re解析(正则表达式)
今天小编开始说说正则表达式,欢迎大家一起学习,留言,评论
re解析(及正则表达式):是一种使用表达式的方式对字符串进行匹配的语法规则。
优点:速度快,效率高,准确性高
缺点:小白上手难度较大
正则语法:使用字符串进行排列组合来匹配字符串。
好玩的测试环境:https://www.oschina.net/(中在线工具进行测试)
正则元字符:
常见元字符
. 匹配换行符外的任意字符
\w 匹配字母或数字或下划线
\s 匹配空白符
\d 匹配数字
\n 匹配一行换行符
\t 匹配一个制表符
^ 匹配字符串开始
$ 匹配字符串的结尾
\W 匹配非字母或数字或下划线
\D 匹配非数字
\S 匹配非空白符
a|b 匹配字符a到b
() 匹配括号内的表达式,也表示一个组
[...] 匹配字符组中的字符
[^...] 匹配除了匹配字符组中的所以字符
量词:(例:/d{5} 匹配5次数字)
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{
n} 重复n次
{
n,} 重复n次或更多次
{
n,m} 重复n到m次
贪婪匹配和惰性匹配
.* 贪婪匹配(匹配最多的)
.*? 惰性匹配(回溯算法,匹配最少的)
惰性匹配:
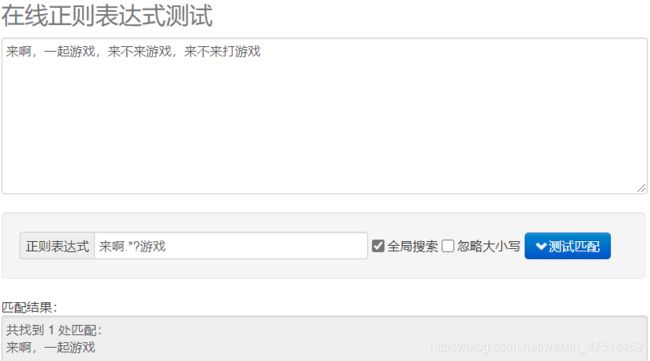
贪婪匹配:
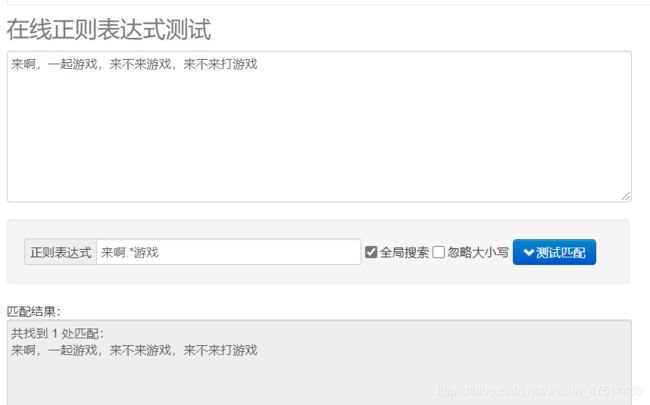
python中正则匹配:
re模块:
import re #导入模块
#findall匹配字符串中所有符合正则的内容
lst=re.findall("\d+","基本的电话号码,110,120,119")
print(lst)#['110', '120', '119']
#finditer匹配字符串中所以内容【返回迭代器】
it=re.finditer("\d+","基本的电话号码,110,120,119")
for i in it :#读取可迭代对象
print(i.group())#110,120,119
#search返回结果是math对象,拿数据.group(),找到一个结果就返回
s=re.search("\d+","基本的电话号码,110,120,119")
print(s.group())#110
#match从头匹配,找到一个结果就返回,不在头就会报错
m=re.match(r"\d+","110,120,119")
print(s.group())#110
#预加载正则表达
obj=re.compile(r"\d+")
ret=obj.finditer('基本的电话号码,110,120,119')
for i in ret :
print(i.group())#110,120,119
从一句话中提取需要内容:
import re
s="""
李白>
杜甫>
李时珍>
陆游>
苏轼>
白居易>
"""
obj=re.compile(r".*? ",re.S)#re.S 让.腝匹配换行符
result=obj.finditer(s)
for i in result :
print(i)
#(?P<分组名字>正则)获取内容
obj1=re.compile(r"(?P.*?)> ",re.S)#在tist中取需要内容
s=obj1.finditer(s)
for it in s :
print(it.group("tist"))
现象:
