Wassertein距离详解
该文是我投稿于PaperWeekly的一篇文章,如果大家有什么问题想要跟我讨论,可以留言跟我一起交流。
引言
WGAN的横空出世引出了一个更好度量两个概率分布差异的指标即Wassertein距离(或叫做推土机距离),它主要优势就在于该距离具有连续性的特质。TV散度和JS散度的缺点在于这两个距离不具有连续性,这会导致在神经网络参数优化的过程中梯度会消失,KL散度则是因为该距离不具有对称性即 K L ( p ( x ) , p ( y ) ) ≠ K L ( p ( y ) , p ( x ) ) KL(p(x),p(y))\neq KL(p(y),p(x)) KL(p(x),p(y))=KL(p(y),p(x))。本文会从Monge问题开始详细介绍关于Wassertein距离的一些相关背景和证明,最后给出了一个实例有助于理解Wassertein距离这个概念。
Monge问题(最优传输映射)
一般情况下,假定 X X X和 Y Y Y是完备、可分的度量空间,例如欧式空间的子集 Ω ⊂ R n \Omega \subset \mathbb{R}^{n} Ω⊂Rn,通常是紧集。 P ( X ) \mathcal{P}(X) P(X)代表 X X X上所有概率测度构成的空间。
问题1(Monge问题或最优传输问题)给定两个概率测度 μ ∈ P ( X ) \mu \in \mathcal{P}(X) μ∈P(X), ν ∈ P ( Y ) \nu \in \mathcal{P}(Y) ν∈P(Y)和一个代价函数 c c c: X × Y → [ 0 , + ∞ ] X \times Y \rightarrow [0,+\infty] X×Y→[0,+∞],求 ( M P ) inf { M ( T ) : = ∫ X c ( x , T ( x ) } 1 μ ( x ) : T # μ = ν } , (MP) \inf \left\{M(T):=\int_{X} c(x, T(x)\}_{1} \mu(x): T_{\#} \mu=\nu\right\}, (MP)inf{ M(T):=∫Xc(x,T(x)}1μ(x):T#μ=ν},
其中由映射 T T T诱导的推前测度 T # μ T_{\#} \mu T#μ定义为:
( T # μ ) ( A ) : = μ ( T − 1 ( A ) ) \left(T_{\#} \mu\right)(A):=\mu\left(T^{-1}(A)\right) (T#μ)(A):=μ(T−1(A))
这里 A ⊂ X A \subset X A⊂X是任意可测集合,映射空间
Σ ( μ , ν ) : = { T : X → Y ∣ T # μ = ν } \Sigma(\mu, \nu):=\left\{T: X \rightarrow Y \mid T_{\#} \mu=\nu\right\} Σ(μ,ν):={ T:X→Y∣T#μ=ν}
如下图示,Monge问题其实是在找一个最优传输映射 T T T,映射 T T T将空间 X X X映射为空间 Y Y Y, A A A是空间 Y Y Y中的区域, T − 1 ( A ) T^{-1}(A) T−1(A)是 A A A在 X X X中原像。需要满足的条件是对于 X X X空间中区域 T − 1 ( A ) T^{-1}(A) T−1(A)的测度要与 Y Y Y空间中区域 A A A的测度要相等。根据下图通俗易懂的理解是面积 T − 1 ( A ) T^{-1}(A) T−1(A)在 X X X 中的占比与面积 A A A 在 Y Y Y中的相等。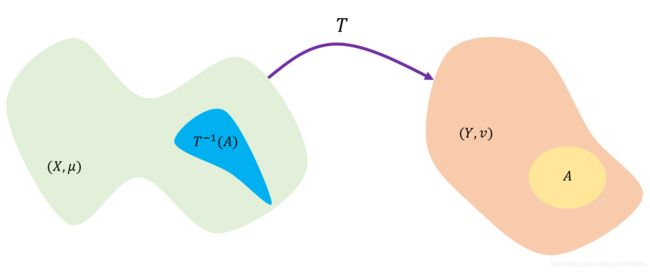
