http://qindongliang.iteye.com/blog/2212619
先来看下hue的架构图: 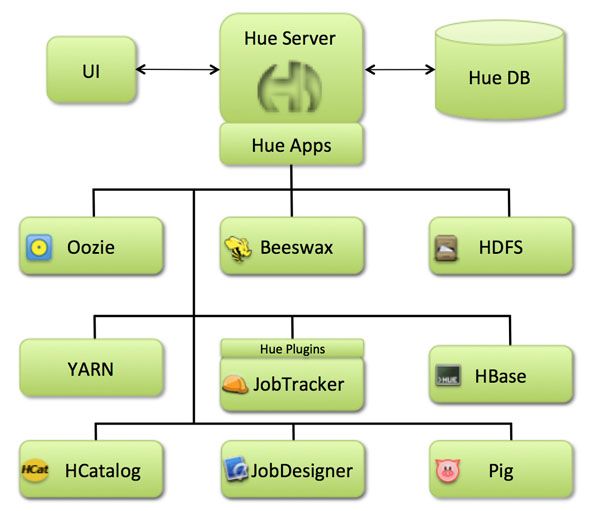
(1)Hue是什么?
Hue是一个可快速开发和调试Hadoop生态系统各种应用的一个基于浏览器的图形化用户接口。
(2)Hue能干什么?
1,访问HDFS和文件浏览
2,通过web调试和开发hive以及数据结果展示
3,查询solr和结果展示,报表生成
4,通过web调试和开发impala交互式SQL Query
5,spark调试和开发
6,Pig开发和调试
7,oozie任务的开发,监控,和工作流协调调度
8,Hbase数据查询和修改,数据展示
9,Hive的元数据(metastore)查询
10,MapReduce任务进度查看,日志追踪
11,创建和提交MapReduce,Streaming,Java job任务
12,Sqoop2的开发和调试
13,Zookeeper的浏览和编辑
14,数据库(MySQL,PostGres,SQlite,Oracle)的查询和展示
(3)Hue怎么用或者什么时候应该用?
如果你们公司用的是CDH的hadoop,那么很幸运,Hue也是出自CDH公司,自家的东西用起来当然很爽。
如果你们公司用的是Apache Hadoop或者是HDP的hadoop,那么也没事,Hue是开源的,而且支持任何版本的hadoop。
关于什么时候用,这纯属一个锦上添花的功能,你完全可以不用hue,因为各种开源项目都有自己的使用方式和开发接口,hue只不过是统一了各个项目的开发方式在一个接口里而已,这样比较方便而已,不用你一会准备使用hive,就开一个hive的cli终端,一会用pig,你就得开一个pig的grunt,或者你又想查Hbase,又得需要开一个Hbase的shell终端。如果你们使用hadoop生态系统的组件很多的情况下,使用hue还是比较方便的,另外一个好处就是hue提供了一个web的界面来开发和调试任务,不用我们再频繁登陆Linux来操作了。
你可以在任何时候,只要能上网,就可以通过hue来开发和调试数据,不用再装Linux的客户端来远程登陆操作了,这也是B/S架构的好处。
(4)如何下载,安装和编译Hue?
centos系统,执行命令:
yum install -y asciidoc cyrus-sasl-devel cyrus-sasl-gssapi gcc gcc-c++ krb5-devel libtidy libxml2-devel libxslt-devel make mysql mysql-devel openldap-devel python-devel sqlite-devel openssl-devel gmp-devel
1,hue的依赖(centos系统)

- ant
- asciidoc
- cyrus-sasl-devel
- cyrus-sasl-gssapi
- gcc
- gcc-c++
- krb5-devel
- libtidy (for unit tests only)
- libxml2-devel
- libxslt-devel
- make
- mvn (from maven package or maven3 tarball)
- mysql
- mysql-devel
- openldap-devel
- python-devel
- sqlite-devel
- openssl-devel (for version 7+)
2,散仙的在安装hue前,centos上已经安装好了,jdk,maven,ant,hadoop,hive,oozie等,环境变量如下:
- user="search"
- # java
- export JAVA_HOME="/usr/local/jdk"
- export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
- export PATH=$PATH:$JAVA_HOME/bin
- # ant
- export ANT_HOME=/usr/local/ant
- export CLASSPATH=$CLASSPATH:$ANT_HOME/lib
- export PATH=$PATH:$ANT_HOME/bin
- # maven
- export MAVEN_HOME="/usr/local/maven"
- export CLASSPATH=$CLASSPATH:$MAVEN_HOME/lib
- export PATH=$PATH:$MAVEN_HOME/bin
- ##Hadoop2.2的变量设置
- export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- export HADOOP_HOME=/home/search/hadoop
- export HADOOP_MAPRED_HOME=$HADOOP_HOME
- export HADOOP_COMMON_HOME=$HADOOP_HOME
- export HADOOP_HDFS_HOME=$HADOOP_HOME
- export YARN_HOME=$HADOOP_HOME
- export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
- export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
- export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- export CLASSPATH=.:$CLASSPATH:$HADOOP_COMMON_HOME:$HADOOP_COMMON_HOMEi/lib:$HADOOP_MAPRED_HOME:$HADOOP_HDFS_HOME:$HADOOP_HDFS_HOME
- # Hive
- export HIVE_HOME=/home/search/hive
- export HIVE_CONF_DIR=/home/search/hive/conf
- export CLASSPATH=$CLASSPATH:$HIVE_HOME/lib
- export PATH=$PATH:$HIVE_HOME/bin:$HIVE_HOME/conf
- export OOZIE_HOME="/home/search/oozie-4.1.0"
- export PATH=$PATH:$OOZIE_HOME/sbin:$OOZIE_HOME/bin
3,本文散仙主要是采用tar包的方式安装hue,除了tar包的方式,hue还能采用cm安装,当然这就与cdh的系统依赖比较大了。
hue最新的版本是3.8.1,散仙这里用的3.7.0的版本
下载地址:https://github.com/cloudera/hue/releases
hue的github地址:https://github.com/cloudera/hue
4,下载完后,解压tar包,并进入hue的根目录执行命令
make apps编译
5,编译成功后,需要配置/home/search/hue/desktop/conf/pseudo-distributed.ini文件,里面包含了hdfs,yarn,mapreduce,hive,oozie,pig,spark,solr等的ip地址和端口号配置,可根据自己的情况设置,如果没有安装某个应用,那就无须配置,只不过这个应用在web上不能使用而已,并不会影响其他框架的使用。
一个例子如下:
- #####################################
- # DEVELOPMENT EDITION
- #####################################
- # Hue configuration file
- # ===================================
- #
- # For complete documentation about the contents of this file, run
- # $
/build/env/bin/hue config_help - #
- # All .ini files under the current directory are treated equally. Their
- # contents are merged to form the Hue configuration, which can
- # can be viewed on the Hue at
- # http://
: /dump_config - ###########################################################################
- # General configuration for core Desktop features (authentication, etc)
- ###########################################################################
- [desktop]
- send_dbug_messages=1
- # To show database transactions, set database_logging to 1
- database_logging=0
- # Set this to a random string, the longer the better.
- # This is used for secure hashing in the session store.
- secret_key=search
- # Webserver listens on this address and port
- http_host=0.0.0.0
- http_port=8000
- # Time zone name
- time_zone=Asia/Shanghai
- # Enable or disable Django debug mode
- ## django_debug_mode=true
- # Enable or disable backtrace for server error
- ## http_500_debug_mode=true
- # Enable or disable memory profiling.
- ## memory_profiler=false
- # Server email for internal error messages
- ## django_server_email='[email protected]'
- # Email backend
- ## django_email_backend=django.core.mail.backends.smtp.EmailBackend
- # Webserver runs as this user
- server_user=search
- server_group=search
- # This should be the Hue admin and proxy user
- default_user=search
- # This should be the hadoop cluster admin
- default_hdfs_superuser=search
- # If set to false, runcpserver will not actually start the web server.
- # Used if Apache is being used as a WSGI container.
- ## enable_server=yes
- # Number of threads used by the CherryPy web server
- ## cherrypy_server_threads=10
- # Filename of SSL Certificate
- ## ssl_certificate=
- # Filename of SSL RSA Private Key
- ## ssl_private_key=
- # List of allowed and disallowed ciphers in cipher list format.
- # See http://www.openssl.org/docs/apps/ciphers.html for more information on cipher list format.
- ## ssl_cipher_list=DEFAULT:!aNULL:!eNULL:!LOW:!EXPORT:!SSLv2
- # LDAP username and password of the hue user used for LDAP authentications.
- # Set it to use LDAP Authentication with HiveServer2 and Impala.
- ## ldap_username=hue
- ## ldap_password=
- # Default encoding for site data
- ## default_site_encoding=utf-8
- # Help improve Hue with anonymous usage analytics.
- # Use Google Analytics to see how many times an application or specific section of an application is used, nothing more.
- ## collect_usage=true
- # Support for HTTPS termination at the load-balancer level with SECURE_PROXY_SSL_HEADER.
- ## secure_proxy_ssl_header=false
- # Comma-separated list of Django middleware classes to use.
- # See https://docs.djangoproject.com/en/1.4/ref/middleware/ for more details on middlewares in Django.
- ## middleware=desktop.auth.backend.LdapSynchronizationBackend
- # Comma-separated list of regular expressions, which match the redirect URL.
- # For example, to restrict to your local domain and FQDN, the following value can be used:
- # ^\/.*$,^http:\/\/www.mydomain.com\/.*$
- ## redirect_whitelist=
- # Comma separated list of apps to not load at server startup.
- # e.g.: pig,zookeeper
- ## app_blacklist=
- # The directory where to store the auditing logs. Auditing is disable if the value is empty.
- # e.g. /var/log/hue/audit.log
- ## audit_event_log_dir=
- # Size in KB/MB/GB for audit log to rollover.
- ## audit_log_max_file_size=100MB
- #poll_enabled=false
- # Administrators
- # ----------------
- [[django_admins]]
- ## [[[admin1]]]
- ## name=john
- ## email=john@doe.com
- # UI customizations
- # -------------------
- [[custom]]
- # Top banner HTML code
- #banner_top_html=Search Team Hadoop Manager
- # Configuration options for user authentication into the web application
- # ------------------------------------------------------------------------
- [[auth]]
- # Authentication backend. Common settings are:
- # - django.contrib.auth.backends.ModelBackend (entirely Django backend)
- # - desktop.auth.backend.AllowAllBackend (allows everyone)
- # - desktop.auth.backend.AllowFirstUserDjangoBackend
- # (Default. Relies on Django and user manager, after the first login)
- # - desktop.auth.backend.LdapBackend
- # - desktop.auth.backend.PamBackend
- # - desktop.auth.backend.SpnegoDjangoBackend
- # - desktop.auth.backend.RemoteUserDjangoBackend
- # - libsaml.backend.SAML2Backend
- # - libopenid.backend.OpenIDBackend
- # - liboauth.backend.OAuthBackend
- # (New oauth, support Twitter, Facebook, Google+ and Linkedin
- ## backend=desktop.auth.backend.AllowFirstUserDjangoBackend
- # The service to use when querying PAM.
- ## pam_service=login
- # When using the desktop.auth.backend.RemoteUserDjangoBackend, this sets
- # the normalized name of the header that contains the remote user.
- # The HTTP header in the request is converted to a key by converting
- # all characters to uppercase, replacing any hyphens with underscores
- # and adding an HTTP_ prefix to the name. So, for example, if the header
- # is called Remote-User that would be configured as HTTP_REMOTE_USER
- #
- # Defaults to HTTP_REMOTE_USER
- ## remote_user_header=HTTP_REMOTE_USER
- # Ignore the case of usernames when searching for existing users.
- # Only supported in remoteUserDjangoBackend.
- ## ignore_username_case=false
- # Ignore the case of usernames when searching for existing users to authenticate with.
- # Only supported in remoteUserDjangoBackend.
- ## force_username_lowercase=false
- # Users will expire after they have not logged in for 'n' amount of seconds.
- # A negative number means that users will never expire.
- ## expires_after=-1
- # Apply 'expires_after' to superusers.
- ## expire_superusers=true
- # Configuration options for connecting to LDAP and Active Directory
- # -------------------------------------------------------------------
- [[ldap]]
- # The search base for finding users and groups
- ## base_dn="DC=mycompany,DC=com"
- # URL of the LDAP server
- ## ldap_url=ldap://auth.mycompany.com
- # A PEM-format file containing certificates for the CA's that
- # Hue will trust for authentication over TLS.
- # The certificate for the CA that signed the
- # LDAP server certificate must be included among these certificates.
- # See more here http://www.openldap.org/doc/admin24/tls.html.
- ## ldap_cert=
- ## use_start_tls=true
- # Distinguished name of the user to bind as -- not necessary if the LDAP server
- # supports anonymous searches
- ## bind_dn="CN=ServiceAccount,DC=mycompany,DC=com"
- # Password of the bind user -- not necessary if the LDAP server supports
- # anonymous searches
- ## bind_password=
- # Pattern for searching for usernames -- Use
for the parameter - # For use when using LdapBackend for Hue authentication
- ## ldap_username_pattern="uid=
,ou=People,dc=mycompany,dc=com" - # Create users in Hue when they try to login with their LDAP credentials
- # For use when using LdapBackend for Hue authentication
- ## create_users_on_login = true
- # Synchronize a users groups when they login
- ## sync_groups_on_login=false
- # Ignore the case of usernames when searching for existing users in Hue.
- ## ignore_username_case=false
- # Force usernames to lowercase when creating new users from LDAP.
- ## force_username_lowercase=false
- # Use search bind authentication.
- ## search_bind_authentication=true
- # Choose which kind of subgrouping to use: nested or suboordinate (deprecated).
- ## subgroups=suboordinate
- # Define the number of levels to search for nested members.
- ## nested_members_search_depth=10
- [[[users]]]
- # Base filter for searching for users
- ## user_filter="objectclass=*"
- # The username attribute in the LDAP schema
- ## user_name_attr=sAMAccountName
- [[[groups]]]
- # Base filter for searching for groups
- ## group_filter="objectclass=*"
- # The username attribute in the LDAP schema
- ## group_name_attr=cn
- [[[ldap_servers]]]
- ## [[[[mycompany]]]]
- # The search base for finding users and groups
- ## base_dn="DC=mycompany,DC=com"
- # URL of the LDAP server
- ## ldap_url=ldap://auth.mycompany.com
- # A PEM-format file containing certificates for the CA's that
- # Hue will trust for authentication over TLS.
- # The certificate for the CA that signed the
- # LDAP server certificate must be included among these certificates.
- # See more here http://www.openldap.org/doc/admin24/tls.html.
