。该分支的最后一层全连接采用softmax激活函数,该分支采用交叉熵损失训练。 -
数据取值范围提取
数据取值范围提取帮助我们将检测到的关键点从图像像素空间转换为数值读数。数据取值范围提取适用于线图和柱状图。对于饼图,所有扇区的总和默认为100%,可以跳过数据取值范围提取。
我们使用Microsoft OCR API从图像中提取文本。提取的文本来自图例,标题和轴标签。对于数据范围提取,我们需要识别仅与y轴相关的数字。为了分离出这些y轴标签,我们假设这些数字总是在绘图区域的左侧。因此,我们只需要确定绘图区域的位置,然后可以很容易地过滤y轴标签。绘图区域也是由左上角和右下角来定义的,所以我们可以按照关键点检测的方法来定位绘图区域。一旦我们有了绘图区域的位置和OCR结果,我们就通过数据取值范围估计算法1,得到图表的数据范围。在这个算法中,我们首先使用检测到的角点识别图形区,然后在绘图区域的左侧找到已识别的数字,最后使用顶部和底部数字计算的数据范围和像素范围内的点映射到实际的数据值。

-
特定类型的图表对象检测
原理是用关键点定位对象。- 柱图:将所有左上角的关键点与相应的右下角的关键点相匹配,以构造bar对象。
- 饼图:对每个扇区元素,关键点检测网络提取中心点 p v p_v pv和弧点 p a r c p_{arc} parc。当将关键点分组形成扇区时,我们考虑两种情况:(1)所有扇区聚集在一起形成一个圆形(椭圆形)的紧密饼图(2)一个或多个扇区彼此分开的爆炸式饼图。设计了算法2来确定每个扇区。对于第一种情况,我们只需要按时钟顺序排序弧点,并计算每个扇区的部分。对于第二种情况,我们包括饼状半径估计步骤,我们找到最优半径,可以连接所有的中心和弧点。中心点和弧点有1:N的映射,也就是说,一个或多个扇区可以与一个中心点相连。我们检查中心点和候选弧点之间的距离是否在某个阈值内。如果是,则这对数据属于同一个扇区,否则不是。

- 折线图:关键点检测网络可以预测轴点在直线上的位置。为了将关键点按照它们所属的线进行分组,我们在关键点提取分支(图3中的conv1之后)附加一个卷积层作为嵌入层。我们将同一直线上的点的特征嵌入尽量接近,不同直线上的点的特征嵌入尽可能远。嵌入损失函数: e m k = 1 N ∑ i e i k , where { e i k } belong to a same line k l o s s p u l l = 1 K ∑ k 1 N ∑ i ( e i k − e m k ) 2 l o s s p u s h = 1 C K 2 ∑ i ∑ j > i max ( ( 1 − ∣ e m i − e m j ∣ ) , 0 ) l o s s e m b e d d i n g = l o s s p u l l + l o s s p u s h e_m^k=\frac{1}{N}\sum_i e_i^k , \quad \text{where } \{ e_i^k\} \text{ belong to a same line } k \\ loss_{pull}=\frac{1}{K}\sum_k \frac{1}{N}\sum_i (e_i^k - e_m^k)^2 \\ loss_{push}=\frac{1}{\textbf{C}^2_K}\sum_i\sum_{j>i}\max ((1-|e_m^i - e_m^j|),0) \\ loss_{embedding}=loss_{pull}+loss_{push} emk=N1i∑eik,where { eik} belong to a same line klosspull=K1k∑N1i∑(eik−emk)2losspush=CK21i∑j>i∑max((1−∣emi−emj∣),0)lossembedding=losspull+losspush
折线图关键点检测网络的总损失定义为 l o s s p o i n t ′ = l o s s p o i n t + λ ⋅ l o s s e m b e d d i n g loss_{point'} = loss_{point} +\lambda \cdot loss_{embedding} losspoint′=losspoint+λ⋅lossembedding,其中 l o s s p o i n t loss_{point} losspoint为关键点检测描述的概率映射损失和平滑L1损失的总和。实验中使用 λ = 0.1 \lambda =0.1 λ=0.1。为了形成给定关键点的折线,我们采用层次聚类策略,将关键点的嵌入与经典的并查集算法进行分组。这样,每个聚类包含属于同一条线的点。然而,有些点可能属于两个(或更多)行,它们在聚类算法中通常被视为异常值。我们称这些点为交点,并提出查询网络来预测它们应该被分配到哪一行。对于每一对,设 ( x s , y s ) (x_s, y_s) (xs,ys)表示交点s的位置, e = ( x e , y e ) e = (x_e, y_e) e=(xe,ye)表示已分配给一个聚类的距离 s s s最近的点。