Kantorovich问题(最优传输方案)
对于Monge问题,由于需要求解一个映射,实际上只能允许多对一或者一对一(映射的定义),Kantorovich
将传输映射放松成传输方案,允许一对多,从而将原来问题进行简化。]{}假定有一个联合概率分布 γ ∈ P ( X × Y ) \gamma \in \mathcal{P}(X \times Y) γ∈P(X×Y),其边际概率分布分别等于 μ \mu μ
和 ν \nu ν, ( π x ) # γ = μ \left(\pi_{x}\right)_{\#} \gamma=\mu (πx)#γ=μ, ( π y ) # γ = ν \left(\pi_{y}\right)_{\#} \gamma=\nu (πy)#γ=ν,这里 π x : X × Y → X \pi_{x}: X \times Y \rightarrow X πx:X×Y→X
和 π y : X × Y → Y \pi_{y}: X \times Y \rightarrow Y πy:X×Y→Y是投影映射: π x ( x , y ) = x , π y ( x , y ) = y \pi_{x}(x, y)=x, \quad \pi_{y}(x, y)=y πx(x,y)=x,πy(x,y)=y。
问题2(Kantorovich问题或最优传输方案问题)给定两个概率测度 μ ∈ P ( X ) \mu \in \mathcal{P}(X) μ∈P(X), ν ∈ P ( Y ) \nu \in \mathcal{P}(Y) ν∈P(Y)和一个代价函数 c c c: X × Y → [ 0 , + ∞ ] X \times Y \rightarrow [0,+\infty] X×Y→[0,+∞],求解
( K P ) inf { K ( γ ) : = ∫ X × Y c ( x , y ) d γ ( x , y ) : γ ∈ Π ( μ , ν ) } , (K P) \quad \inf \left\{K(\gamma):=\int_{X \times Y} c(x, y) d \gamma(x, y): \gamma \in \Pi(\mu, \nu)\right\}, (KP)inf{ K(γ):=∫X×Yc(x,y)dγ(x,y):γ∈Π(μ,ν)},
其中联合概率测度 γ \gamma γ属于传输方案空间
Π ( μ , ν ) : = { γ ∈ P ( X × Y ) : ( π x ) # γ = μ , ( π y ) # γ = ν } . \Pi(\mu, \nu):=\left\{\gamma \in \mathcal{P}(X \times Y):\left(\pi_{x}\right)_{\#} \gamma=\mu,\left(\pi_{y}\right)_{\#} \gamma=\nu\right\} . Π(μ,ν):={ γ∈P(X×Y):(πx)#γ=μ,(πy)#γ=ν}.
如果一个最优传输映射为 T : X × Y T: X \times Y T:X×Y,则最优传输方案 γ \gamma γ有如下形式:
γ = ( i d , T ) # μ \gamma=(i d, T)_{\#} \mu γ=(id,T)#μ