- ## ldap_cert=
- ## use_start_tls=true
- # Distinguished name of the user to bind as -- not necessary if the LDAP server
- # supports anonymous searches
- ## bind_dn="CN=ServiceAccount,DC=mycompany,DC=com"
- # Password of the bind user -- not necessary if the LDAP server supports
- # anonymous searches
- ## bind_password=
- # Pattern for searching for usernames -- Use
for the parameter - # For use when using LdapBackend for Hue authentication
- ## ldap_username_pattern="uid=
,ou=People,dc=mycompany,dc=com" - ## Use search bind authentication.
- ## search_bind_authentication=true
- ## [[[[[users]]]]]
- # Base filter for searching for users
- ## user_filter="objectclass=Person"
- # The username attribute in the LDAP schema
- ## user_name_attr=sAMAccountName
- ## [[[[[groups]]]]]
- # Base filter for searching for groups
- ## group_filter="objectclass=groupOfNames"
- # The username attribute in the LDAP schema
- ## group_name_attr=cn
- # Configuration options for specifying the Desktop Database. For more info,
- # see http://docs.djangoproject.com/en/1.4/ref/settings/#database-engine
- # ------------------------------------------------------------------------
- [[database]]
- # Database engine is typically one of:
- # postgresql_psycopg2, mysql, sqlite3 or oracle.
- #
- # Note that for sqlite3, 'name', below is a a path to the filename. For other backends, it is the database name.
- # Note for Oracle, options={ 'threaded':true} must be set in order to avoid crashes.
- # Note for Oracle, you can use the Oracle Service Name by setting "port=0" and then "name=
: / ". - ## engine=sqlite3
- ## host=
- ## port=
- ## user=
- ## password=
- ## name=desktop/desktop.db
- ## options={}
- # Configuration options for specifying the Desktop session.
- # For more info, see https://docs.djangoproject.com/en/1.4/topics/http/sessions/
- # ------------------------------------------------------------------------
- [[session]]
- # The cookie containing the users' session ID will expire after this amount of time in seconds.
- # Default is 2 weeks.
- ## ttl=1209600
- # The cookie containing the users' session ID will be secure.
- # Should only be enabled with HTTPS.
- ## secure=false
- # The cookie containing the users' session ID will use the HTTP only flag.
- ## http_only=false
- # Use session-length cookies. Logs out the user when she closes the browser window.
- ## expire_at_browser_close=false
- # Configuration options for connecting to an external SMTP server
- # ------------------------------------------------------------------------
- [[smtp]]
- # The SMTP server information for email notification delivery
- host=localhost
- port=25
- user=
- password=
- # Whether to use a TLS (secure) connection when talking to the SMTP server
- tls=no
- # Default email address to use for various automated notification from Hue
- ## default_from_email=hue@localhost
- # Configuration options for Kerberos integration for secured Hadoop clusters
- # ------------------------------------------------------------------------
- [[kerberos]]
- # Path to Hue's Kerberos keytab file
- ## hue_keytab=
- # Kerberos principal name for Hue
- ## hue_principal=hue/hostname.foo.com
- # Path to kinit
- ## kinit_path=/path/to/kinit
- # Configuration options for using OAuthBackend (Core) login
- # ------------------------------------------------------------------------
- [[oauth]]
- # The Consumer key of the application
- ## consumer_key=XXXXXXXXXXXXXXXXXXXXX
- # The Consumer secret of the application
- ## consumer_secret=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
- # The Request token URL
- ## request_token_url=https://api.twitter.com/oauth/request_token
- # The Access token URL
- ## access_token_url=https://api.twitter.com/oauth/access_token
- # The Authorize URL
- ## authenticate_url=https://api.twitter.com/oauth/authorize
- ###########################################################################
- # Settings to configure SAML
- ###########################################################################
- [libsaml]
- # Xmlsec1 binary path. This program should be executable by the user running Hue.
- ## xmlsec_binary=/usr/local/bin/xmlsec1
- # Entity ID for Hue acting as service provider.
- # Can also accept a pattern where '
' will be replaced with server URL base. - ## entity_id="
/saml2/metadata/" - # Create users from SSO on login.
- ## create_users_on_login=true
- # Required attributes to ask for from IdP.
- # This requires a comma separated list.
- ## required_attributes=uid
- # Optional attributes to ask for from IdP.
- # This requires a comma separated list.
- ## optional_attributes=
- # IdP metadata in the form of a file. This is generally an XML file containing metadata that the Identity Provider generates.
- ## metadata_file=
- # Private key to encrypt metadata with.
- ## key_file=
- # Signed certificate to send along with encrypted metadata.
- ## cert_file=
- # A mapping from attributes in the response from the IdP to django user attributes.
- ## user_attribute_mapping={ 'uid':'username'}
- # Have Hue initiated authn requests be signed and provide a certificate.
- ## authn_requests_signed=false
- # Have Hue initiated logout requests be signed and provide a certificate.
- ## logout_requests_signed=false
- # Username can be sourced from 'attributes' or 'nameid'.
- ## username_source=attributes
- # Performs the logout or not.
- ## logout_enabled=true
- ###########################################################################
- # Settings to configure OpenId
- ###########################################################################
- [libopenid]
- # (Required) OpenId SSO endpoint url.
