资料来自于:七月在线https://www.julyedu.com/course/getDetail/55
把词映射成向量,即机器所能理解的数据。
图像+DeepLearning非常火,因为图像是人所能接受的直观感受。
文本是人有智慧的时候token,更加高级。如,语境,语意。
也就是你对原始数据的表达决定了你算法的上线。而我们采用的这些机器学习算法如HMM,SVM、CRF、CNN,RNN...等等只是让我们去更加接近(逼近)这个上线。因此词向量很重要。
word encoding ----》 node encoding
向量是可以做运算的,放到NE上也就是节点局部结构相似,比较邻接的点。

N-gram N元模型
I love you
you love I
为了区分话语的含义
2-gram二元组 : 把相邻的两个单词放在一起看,两两组合成一个10维的列向量。然后进行词频统计。

形式:1-gram 2-gram 3-gram 4-gram 5-gram .....
贝叶斯公式 进行 语言(词组)建模

每一词的出现依赖于前一个词。
处理是注意:因为都是小数,乘积会使得数值越来越小,一般我们会取log进行求和运算。

酒店 宾馆 旅社 都是一个含义,但是向量表示的都很稀疏,而且不相同。
无论1-gram,还是2-gram,还是n-gram....他们的形式无非都是one-hot 或者 TF-IDF
Distributed Representation
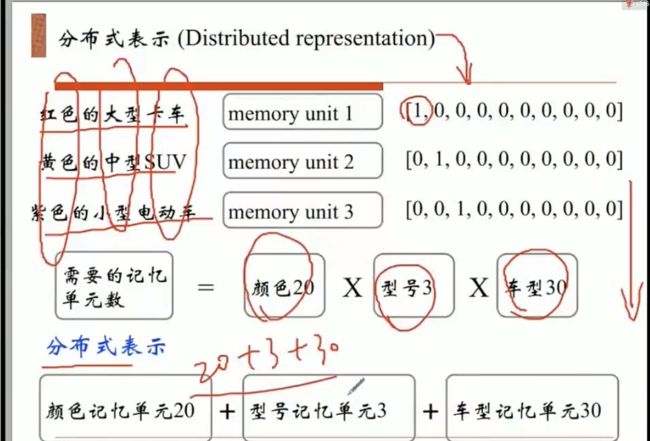
所谓的分布式就是,你让我一个节点去表达我自己这比较困难,我可以将我的信息分散出去,用我周围的词来代表我。

当你训练的数据量大的时候,即使我不知道banking的含义,但是我知道那些词大概和banking相关。

根据六度分理理论,在复杂网络研究中我们大概可以设计窗口的大小是6
对称的窗函数
对称举证
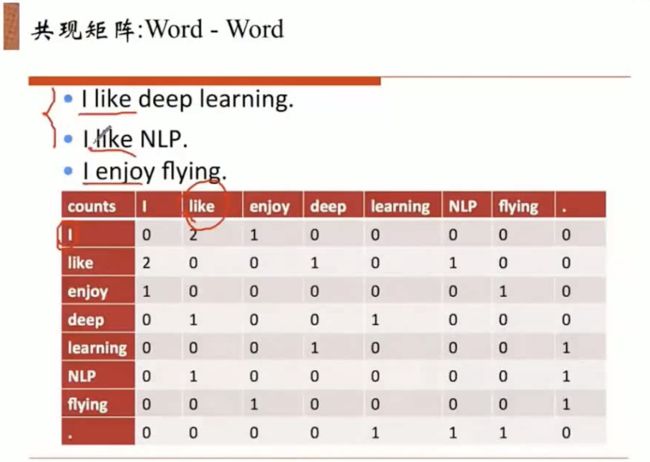
矩阵的每一行,纯天然的就可以做为一个vector。词向量。