给定离散的 μ \mu μ和 ν \nu ν,可能不存在任何传输映射:
μ = δ ( x − x 0 ) , ν = 1 n ∑ i = 1 n δ ( y − y i ) \mu=\delta\left(x-x_{0}\right), \quad \nu=\frac{1}{n} \sum_{i=1}^{n} \delta\left(y-y_{i}\right) μ=δ(x−x0),ν=n1i=1∑nδ(y−yi)
但传输方案总是存在的,例如 μ ⊗ ν ∈ Π ( μ , ν ) \mu \otimes \nu \in \Pi(\mu, \nu) μ⊗ν∈Π(μ,ν)。所以说Kantorovich问题是Monge问题的一个弱化和放松。如下图所示,图中左半部分是映射,映射的要求是 X X X空间中的元素有且只有一个 Y Y Y空间中的元素与之对应。图中的有右半部分是方案,方案可以是多多的形式。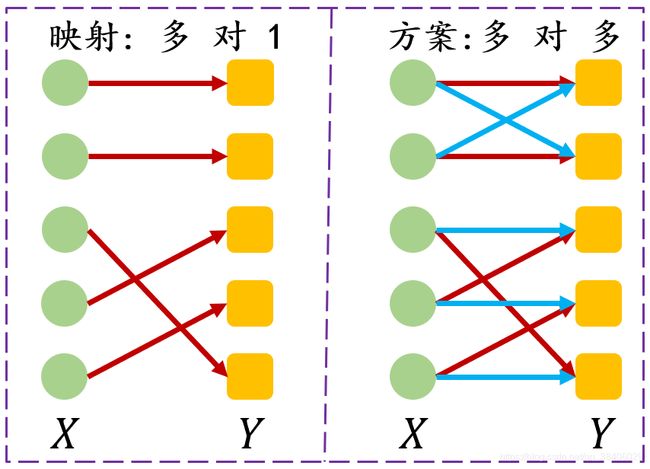
Wassertein距离
Wassertein距离定义
在深度学习中利用最优传输代价作为统计散度来反应两个概率密度之间的离散程度。主要用来表示两个概率分布的不相似程度,类似的统计散度有比较知名的KL散度,JS散度,还有一种度量概率分布很好方式就是利用Wassertein距离。如果将Section 3的Kantorovich问题的公式(2)里的代价函数 c ( x , y ) c(x,y) c(x,y)换成欧式距离: c ( x , y ) = ∥ x − y ∥ 2 2 c(x, y)=\|x-y\|_{2}^{2} c(x,y)=∥x−y∥22 就得到了2-Wassertein距离: ( W D − 2 ) inf { K ( γ ) : = ∫ X × Y ∥ x − y ∥ 2 2 d γ ( x , y ) : γ ∈ Π ( μ , ν ) } , (WD-2) \quad \inf \left\{K(\gamma):=\int_{X \times Y}\|x-y\|_{2}^{2} d \gamma(x, y): \gamma \in \Pi(\mu, \nu)\right\}, (WD−2)inf{ K(γ):=∫X×Y∥x−y∥22dγ(x,y):γ∈Π(μ,ν)},
类似的,对于任意正整数 k k k,k-Wasserstein距离可以定义为: ( W D − k ) inf { K ( γ ) : = ∫ X × Y ∥ x − y ∥ k k d γ ( x , y ) : γ ∈ Π ( μ , ν ) } , (WD-k) \quad \inf \left\{K(\gamma):=\int_{X \times Y}\|x-y\|_{k}^{k} d \gamma(x, y): \gamma \in \Pi(\mu, \nu)\right\}, (WD−k)inf{ K(γ):=∫X×Y∥x−y∥kkdγ(x,y):γ∈Π(μ,ν)},
其中, ∥ ∥ k k \|\|_{k}^{k} ∥∥kk是 L k L_{k} Lk范数,即 L k = ∑ i = 1 n x i k k L_{k}=\sqrt[k]{\sum_{i=1}^{n} x_{i}^{k}} Lk=k∑i=1nxik, x = ( x 1 , x 2 , ⋯ , x n ) \mathbf{x}=\left(x_{1}, x_{2}, \cdots, x_{n}\right) x=(x1,x2,⋯,xn)。
