python数据分析数据标准化及离散化
标准化
1。离差标准化
是对原始数据的线性变换,使结果映射到[0,1]区间。方便数据的处理。消除单位影响及变异大小因素影响。
基本公式为:
x’=(x-min)/(max-min)
代码:
#!/user/bin/env python
#-*- coding:utf-8 -*-
#author:M10
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
import mysql.connector
conn = mysql.connector.connect(host='localhost',
user='root',
passwd='123456',
db='python')#链接本地数据库
sql = 'select price,comment from taob'#sql语句
data = pd.read_sql(sql,conn)#获取数据
#离差标准化
data1 = (data-data.min())/(data.max()-data.min())
print(data1)运行结果
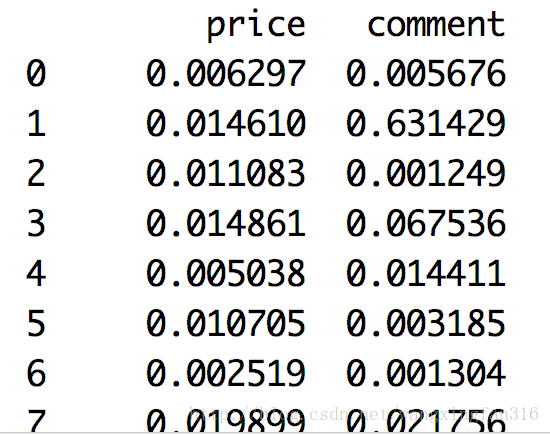
2。标准差标准化
消除单位影响以及变量自身变异影响。(零-均值标准化)
基本公式为:
x’=(x-平均数)/标准差
python代码:
#!/user/bin/env python
#-*- coding:utf-8 -*-
#author:M10
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
import mysql.connector
conn = mysql.connector.connect(host='localhost',
user='root',
passwd='123456',
db='python')#链接本地数据库
sql = 'select price,comment from taob'#sql语句
data = pd.read_sql(sql,conn)#获取数据
#标准差标准化
data1 = (data-data.mean())/data.std()
print(data1)
运行结果:
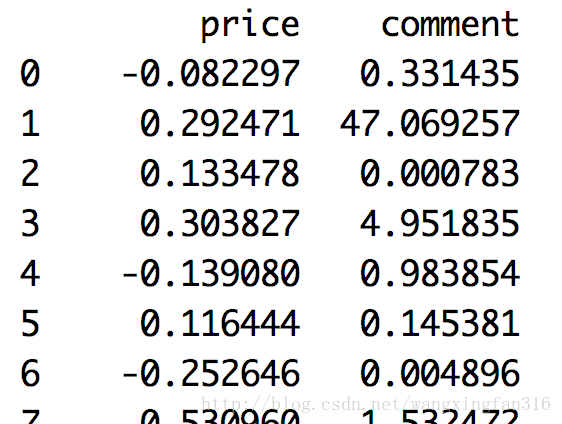
3。小数定标标准化
消除单位影响
基本公式为:
其中j=lg(max(|x|)),即以10为底的x的绝对值最大的对数
x' = x/10^j实现代码为:
#!/user/bin/env python
#-*- coding:utf-8 -*-
#author:M10
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
import mysql.connector
conn = mysql.connector.connect(host='localhost',
user='root',
passwd='123456',
db='python')#链接本地数据库
sql = 'select price,comment from taob'#sql语句
data = pd.read_sql(sql,conn)#获取数据
#标准差标准化
j = np.ceil(np.log10(data.abs().max()))#进一取整,abs()为取绝对值
data1 = data/10**j
print(data1)结果:
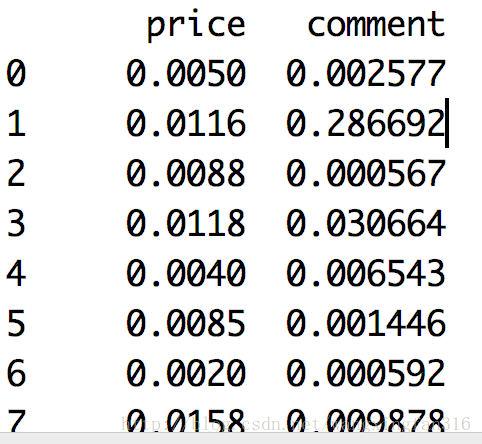
离散化
离散化是程序设计中一个常用的技巧,它可以有效的降低时间复杂度。其基本思想就是在众多可能的情况中,只考虑需要用的值。离散化可以改进一个低效的算法,甚至实现根本不可能实现的算法
1。等宽离散化
将连续数据按照等宽区间标准离散化数据,好处之一是处理的数据是有限个数据而不是无限多。
使用pandas的cut方法。非等宽只需要更改cut的第二个参数,例如:第二个参数为[1,100,3000,10000,200000],即划分为了四个区间。
#!/user/bin/env python
#-*- coding:utf-8 -*-
#author:M10
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
import mysql.connector
conn = mysql.connector.connect(host='localhost',
user='root',
passwd='123456',
db='python')#链接本地数据库
sql = 'select price,comment from taob'#sql语句
data = pd.read_sql(sql,conn)#获取数据
#离散化
data1 = data['price'].T.values#获取价格的一维数组
lable=['很低','低','中','高','很高']
data2 = pd.cut(data1,5,labels=lable)
print(data2)执行结果:

2。等频率离散化
将相同数量的数据放进一个区间。
3。一维聚类离散化
按属性对数据进行聚类离散。