Active Learning的简介
解决什么问题
- 数据标记有时候是个大问题,几百,几千,几万,十万,百万,千万的数据要一一标注的成本非常高。
- 引入active learning,是希望能减少数据标注的量。
是什么?
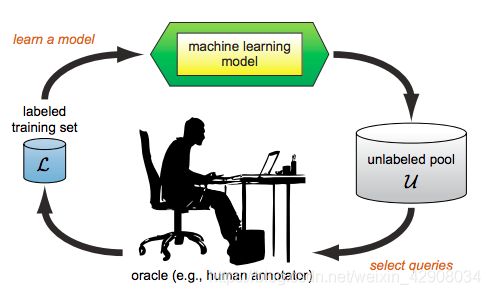
训练的数据不是一开始全部给,而是选择比较有用的数据,慢慢动态地增加,如上图。
原理

一句话,就是训练数据对模型的贡献程度不同,尽量挑选那些关键的数据。比如上图平面的点分类问题,只需要在中间间隔的数据就够了,而明显在2边的数据则对我们的分割线没啥帮助。
如何做
重点在数据的选择方法,常用的有如下方法:
- Least Confidence:
当前model预测出的最不自信的那些数据,手工标注那些数据。 - Margin Sampling:
当前model预测出来,比较摸棱两可。预测出来2个label的概率,比较接近,不知道如何选择。 - Entropy Sampling:
熵,表示信息量的大小,选择信息量比较大的那些数据。

例子
sklearn自带的digit数据
1.显示函数
from matplotlib import pyplot as plt
def show_imgs(imgs, columns):
"""
imgs: a dict(OrderDict to keep the order), its format is {title0:numpy_array, title1:(x, y), ...}
"""
fig = plt.figure(figsize=(12,12))
rows = len(imgs)//columns
begin = rows*100 + columns*10 + 1
for index, (title, img) in enumerate(imgs.items()):
ax = fig.add_subplot(begin + index)
if isinstance(img, (tuple, list)) and len(img) == 2:
x, y = img
ax.scatter(x, y)
else:
ax.imshow(img, 'gray')
ax.set_title(title)
plt.show()
2.展示digits数据的前9个:
from sklearn.datasets import load_digits
digits = load_digits()
imgs = {
digits.target[i]: digits.data[i].reshape(8, -1) for i in range(9)}
show_imgs(imgs, 3)

3. 4种数据选择策略
def RandomSample(proba, batch_size):
return np.random.choice(range(proba.shape[0]),batch_size,replace=False)
def LeastConfidence(proba, batch_size):
"""only care the max possibility"""
return np.argsort(np.max(proba,axis=1))[:batch_size]
def MarginSampling(proba, batch_size):
"""margin between the 2 most likely labels is narrow"""
sorted_proba = np.sort(proba,axis=1)
return np.argsort(sorted_proba[:,-1]-sorted_proba[:,-2])[:batch_size]
def Entropy(proba, batch_size):
"""highest variance"""
entropy = np.average(-1*proba*np.log(proba), axis=1)
return np.argsort(entropy)[-1*batch_size:]
- 4种策略来进行训练
import numpy as np
from sklearn.linear_model import LogisticRegression
import warnings
from tqdm import tqdm
warnings.filterwarnings('ignore')
def plot_result(res):
from matplotlib import pyplot as plt
import pandas as pd
pd.DataFrame(res).plot()
plt.ylabel("Accuracy")
plt.xlabel("Data amount")
plt.show()
def train(query_func, x, y, rounds, batch_size):
# to let every query func start at the same point
np.random.seed(1)
clf = LogisticRegression()
sample_indexs = RandomSample(x, batch_size)
x_train = x[sample_indexs]
y_train = y[sample_indexs]
res = []
for i in tqdm(range(rounds-1)):
clf.fit(x_train, y_train)
prec = clf.score(x,y)
res.append(prec)
proba = clf.predict_proba(x)
sample_indexs = query_func(proba, batch_size)
x_train = np.concatenate([x_train, x[sample_indexs]])
y_train = np.concatenate([y_train, y[sample_indexs]])
prec = clf.score(x, y)
res.append(prec)
return res
def get_digits_data():
from sklearn.datasets import load_digits
digits = load_digits()
return digits.data, digits.target
def main():
x, y = get_digits_data()
results = {
}
for query_func in (RandomSample, LeastConfidence, MarginSampling, Entropy):
res = train(query_func, x, y, rounds=16, batch_size=64)
results[query_func.__name__] = res
plot_result(results)
print('done')
main()
结果如下:

明显可以看出,常用的3种策略,明显比随机的好。