我们最熟知的推土机距离(Earth-Mover)为1-Wassertein距离: ( W D − 1 ) inf { K ( γ ) : = ∫ X × Y ∥ x − y ∥ 1 1 d γ ( x , y ) : γ ∈ Π ( μ , ν ) } , (WD-1) \quad \inf \left\{K(\gamma):=\int_{X \times Y}\|x-y\|_{1}^{1} d \gamma(x, y): \gamma \in \Pi(\mu, \nu)\right\}, (WD−1)inf{ K(γ):=∫X×Y∥x−y∥11dγ(x,y):γ∈Π(μ,ν)},将公式(5)写成期望的形式为: W ( P r , P g ) = inf γ ∈ Π ( P r , P g ) E ( x , y ) ∼ γ [ ∥ x − y ∥ ] W\left(\mathbb{P}_{r}, \mathbb{P}_{g}\right)=\inf _{\gamma \in \Pi\left(\mathbb{P}_{r}, \mathbb{P}_{g}\right)} \mathbb{E}_{(x, y) \sim \gamma}[\|x-y\|] W(Pr,Pg)=γ∈Π(Pr,Pg)infE(x,y)∼γ[∥x−y∥]其中 Π ( P r , P g ) \Pi\left(\mathbb{P}_{r}, \mathbb{P}_{g}\right) Π(Pr,Pg)表示边缘分布 P r \mathbb{P}_{r} Pr和 P g \mathbb{P}_{g} Pg的所有联合分布 γ ( x , y ) \gamma(x, y) γ(x,y)的集喝。 γ ( x , y ) \gamma(x, y) γ(x,y)可以理解为将分布 P r \mathbb{P}_{r} Pr转换成分布 P g \mathbb{P}_{g} Pg所消耗的成本的方案。
我们熟知的WGAN的对抗目标损失其实是公式(6)的对偶形式,具体公式如下所示:
W ( P r , P θ ) = sup ∥ f ∥ L ≤ 1 E x ∼ P r [ f ( x ) ] − E x ∼ P θ [ f ( x ) ] W\left(\mathbb{P}_{r}, \mathbb{P}_{\theta}\right)=\sup _{\|f\|_{L} \leq 1} \mathbb{E}_{x \sim \mathbb{P}_{r}}[f(x)]-\mathbb{E}_{x \sim \mathbb{P}_{\theta}}[f(x)] W(Pr,Pθ)=∥f∥L≤1supEx∼Pr[f(x)]−Ex∼Pθ[f(x)]
其中上确界在所有1-Lipschitz f : X → R f: \mathcal{X} \rightarrow \mathbb{R} f:X→R的上面。如果将 ∥ f ∥ L ≤ 1 \|f\|_{L} \leq 1 ∥f∥L≤1替换为 ∥ f ∥ L ≤ K \|f\|_{L} \leq K ∥f∥L≤K,则会有一个参数化的函数 { f w } w ∈ W \left\{f_{w}\right\}_{w \in \mathcal{W}} { fw}w∈W,进而可以求解问题:
max w ∈ W E x ∼ P r [ f w ( x ) ] − E z ∼ p ( z ) [ f w ( g θ ( z ) ] \max _{w \in \mathcal{W}} \mathbb{E}_{x \sim \mathbb{P}_{r}}\left[f_{w}(x)\right]-\mathbb{E}_{z \sim p(z)}\left[f_{w}\left(g_{\theta}(z)\right]\right. w∈WmaxEx∼Pr[fw(x)]−Ez∼p(z)[fw(gθ(z)]
其中, w w w为神经网络的参数。
Wassertein距离连续性
Wassertein距离衡量分布的一个最大的好处就在于它距离度量的连续性。
证明:假定 θ \theta θ和 θ ′ \theta^{\prime} θ′是 R d \mathbb{R}^{d} Rd中的两个参数向量,其中联合的分布 ( g θ ( Z ) , g θ ′ ( Z ) ) \left(g_{\theta}(Z), g_{\theta^{\prime}}(Z)\right) (gθ(Z),gθ′(Z))的集合为
γ ∈ Π ( P θ , P θ ′ ) \gamma \in \Pi\left(\mathbb{P}_{\theta}, \mathbb{P}_{\theta^{\prime}}\right) γ∈Π(Pθ,Pθ′)。由公式(6)的Wassertein距离的定义可知: W ( P θ , P θ ′ ) ≤ ∫ X × X ∥ x − y ∥ d γ = E ( x , y ) ∼ γ [ ∥ x − y ∥ ] = E z [ ∥ g θ ( z ) − g θ ′ ( z ) ∥ ] \begin{aligned} W\left(\mathbb{P}_{\theta}, \mathbb{P}_{\theta^{\prime}}\right) & \leq \int_{\mathcal{X} \times \mathcal{X}}\|x-y\| \mathrm{d} \gamma \\ &=\mathbb{E}_{(x, y) \sim \gamma}[\|x-y\|] \\ &=\mathbb{E}_{z}\left[\left\|g_{\theta}(z)-g_{\theta^{\prime}}(z)\right\|\right] \end{aligned} W(Pθ,Pθ′)≤∫X×X∥x−y∥dγ=E(x,y)∼γ[∥x−y∥]=Ez[∥gθ(z)−gθ′(z)∥]
如果 g g g在 θ \theta θ中是连续的,那么 g θ ( z ) → θ → θ ′ g θ ′ ( z ) g_{\theta}(z) \rightarrow_{\theta \rightarrow \theta^{\prime}} g_{\theta^{\prime}}(z) gθ(z)→θ→θ′gθ′(z),则有 ∥ g θ − g θ ′ ∥ → 0 \left\|g_{\theta}-g_{\theta^{\prime}}\right\| \rightarrow 0 ∥gθ−gθ′∥→0,由于 X \mathcal{X} X是紧的,其中任意两个元素的距离必须由某个常数 M M M一致有界,因此对于所有 θ \theta θ和 z z z, ∥ g θ ( z ) − g θ ′ ( z ) ∥ ≤ M \left\|g_{\theta}(z)-g_{\theta^{\prime}}(z)\right\| \leq M ∥gθ(z)−gθ′(z)∥≤M一致。