我们在直线 s − e s-e s−e上等距离采样 K K K个点。样本点位置的计算公式如下: p k = ( x s + ( k − 1 ) d x , y s + ( k − 1 ) d y ) d x = x e − x s k , d y = y e − y s k p_k = (x_s + (k-1)d_x, \ y_s + (k-1)d_y) \\ d_x=\frac{x_e-x_s}{k}, \ d_y=\frac{y_e-y_s}{k} pk=(xs+(k−1)dx, ys+(k−1)dy)dx=kxe−xs, dy=kye−ys k k k表示第 k k k个采样点。由于样本点位置是浮点数而不是整数,因此我们使用线性插值来获得样本点的特征。然后我们可以使用查询网络以这 K K K个样本点作为输入,对点 s s s和点 e e e是否属于同一条线上进行分类。
数据集
FQA 该数据集包含100个柱状图、饼状图和折线图的合成图像。不过在图表风格上的变化不大。
WebData 此数据集与FQA具有相同的大小。图像是从网络上抓取的,图表风格的变化比FQA大得多。
ExcelChart400K 深度神经网络很容易在像FQA和WebData这样的小数据集上进行过拟合,因此我们通过从网上抓取公共Excel表格收集了一个包含386,966张图表图像的大规模数据集。我们首先用Excel api捕获图表图像,然后提取图表的底层数据值。(为了保护隐私,我们用随机字符覆盖图表中的文本,进行了数据匿名化。)
评价指标
- 柱形图:对于输入的柱形图,目标是匹配预测边界框 p = [ x p , y p , w p , h p ] p=[x_p,y_p,w_p,h_p] p=[xp,yp,wp,hp]和真实边界框 g = [ x g , y g , w g , h g ] g=[x_g,y_g,w_g,h_g] g=[xg,yg,wg,hg]。首先,我们自定义了一个距离函数,用于两两点的比较: D ( p , g ) = min ( 1 , ∣ ∣ x p − x g w g ∣ ∣ + ∣ ∣ y p − y g h g ∣ ∣ + ∣ ∣ h p − h g h g ∣ ∣ ) D(p,g)=\min (1, ||\frac{x_p-x_g}{w_g}||+||\frac{y_p-y_g}{h_g}||+||\frac{h_p-h_g}{h_g}||) D(p,g)=min(1,∣∣wgxp−xg∣∣+∣∣hgyp−yg∣∣+∣∣hghp−hg∣∣)这里我们只考虑 x , y , h x, y, h x,y,h之间的差异,因为 w w w与图表读数无关。然后我们计算两两代价矩阵 C \textbf{C} C,其中 C n , m = D ( p n , g m ) \textbf{C}_{n,m} = D(p_n, g_m) Cn,m=D(pn,gm)。那么我们可以将其作为作业分配问题来求解总成本的最小值: c o s t = min X ∑ i K ∑ j K C i , j X i , j cost = \min_{\textbf{X}}\sum_i^K\sum_j^K \textbf{C}_{i,j}\textbf{X}_{i,j} cost=Xmini∑Kj∑KCi,jXi,j那么分数可以定义为 s c o r e = 1 − c o s t / K score = 1-cost/K score=1−cost/K,其中 K = max ( N , M ) . X ∈ { 0 , 1 } K = \max(N, M). \textbf{ X}\in \{0,1\} K=max(N,M). X∈{ 0,1}是一个二进制分配矩阵,因为每个点只被分配一次。
- 折线图:由于一行定义了连续数据的序列,我们将其视为连续相似问题。令 P = [ ( x 1 , y 1 ) , … , ( x N , y N ) ] P = [(x_1, y_1),\dots ,(x_N, y_N)] P=[(x1,y1),…,(xN,yN)]为预测点集, G = [ ( u 1 , v 1 ) , … , ( u M , v M ) ] G = [(u_1, v_1),\dots,(u_M, v_M)] G=[(u1,v1),…,(uM,vM)]为ground-truth集合。我们用预测率 P r e c Prec Prec和召回率 R e c Rec Rec来定义ground-truth点集 G G G到预测点集 P P P之间的平均错误率: P r e c ( P , G ) = R e c ( G , P ) R e c ( P , G ) = ∑ i = 1 M ( 1 − E r r ( v i , u i , P ) ) ∗ I n t v ( i , G ) u M − u 1 F 1 = 2 ⋅ P r e c ⋅ R e c ( P r e c + R e c ) Prec(P,G)=Rec(G,P) \\ Rec(P,G)=\frac{\sum_{i=1}^M(1-Err(v_i,u_i,P)) * Intv(i,G)}{u_M-u_1} \\ F1=2\cdot Prec\cdot Rec(Prec + Rec) Prec(P,G)=Rec(G,P)Rec(P,G)=uM−u1∑i=1M(1−Err(vi,ui,P))∗Intv(i,G)F1=2⋅Prec⋅Rec(Prec+Rec)其中 E r r ( v i , u i , P ) Err(v_i,u_i,P) Err(vi,ui,P)定义了点集P匹配点 ( u i , v i ) (u_i,v_i) (ui,vi)的错误率。 