前情回顾
上一期《serverless往事:从零搭建一个web应用》被要求整改了。整改完与这一期同时发布。新搭建的互联网Web应用改名为E-Pub,HR母系统就叫做IVF。
这一期里我将E-pub前后端做了分离,并将从前端框架、通信、缓存、ORM逐层介绍新的技术栈。同时也会有一些小小的吐槽。
前端框架之Nuxt.Js
上一期提到了VUE的服务端渲染(SSR)框架Nuxt。网上讨论SSR的时候往往只专注于首页渲染和SEO,我个人觉得后端渲染的最大优点是配置简单,易学易用。这可能也是我们厂一直以来偏好后端渲染的某种原因吧,从后端HTML拼接,到jsp,到IVF使用的thymeleaf,起步阶段并不需要太多学习成本。(我的Nuxt并非继承于IVF,因为E-pub只是支线业务,总监们可能并不知道我的技术栈)但是起步简单并不见得坑少,IVF就懒得喷了,我们的Nuxt也是一个深坑,其中让我最头疼的问题就是部署。lambda的部署时有一个磁盘限制:Package必须同时满足压缩状态下小于50M和解压后小于250M这两个条件。而Nuxt的Package天生巨大,这让我一度想转到SPA(single page web application)模式。当然SPA也有自己的坑,后期实践也发现了一些难题:比如前端日志搜集、History Mode配置、首页渲染、webpack的学习成本等等。
所幸的是Nuxt2适时release了,体量大幅减少,然后组里的一个小朋友分离了前后端,减少了依赖,将package的体积限制在了100余M,总算暂时渡过了难关。
通信之Graphql
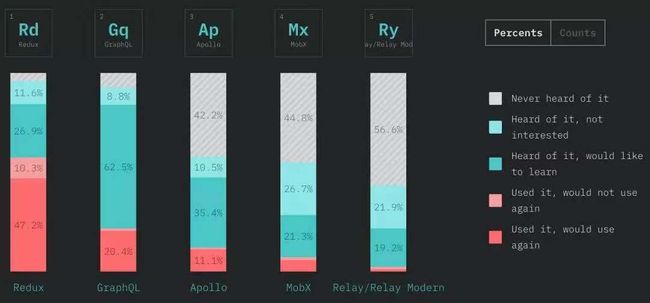
那时Graphql v.s. Rest的话题已经大火,各种公众号狂推Graphql。我在仔细阅读过Graphql开发文档后立马决定试水新技术。这时公司里又是另一番景象,鲜有人听闻Graphql,所以我还特地做了一个厂内的技术分享《Graphql Trial》,可惜并没有一个领导来听。Graphql最吸引我的地方是代码即文档,主要还是因为懒吧;IVF(对,就是我们的母系统)中就碰到过这种事,各种胡乱定义、是似而非的rest api,根本没人维护。我当时就一个光杆司令,与其提出一些不切实际的document要求,搭建一个没人维护的swagger服务器,还不如一开始就放弃Restful。除此之外Graphql在复杂查询、Mock、类型检查等等操作上与Rest相比有压倒性优势。后来我甚至将Graphql服务单独作为各个微服务的收集器用于前端调用,这是后话了。以下是2018年Javascirpt数据层的主流框架,以今年的趋势,不出意外2019年graphql就应该登顶了。
Cache之 DataLoader
我第一篇博客介绍的就是DataLoader。DataLoader的主要功能有两点:
- 内存级缓存
- 批处理
我当时引入DataLoader的主要目的是减少Dynamodb的资费,因为Dynamodb有单位读写限制。后来发现Cache层本身就意义重大:
- 解决Graphql N+1 Problem
- 减少DB读写
- 加速前端数据读取
- 临时存储preview数据
但缓存也带来一些不可避免的负面因素,比如脏数据。因此在编写缓存策略时要设置expiry time和max size,但即便如此也不可能完全杜绝负面影响。很多时候架构就是一种权衡,两害相权。
ORM之Dynamoose
Dynamodb的操作也是一堆坑。AWS提供了一套原生的Javascript SDK,大体写法如下,及其难用!每次都要指定table、key,然后再通过params传值。此外,最大的困扰是:javascript和Dynamodb都是非强类型的,你会有一种特别的不安全感,因为任何类型、任何域都能往DB里塞。表结构及其混乱,不具备很强的工程实践性。
var params = {
TableName: 'Table',
IndexName: 'Index',
KeyConditionExpression: 'HashKey = :hkey and RangeKey > :rkey',
ExpressionAttributeValues: {
':hkey': 'key',
':rkey': 2015
}
};
var documentClient = new AWS.DynamoDB.DocumentClient();
documentClient.get(params, function(err, data) {
if (err) console.log(err);
else console.log(data);
});
被恶心一段时间后,我把es6换成了Typescript,并开始使用Dynamoose代替原生的SDK。Dynamoosejs引入了schema的概念(受Mongoose启发),与table列一一对应。工程中,可以很直观地见识到表结构。
const schema = {
hkey: {
hashKey: true,
type: String,
},
rkey: {
rangeKey: true,
type: Number,
},
// Other columns...
status: String,
}
dynamoose.model(Table_Name, schema).get(key);// return Promise
架构改进
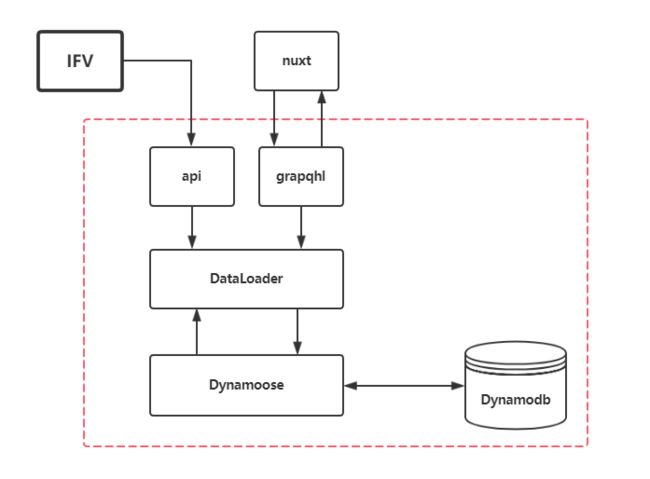
加入新的技术栈后我调整了一下架构,IVF依旧通过轮询Rest Api调用E-pub后端,E-pub前端nuxt则通过单点/grapql访问后端;后端则对互联网屏蔽所有/api。
说到这里我吐槽一下,很多人都有一种乌托邦的幻想,特别崇拜顶层设计,以为神祗画一个圈就可以天下大治。我不相信这些传说,我更愿意相信由下而上的自发改良。架构设计中也是这样,并没有神祗架构通配一切。反倒是在人力、设备、管理、技术都不适配的情况下强推过于复杂的架构,更容易带来毁灭性的结果。下面是书上看来的一些架构设计原则:
- 简单优于复杂
- 合适优于时髦
- 迭代演化优于一步到位。
把握好这些尺度,架构设计才能真正帮助解耦软件开发中的高复杂度。
小结
这一期回忆了我在工程起步后对架构的一些调整。层级很简单,但是新架构运行的还算良好。很快这一套基础框架就在组里被大力推广,PC端、mobile端、line端同步展开。我一个人的项目迅速扩展到了十几人。
越来越多的新功能被要求集成到serverless里,老的架构似乎又开始面临新的问题,这回我们又该如何变化呢?To be continue....
相关博客:
《serverless往事:从零搭建一个web应用》
Facebook Dataloader