- ## server_endpoint_url=https://www.google.com/accounts/o8/id
- # OpenId 1.1 identity url prefix to be used instead of SSO endpoint url
- # This is only supported if you are using an OpenId 1.1 endpoint
- ## identity_url_prefix=https://app.onelogin.com/openid/your_company.com/
- # Create users from OPENID on login.
- ## create_users_on_login=true
- # Use email for username
- ## use_email_for_username=true
- ###########################################################################
- # Settings to configure OAuth
- ###########################################################################
- [liboauth]
- # NOTE:
- # To work, each of the active (i.e. uncommented) service must have
- # applications created on the social network.
- # Then the "consumer key" and "consumer secret" must be provided here.
- #
- # The addresses where to do so are:
- # Twitter: https://dev.twitter.com/apps
- # Google+ : https://cloud.google.com/
- # Facebook: https://developers.facebook.com/apps
- # Linkedin: https://www.linkedin.com/secure/developer
- #
- # Additionnaly, the following must be set in the application settings:
- # Twitter: Callback URL (aka Redirect URL) must be set to http://YOUR_HUE_IP_OR_DOMAIN_NAME/oauth/social_login/oauth_authenticated
- # Google+ : CONSENT SCREEN must have email address
- # Facebook: Sandbox Mode must be DISABLED
- # Linkedin: "In OAuth User Agreement", r_emailaddress is REQUIRED
- # The Consumer key of the application
- ## consumer_key_twitter=
- ## consumer_key_google=
- ## consumer_key_facebook=
- ## consumer_key_linkedin=
- # The Consumer secret of the application
- ## consumer_secret_twitter=
- ## consumer_secret_google=
- ## consumer_secret_facebook=
- ## consumer_secret_linkedin=
- # The Request token URL
- ## request_token_url_twitter=https://api.twitter.com/oauth/request_token
- ## request_token_url_google=https://accounts.google.com/o/oauth2/auth
- ## request_token_url_linkedin=https://www.linkedin.com/uas/oauth2/authorization
- ## request_token_url_facebook=https://graph.facebook.com/oauth/authorize
- # The Access token URL
- ## access_token_url_twitter=https://api.twitter.com/oauth/access_token
- ## access_token_url_google=https://accounts.google.com/o/oauth2/token
- ## access_token_url_facebook=https://graph.facebook.com/oauth/access_token
- ## access_token_url_linkedin=https://api.linkedin.com/uas/oauth2/accessToken
- # The Authenticate URL
- ## authenticate_url_twitter=https://api.twitter.com/oauth/authorize
- ## authenticate_url_google=https://www.googleapis.com/oauth2/v1/userinfo?access_token=
- ## authenticate_url_facebook=https://graph.facebook.com/me?access_token=
- ## authenticate_url_linkedin=https://api.linkedin.com/v1/people/~:(email-address)?format=json&oauth2_access_token=
- # Username Map. Json Hash format.
- # Replaces username parts in order to simplify usernames obtained
- # Example: { "@sub1.domain.com":"_S1", "@sub2.domain.com":"_S2"}
- # converts '[email protected]' to 'email_S1'
- ## username_map={}
- # Whitelisted domains (only applies to Google OAuth). CSV format.
- ## whitelisted_domains_google=
- ###########################################################################
- # Settings for the RDBMS application
- ###########################################################################
- [librdbms]
- # The RDBMS app can have any number of databases configured in the databases
- # section. A database is known by its section name
- # (IE sqlite, mysql, psql, and oracle in the list below).
- [[databases]]
- # sqlite configuration.
- ## [[[sqlite]]]
- # Name to show in the UI.
- ## nice_name=SQLite
- # For SQLite, name defines the path to the database.
- ## name=/tmp/sqlite.db
- # Database backend to use.
- ## engine=sqlite
- # Database options to send to the server when connecting.
- # https://docs.djangoproject.com/en/1.4/ref/databases/
- ## options={}
- # mysql, oracle, or postgresql configuration.
- ## [[[mysql]]]
- # Name to show in the UI.
- ## nice_name="My SQL DB"
- # For MySQL and PostgreSQL, name is the name of the database.
- # For Oracle, Name is instance of the Oracle server. For express edition
- # this is 'xe' by default.
- ## name=mysqldb
- # Database backend to use. This can be:
- # 1. mysql
- # 2. postgresql
- # 3. oracle
- ## engine=mysql
- # IP or hostname of the database to connect to.
- ## host=localhost
- # Port the database server is listening to. Defaults are:
- # 1. MySQL: 3306
- # 2. PostgreSQL: 5432
- # 3. Oracle Express Edition: 1521
- ## port=3306
- # Username to authenticate with when connecting to the database.
- ## user=example
- # Password matching the username to authenticate with when
- # connecting to the database.
- ## password=example
- # Database options to send to the server when connecting.
- # https://docs.djangoproject.com/en/1.4/ref/databases/
- ## options={}
- ###########################################################################
- # Settings to configure your Hadoop cluster.