I n t v ( i , G ) Intv(i,G) Intv(i,G)定义了第 i i i个点在最终分数中的比率。具体来说: E r r ( v i , u i , P ) = min ( 1 , ∣ ∣ v i − I ( P , u i ) v i ∣ ∣ ) I n t v ( i , G ) = { u i + 1 − u i 2 , for i = 1 u i − u i − 1 2 , for i = M , u i + 1 − u i − 1 2 , for 1 < i < M Err(v_i,u_i,P)=\min (1,||\frac{v_i-I(P,u_i)}{v_i}||) \\ Intv(i,G)=\begin{cases}\frac{u_{i+1}-u_i}{2}, & \text{for }i=1 \\ \frac{u_{i}-u_{i-1}}{2}, & \text{for }i=M, \\ \frac{u_{i+1}-u_{i-1}}{2}, & \text{for }1
- 饼形图:数据值和排序对于读取饼图都很重要。对于饼图图像,我们认为数据提取是一个序列匹配问题。让 P = [ x 1 , … , x N ] P = [x_1, \dots,x_N] P=[x1,…,xN]为顺时针方向的预测数据序列, G = [ y 1 , … , y M ] G = [y_1,\dots,y_M] G=[y1,…,yM]为真实数据序列。则匹配得分 s c o r e ( N , M ) score(N, M) score(N,M)可定义为: s c o r e ( i , j ) = max ( s c o r e ( i − 1 , j ) , s c o r e ( i , j − 1 ) , s c o r e ( i − 1 , j − 1 ) + 1 − ∣ ∣ x i − y j y j ∣ ∣ ) s c o r e = s c o r e ( N , M ) M score(i,j)=\max(score(i-1,j),score(i,j-1),score(i-1,j-1)+1-||\frac{x_i-y_j}{y_j}||) \\ score=\frac{score(N,M)}{M} score(i,j)=max(score(i−1,j),score(i,j−1),score(i−1,j−1)+1−∣∣yjxi−yj∣∣)score=Mscore(N,M)其中 ∀ i s c o r e ( i , 0 ) = 0 \forall i \ score(i, 0) = 0 ∀i score(i,0)=0, ∀ j s c o r e ( 0 , j ) = 0 \forall j \ score(0, j) = 0 ∀j score(0,j)=0。通过动态规划得到得分。
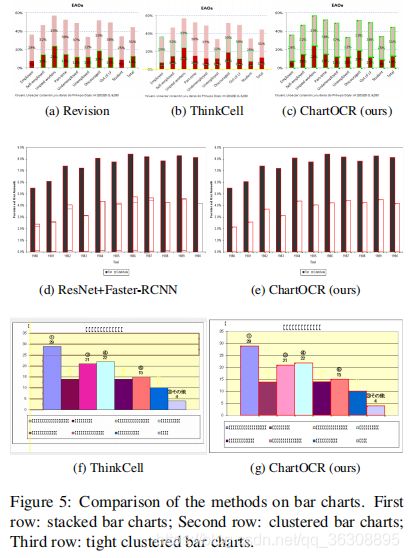
实验结果

Answering Questions about Data Visualizations using Efficient Bimodal Fusion
论文链接 代码链接
DVQA论文的后续研究。柱状图、饼图和线图。
本文主要贡献
- 我们提出了一种新的算法,称为并行递归的 早期的图像和语言融合(PReFIL)。PReFIL首先通过融合问题和图像特征来学习双模嵌入,然后智能地聚合这些学习的嵌入来回答给定的问题。PReFIL大大超越了现有的方法。在DVQA和FigureQA上的表现也优于人类。
- 我们率先使用迭代式问题回答,以从图表中重建表格。
- 根据我们的结果,我们勾勒出一个路线图,以实现创建更具挑战性的数据集和算法,以用于了解数据可视化。
模型
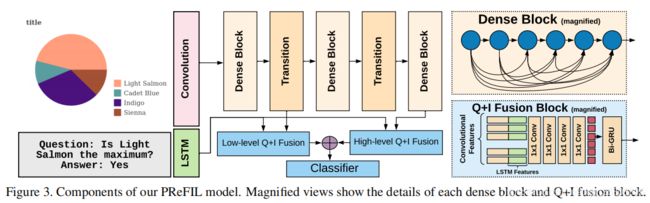
PReFIL有两个并行的Q+I(question+image)融合分支。每个分支接受来自LSTM的问题特征和从40层DenseNet的两个位置(即,低级特征(来自第14层)和高级特征(来自第40层))的图像特征。每个 Q+I 融合块将问题特征与卷积特征图的每个元素相连接,然后它有一系列的 1 × 1 卷积来创建特定问题的双模嵌入。这些嵌入会被反复聚合,然后喂给一个预测答案的分类器。尽管PReFIL由相对简单的元素组成,但其性能优于使用RN(relation network,FigureQA数据集原始工作)和注意力机制的更复杂的方法。对于DVQA,还需要额外的第四个OCR集成组件。
结果