共现矩阵 Cocurrence Matrix 就类似于我们图中的邻接矩阵
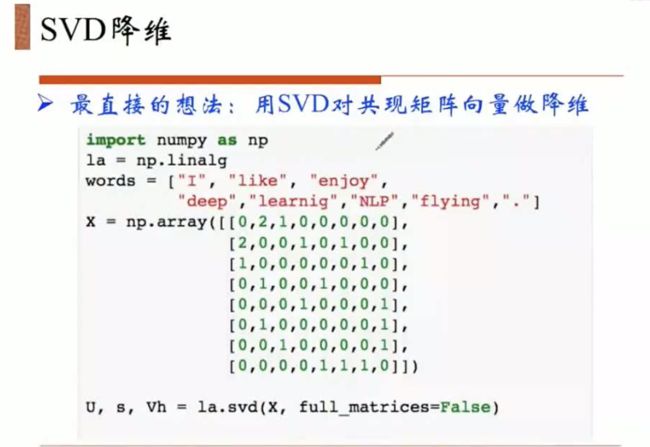
解决:降维
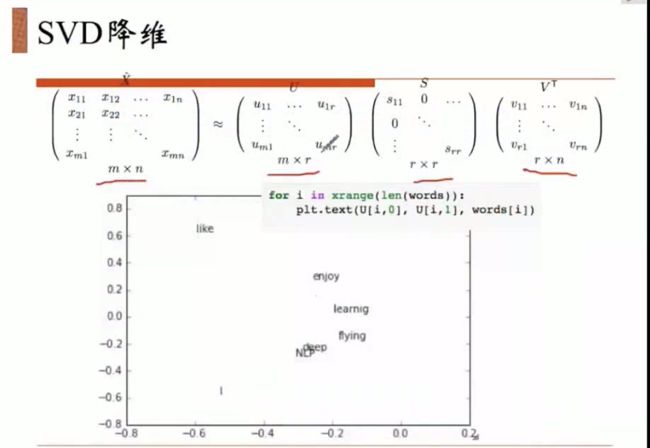
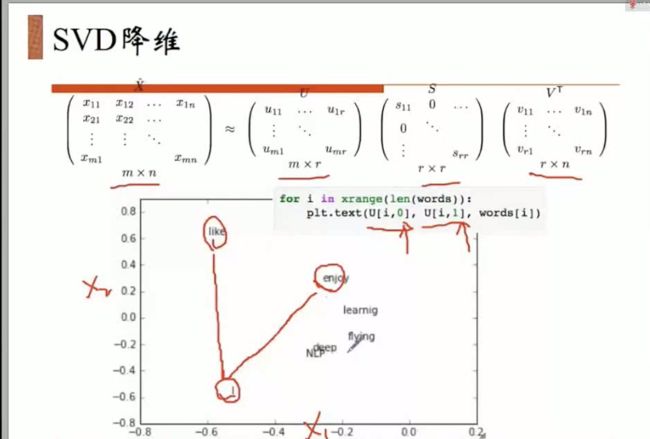
观察I与like 和 I与enjoy的距离是不是相一致。