- ###########################################################################
- [hadoop]
- # Configuration for HDFS NameNode
- # ------------------------------------------------------------------------
- [[hdfs_clusters]]
- # HA support by using HttpFs
- [[[default]]]
- # Enter the filesystem uri
- fs_defaultfs=hdfs://h1:8020
- # NameNode logical name.
- logical_name=h1
- # Use WebHdfs/HttpFs as the communication mechanism.
- # Domain should be the NameNode or HttpFs host.
- # Default port is 14000 for HttpFs.
- webhdfs_url=http://h1:50070/webhdfs/v1
- # Change this if your HDFS cluster is Kerberos-secured
- security_enabled=false
- # Default umask for file and directory creation, specified in an octal value.
- umask=022
- hadoop_conf_dir=/home/search/hadoop/etc/hadoop
- # Configuration for YARN (MR2)
- # ------------------------------------------------------------------------
- [[yarn_clusters]]
- [[[default]]]
- # Enter the host on which you are running the ResourceManager
- resourcemanager_host=h1
- # The port where the ResourceManager IPC listens on
- resourcemanager_port=8032
- # Whether to submit jobs to this cluster
- submit_to=True
- # Resource Manager logical name (required for HA)
- ## logical_name=
- # Change this if your YARN cluster is Kerberos-secured
- ## security_enabled=false
- # URL of the ResourceManager API
- resourcemanager_api_url=http://h1:8088
- # URL of the ProxyServer API
- proxy_api_url=http://h1:8088
- # URL of the HistoryServer API
- history_server_api_url=http://h1:19888
- # HA support by specifying multiple clusters
- # e.g.
- # [[[ha]]]
- # Resource Manager logical name (required for HA)
- ## logical_name=my-rm-name
- # Configuration for MapReduce (MR1)
- # ------------------------------------------------------------------------
- [[mapred_clusters]]
- [[[default]]]
- # Enter the host on which you are running the Hadoop JobTracker
- jobtracker_host=h1
- # The port where the JobTracker IPC listens on
- #jobtracker_port=8021
- # JobTracker logical name for HA
- ## logical_name=
- # Thrift plug-in port for the JobTracker
- ## thrift_port=9290
- # Whether to submit jobs to this cluster
- submit_to=False
- # Change this if your MapReduce cluster is Kerberos-secured
- ## security_enabled=false
- # HA support by specifying multiple clusters
- # e.g.
- # [[[ha]]]
- # Enter the logical name of the JobTrackers
- # logical_name=my-jt-name
- ###########################################################################
- # Settings to configure the Filebrowser app
- ###########################################################################
- [filebrowser]
- # Location on local filesystem where the uploaded archives are temporary stored.
- ## archive_upload_tempdir=/tmp
- ###########################################################################
- # Settings to configure liboozie
- ###########################################################################
- [liboozie]
- # The URL where the Oozie service runs on. This is required in order for
- # users to submit jobs. Empty value disables the config check.
- ## oozie_url=http://localhost:11000/oozie
- oozie_url=http://h1:11000/oozie
- # Requires FQDN in oozie_url if enabled
- ## security_enabled=false
- # Location on HDFS where the workflows/coordinator are deployed when submitted.
- remote_deployement_dir=/user/hue/oozie/deployments
- ###########################################################################
- # Settings to configure the Oozie app
- ###########################################################################
- [oozie]
- # Location on local FS where the examples are stored.
- local_data_dir=apps/oozie/examples/
- # Location on local FS where the data for the examples is stored.
- ## sample_data_dir=...thirdparty/sample_data
- # Location on HDFS where the oozie examples and workflows are stored.
- remote_data_dir=apps/oozie/workspaces
- # Maximum of Oozie workflows or coodinators to retrieve in one API call.
- oozie_jobs_count=100
- # Use Cron format for defining the frequency of a Coordinator instead of the old frequency number/unit.
- ## enable_cron_scheduling=true
- enable_cron_scheduling=true
- ###########################################################################
- # Settings to configure Beeswax with Hive
- ###########################################################################
- [beeswax]
- # Host where HiveServer2 is running.
- # If Kerberos security is enabled, use fully-qualified domain name (FQDN).
- hive_server_host=h1
- # Port where HiveServer2 Thrift server runs on.
- hive_server_port=10000
- # Hive configuration directory, where hive-site.xml is located
- hive_conf_dir=/home/search/hive/conf
- # Timeout in seconds for thrift calls to Hive service
- server_conn_timeout=120
- # Set a LIMIT clause when browsing a partitioned table.
- # A positive value will be set as the LIMIT. If 0 or negative, do not set any limit.
- browse_partitioned_table_limit=250
- # A limit to the number of rows that can be downloaded from a query.
- # A value of -1 means there will be no limit.
- # A maximum of 65,000 is applied to XLS downloads.
- download_row_limit=1000000
- # Hue will try to close the Hive query when the user leaves the editor page.
- # This will free all the query resources in HiveServer2, but also make its results inaccessible.