根据有界收敛定理,则有: W ( P θ , P θ ′ ) ≤ E z [ ∥ g θ ( z ) − g θ ′ ( z ) ∥ ] → θ → θ ′ 0 W\left(\mathbb{P}_{\theta}, \mathbb{P}_{\theta^{\prime}}\right) \leq \mathbb{E}_{z}\left[\left\|g_{\theta}(z)-g_{\theta^{\prime}}(z)\right\|\right] \rightarrow_{\theta \rightarrow \theta^{\prime}} 0 W(Pθ,Pθ′)≤Ez[∥gθ(z)−gθ′(z)∥]→θ→θ′0最终则有: ∣ W ( P r , P θ ) − W ( P r , P θ ′ ) ∣ ≤ W ( P θ , P θ ′ ) → θ → θ ′ 0 \left|W\left(\mathbb{P}_{r}, \mathbb{P}_{\theta}\right)-W\left(\mathbb{P}_{r}, \mathbb{P}_{\theta^{\prime}}\right)\right| \leq W\left(\mathbb{P}_{\theta}, \mathbb{P}_{\theta^{\prime}}\right) \rightarrow_{\theta \rightarrow \theta^{\prime}} 0 ∣W(Pr,Pθ)−W(Pr,Pθ′)∣≤W(Pθ,Pθ′)→θ→θ′0
W ( P r , P θ ) W\left(\mathbb{P}_{r}, \mathbb{P}_{\theta}\right) W(Pr,Pθ)连续性证明完毕。
Wassertein距离实例
如下图所示考虑怎样将下面左图中的(实线)方块区域搬到右图中的(虚线)方块区域中,并且综合所移动距离最短。我们可以把这里的移动距离(或者传输距离)堪称是位置之间的距离差。比如左边的方块1在位置4,如果搬到右边的位置11,那么距离就是7。
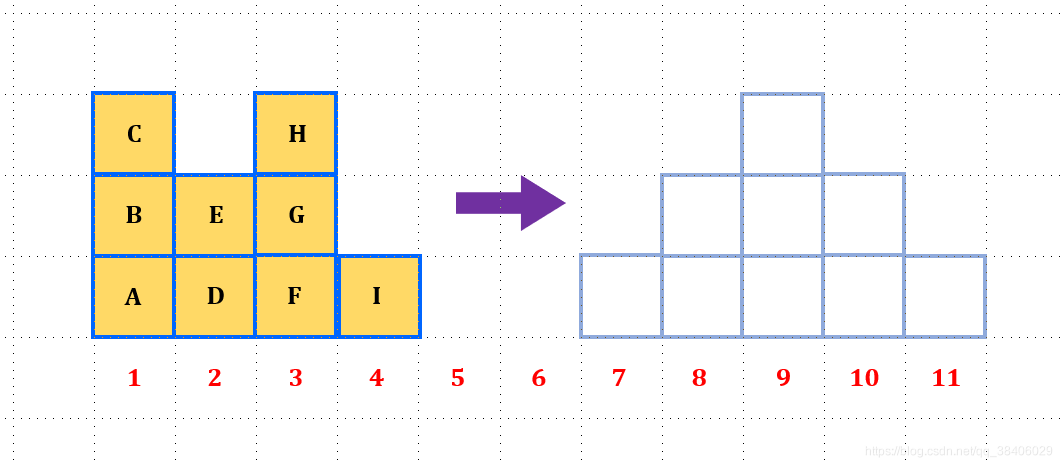
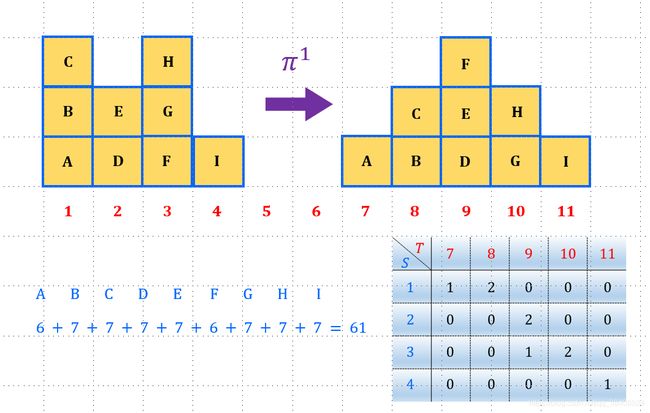
对于上图的问题,我们的一个直观的感受就是有很多种的搬运方块的方案。搬运方案一如下图所示,我们可以把位置1的方块A,放到位置7处,剩下两个方块B和C放到位置8中;位置2处的方块D和E放到位置9处;位置3的方块F放到位置9处,剩下的两个方块H和G放到位置10处;位置4的方块放到位置11处。搬运方案一总体的运输距离为:
6 + 7 + 7 + 7 + 7 + 6 + 7 + 7 + 7 = 61 6+7+7+7+7+6+7+7+7=61 6+7+7+7+7+6+7+7+7=61
搬运方案二如下图所示,我们可以把位置1的方块A,放到位置11处,剩下两个方块B和C放到位置10中;位置2处的方块D和E放到位置9处;位置3的方块H放到位置[9]{}处,剩下的两个方块F和G放到位置8处;位置4的方块放到位置7处。搬运方案二总体的运输距离为:
10 + 9 + 9 + 7 + 7 + 6 + 5 + 5 + 3 = 61 10+9+9+7+7+6+5+5+3=61 10+9+9+7+7+6+5+5+3=61
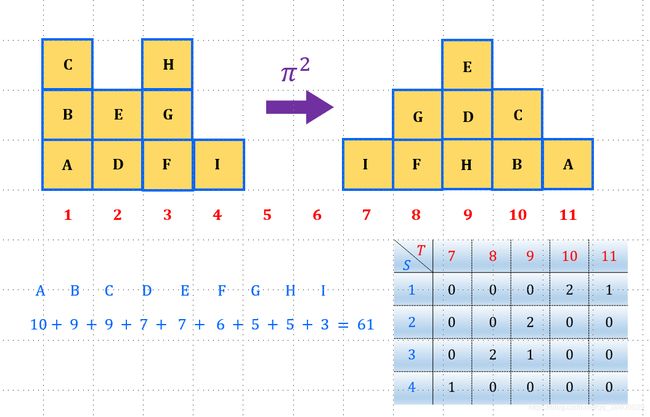
上面两种运输方案的运输距离是一样的,运输方案不一样,距离也会不一样。不同的运输方案也会有不同的距离。最优传输方案就是遍历所有的传输方案找出传输代价最小的传输方案。