神经网络最怕的东西就是维度太高了,因为它要和后面层的神经元做链接,维度太高计算量跟不上去。
向量压缩:
sparse --》 dense vector

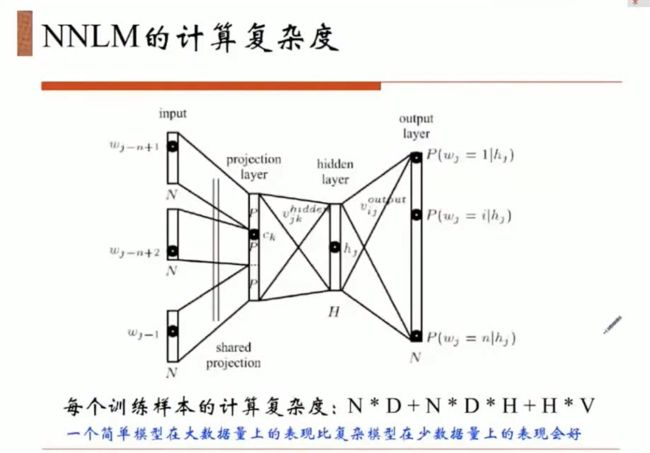
5-gram 很稀疏 sparse 统计不好统计,平滑也不好平滑,要把所有的语料都要过一遍,还要计算概率因此需要很大存储空间,那么用没有一个参数化的方法来构建模型,去完成语言模型建模,就不用统计语料库在进行概率统计了,而是用一组参数来解决这个问题。真正需要计算这个概率的时候,你只要把词喂过这个模型我就可以拿到一个概率。
例如:我爱北京天安门
目标函数值越大越好,代表越接近标准答案。
最大似然
后买就是一个上下文
我爱北京天安门 .....
我们统计的是词wt(天安门)的概率
用w_t-n+1,....,w_t-1(我爱北京)来推断这个词的概率
t是可以滑动的
第二个公式的意思是。w_t-n+1,....,w_t-1(我爱北京)可以接词表中的所有词,这些词加到一起的和为1.
窗口的长度是fixed固定住的。
基础:全链接的人工神经网络。
4-gram 用前面三个词 w1 w2 w3来预测第四个词w4。
w输入的是一个:one-hot表示
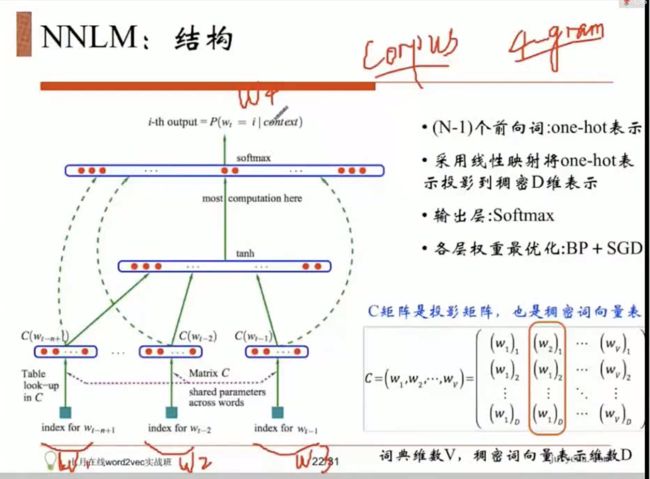
投影层
c是300*10w 的参数矩阵
300*10w 乘 10W*1 = 300*1
一般是是300到500维
softmax 线性分类器
word2vec
2013年提出来
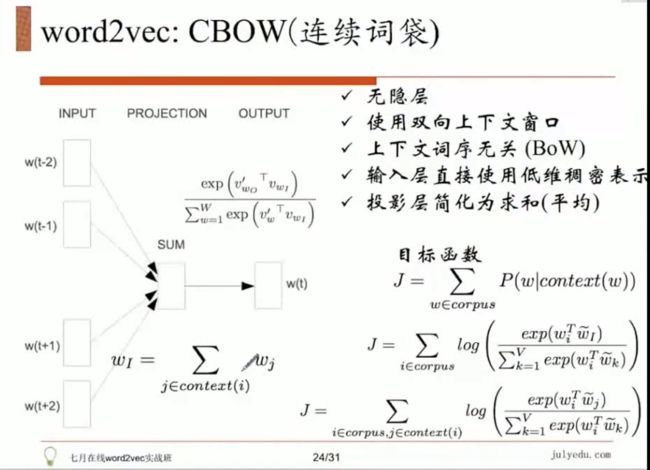
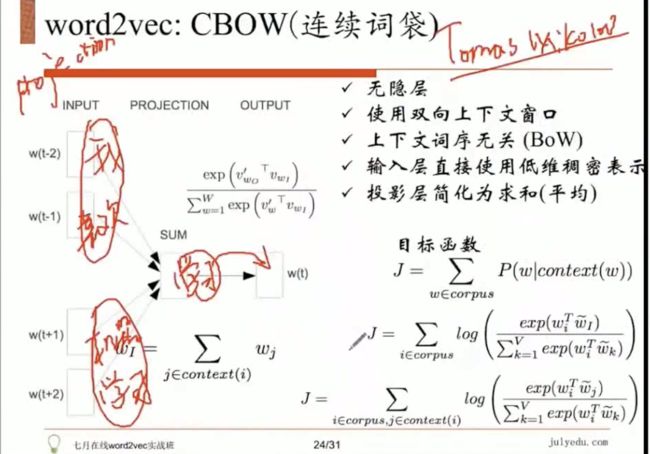
我 喜欢 学习 机器 学习
用 “我 ” “喜欢 ” “机器” “学习”,预测中间的“学习”。
word2vec 没有做拼接 ,而是直接做了一个求和。从而直接去预测后面这个词。
把投影层简化为求和
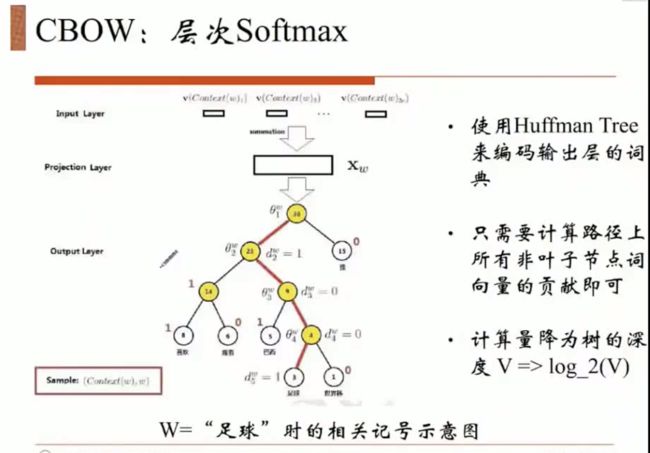
10w维度太长了,把它编码成更加低维的信息。把数据量压缩到logV的样子。做决策的时候也是依据树来做决策,每一个节点都是做一个LR模型决策。往左走正样本,往右边走负样本。
哈夫曼编码的树
我喜欢巴西足球世界杯
连续做决策的分类,树的边上有参数。
1001 足球
每个节点都是一个分类
优势在于数据量的压缩。

10w的词


标准答案就是正样本,
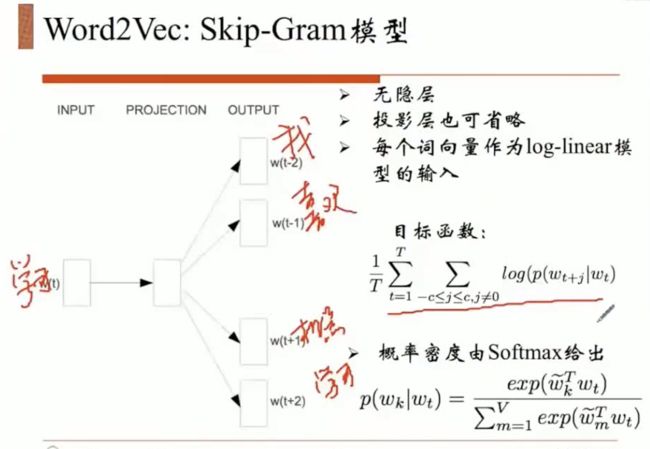
用一个词去预测四个词,

还是说没听懂!!!23333!!!
宝宝不要生气啦~~~