- ## close_queries=false
- # Thrift version to use when communicating with HiveServer2
- ## thrift_version=5
- [[ssl]]
- # SSL communication enabled for this server.
- ## enabled=false
- # Path to Certificate Authority certificates.
- ## cacerts=/etc/hue/cacerts.pem
- # Path to the private key file.
- ## key=/etc/hue/key.pem
- # Path to the public certificate file.
- ## cert=/etc/hue/cert.pem
- # Choose whether Hue should validate certificates received from the server.
- ## validate=true
- ###########################################################################
- # Settings to configure Pig
- ###########################################################################
- [pig]
- # Location of piggybank.jar on local filesystem.
- local_sample_dir=/home/search/hue/apps/pig/examples
- # Location piggybank.jar will be copied to in HDFS.
- remote_data_dir=/home/search/pig/examples
- ###########################################################################
- # Settings to configure Sqoop
- ###########################################################################
- [sqoop]
- # For autocompletion, fill out the librdbms section.
- # Sqoop server URL
- server_url=http://h1:12000/sqoop
- ###########################################################################
- # Settings to configure Proxy
- ###########################################################################
- [proxy]
- # Comma-separated list of regular expressions,
- # which match 'host:port' of requested proxy target.
- ## whitelist=(localhost|127\.0\.0\.1):(50030|50070|50060|50075)
- # Comma-separated list of regular expressions,
- # which match any prefix of 'host:port/path' of requested proxy target.
- # This does not support matching GET parameters.
- ## blacklist=
- ###########################################################################
- # Settings to configure Impala
- ###########################################################################
- [impala]
- # Host of the Impala Server (one of the Impalad)
- ## server_host=localhost
- # Port of the Impala Server
- ## server_port=21050
- # Kerberos principal
- ## impala_principal=impala/hostname.foo.com
- # Turn on/off impersonation mechanism when talking to Impala
- ## impersonation_enabled=False
- # Number of initial rows of a result set to ask Impala to cache in order
- # to support re-fetching them for downloading them.
- # Set to 0 for disabling the option and backward compatibility.
- ## querycache_rows=50000
- # Timeout in seconds for thrift calls
- ## server_conn_timeout=120
- # Hue will try to close the Impala query when the user leaves the editor page.
- # This will free all the query resources in Impala, but also make its results inaccessible.
- ## close_queries=true
- # If QUERY_TIMEOUT_S > 0, the query will be timed out (i.e. cancelled) if Impala does not do any work
- # (compute or send back results) for that query within QUERY_TIMEOUT_S seconds.
- ## query_timeout_s=600
- ###########################################################################
- # Settings to configure HBase Browser
- ###########################################################################
- [hbase]
- # Comma-separated list of HBase Thrift servers for clusters in the format of '(name|host:port)'.
- # Use full hostname with security.
- ## hbase_clusters=(Cluster|localhost:9090)
- # HBase configuration directory, where hbase-site.xml is located.
- ## hbase_conf_dir=/etc/hbase/conf
- # Hard limit of rows or columns per row fetched before truncating.
- ## truncate_limit = 500
- # 'buffered' is the default of the HBase Thrift Server and supports security.
- # 'framed' can be used to chunk up responses,
- # which is useful when used in conjunction with the nonblocking server in Thrift.
- ## thrift_transport=buffered
- ###########################################################################
- # Settings to configure Solr Search
- ###########################################################################
- [search]
- # URL of the Solr Server
- solr_url=http://172.21.50.41:8983/solr/
- # Requires FQDN in solr_url if enabled
- ## security_enabled=false
- ## Query sent when no term is entered
- ## empty_query=*:*
- ###########################################################################
- # Settings to configure Solr Indexer
- ###########################################################################
- [indexer]
- # Location of the solrctl binary.
- ## solrctl_path=/usr/bin/solrctl
- # Location of the solr home.
- ## solr_home=/usr/lib/solr
- # Zookeeper ensemble.
- ## solr_zk_ensemble=localhost:2181/solr
- # The contents of this directory will be copied over to the solrctl host to its temporary directory.
- ## config_template_path=/../hue/desktop/libs/indexer/src/data/solr_configs
- ###########################################################################
- # Settings to configure Job Designer
- ###########################################################################
- [jobsub]
- # Location on local FS where examples and template are stored.
- ## local_data_dir=..../data
- # Location on local FS where sample data is stored
- ## sample_data_dir=...thirdparty/sample_data
- ###########################################################################
- # Settings to configure Job Browser
- ###########################################################################
- [jobbrowser]
- # Share submitted jobs information with all users. If set to false,
- # submitted jobs are visible only to the owner and administrators.
- ## share_jobs=true
- ###########################################################################
- # Settings to configure the Zookeeper application.
- ###########################################################################
- [zookeeper]
- [[clusters]]
- [[[default]]]
- # Zookeeper ensemble. Comma separated list of Host/Port.
- # e.g. localhost:2181,localhost:2182,localhost:2183
- host_ports=zk1:2181
- # The URL of the REST contrib service (required for znode browsing)
- ## rest_url=http://localhost:9998
- ###########################################################################
- # Settings to configure the Spark application.
- ###########################################################################
- [spark]
- # URL of the REST Spark Job Server.
- server_url=http://h1:8080/
- ###########################################################################
- # Settings for the User Admin application
- ###########################################################################
- [useradmin]
- # The name of the default user group that users will be a member of
- ## default_user_group=default
- ###########################################################################
- # Settings for the Sentry lib
- ###########################################################################
- [libsentry]
- # Hostname or IP of server.
- ## hostname=localhost
- # Port the sentry service is running on.
- ## port=8038
- # Sentry configuration directory, where sentry-site.xml is located.
- ## sentry_conf_dir=/etc/sentry/conf
编译好的目录如下:
- -rw-rw-r-- 1 search search 2782 5月 19 06:04 app.reg
- -rw-rw-r-- 1 search search 2782 5月 19 05:41 app.reg.bak
- drwxrwxr-x 22 search search 4096 5月 20 01:05 apps
- drwxrwxr-x 3 search search 4096 5月 19 05:41 build
- drwxr-xr-x 2 search search 4096 5月 19 05:40 data
- drwxrwxr-x 7 search search 4096 5月 20 01:29 desktop
- drwxrwxr-x 2 search search 4096 5月 19 05:41 dist
- drwxrwxr-x 7 search search 4096 5月 19 05:40 docs
- drwxrwxr-x 3 search search 4096 5月 19 05:40 ext
- -rw-rw-r-- 1 search search 11358 5月 19 05:38 LICENSE.txt
- drwxrwxr-x 2 search search 4096 5月 20 01:29 logs
- -rw-rw-r-- 1 search search 8121 5月 19 05:41 Makefile
- -rw-rw-r-- 1 search search 8505 5月 19 05:41 Makefile.sdk
- -rw-rw-r-- 1 search search 3093 5月 19 05:40 Makefile.tarball
- -rw-rw-r-- 1 search search 3498 5月 19 05:41 Makefile.vars
- -rw-rw-r-- 1 search search 2302 5月 19 05:41 Makefile.vars.priv
- drwxrwxr-x 2 search search 4096 5月 19 05:41 maven
- -rw-rw-r-- 1 search search 801 5月 19 05:40 NOTICE.txt
- -rw-rw-r-- 1 search search 4733 5月 19 05:41 README.rst
- -rw-rw-r-- 1 search search 52 5月 19 05:38 start.sh
- -rw-rw-r-- 1 search search 65 5月 19 05:41 stop.sh
- drwxrwxr-x 9 search search 4096 5月 19 05:38 tools
- -rw-rw-r-- 1 search search 932 5月 19 05:41 VERSION
6,启动hue,执行命令:build/env/bin/supervisor
- [search@h1 hue]$ build/env/bin/supervisor
- [INFO] Not running as root, skipping privilege drop
- starting server with options { 'ssl_certificate': None, 'workdir': None, 'server_name': 'localhost', 'host': '0.0.0.0', 'daemonize': False, 'threads': 10, 'pidfile': None, 'ssl_private_key': None, 'server_group': 'search', 'ssl_cipher_list': 'DEFAULT:!aNULL:!eNULL:!LOW:!EXPORT:!SSLv2', 'port': 8000, 'server_user': 'search'}
然后我们就可以访问安装机ip+8000端口来查看了: 
工具箱界面: 
hive的界面: 
在配置hive(散仙这里是0.13的版本)的时候,需要注意以下几个方面:
hive的metastrore的服务和hiveserver2服务都需要启动
执行下面命令
bin/hive --service metastore
bin/hiveserver2
除此之外,还需要关闭的hive的SAL认证,否则,使用hue访问会出现问题。
注意下面三项的配置
-
hive.metastore.warehouse.dir -
/user/hive/warehouse -
location of default database for the warehouse -
hive.server2.thrift.port -
10000 -
Port number of HiveServer2 Thrift interface. - Can be overridden by setting $HIVE_SERVER2_THRIFT_PORT
-
hive.server2.thrift.bind.host -
h1 -
Bind host on which to run the HiveServer2 Thrift interface. - Can be overridden by setting $HIVE_SERVER2_THRIFT_BIND_HOST
-
hive.server2.authentication -
NOSASL -
- Client authentication types.
- NONE: no authentication check
- LDAP: LDAP/AD based authentication
- KERBEROS: Kerberos/GSSAPI authentication
- CUSTOM: Custom authentication provider
- (Use with property hive.server2.custom.authentication.class)
- PAM: Pluggable authentication module.
除了上面的配置外,还需要把hive.server2.long.polling.timeout的参数值,默认是5000L给改成5000,否则使用beenline连接时候,会出错,这是hive的一个bug。
pig的界面: 
solr的界面如下: 
最后需要注意一点,hue也需要在hadoop的core-site.xml里面配置相应的代理用户,示例如下:
-
hadoop.proxyuser.hue.hosts -
* -
-
hadoop.proxyuser.hue.groups -
*
ok至此,我们的hue已经能完美工作了,我们可以根据自己的需要,定制相应的app插件,非常灵活!