面试时的面试题总汇
大多是网上已经有的题目,很多题目大家应该都已经看过,这里只是做个面试时遇上的面试题的汇总
JVM的内存结构
来源:https://www.zhihu.com/question/333684160/answer/752557741
主要分为三大块 堆内存、方法区、栈;栈又分为JVM栈、本地方法栈
堆(heap space),堆内存是JVM中最大的一块,有年轻代和老年代组成,而年轻代又分为三分部分,Eden区,From Survivor,To Survivor,默认情况下按照8:1:1来分配
方法区(Method area),存储类信息、常量、静态变量等数据,是线程共享的区域
程序计数器(Program counter Register),是一块较小的内存空间,是当前线程所执行的字节码的行号指示器
JVM栈(JVM stacks),也是线程私有的,生命周期与线程相同,每个方法被执行时都会创建一个栈帧,用于存储局部变量表、操作栈、动态链接、方法出口等信息
本地方法栈(Native Mthod Stacks),为虚拟机使用的native方法服务
hashCode和equals的区别与联系
联系
java中任何一个对象都具备equals()与hashCode()方法
如果equals方法相等,那hashCode方法也应该相等(如果重写equals方法判断为true,而hashCode方法不相等,虽然不会报错,但是不符合Java规范,这是给自己挖坑)
区别
equals
原生的equals()比较的也是引用地址,但是重写之后可以比较堆里面的值内容是否相等,一般用于集合元素的比较,避免重复插入。重写后后一般都是通过对象的内容是否相等来判断对象是否相等
hashCode
根据对象的值计算其物理存储位置,即hash值,对于值equals的对象,其hashCode一定相等,但是即使值不相等,也可能得到相同的hash值,因此在同一hash值的位置形成了链表,可以看出,每次new出一个对象,直接计算出其hash值,然后寻找对应位置上,再使用equals方法比较,是否已存在值就可以知道对象是否重复了,这样比依次调用equals()与集合中的每个元素比较要节省很多时间。
==
当他们用(==)进行比较的时候,比较的是他们在内存中的存放地址,所以,除非是同一个new出来的对象,他们的比较后的结果为true,否则比较后结果为false。一般对基本数据类型比较
集合之间的关系
继承关系如图所示

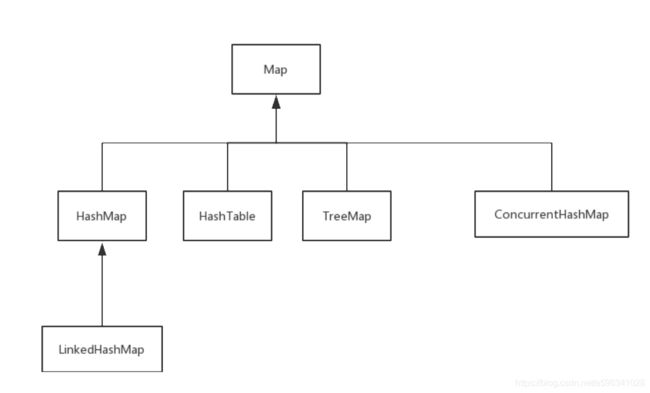
Map是没有继承类的,虽然这是基础,但是今天被面试官问了Map继承谁,记得看过源码Map没有继承类,但是又想起在菜鸟教程看到这个图,脑子一抽就把Collection说出来了.....主要是脑子在想Map继承,就跟段子一样:老师打你痛不痛??血崩,面试脑子要灵活点啊
Set集合:
HashSet:继承Set,底层数据结构是哈希表(无序,唯一性),允许null
List集合:
ArrayList:底层结构是数组,有下标,有序,可存放相同数据,允许null
Map集合:
HashMap:底层结构是哈希表,没有迭代器,采用数组+链表的存储方式,即数组中的每一个元素都是链表,key值:不可重复,支持null
HashMap实现原理:首先有一个每个元素都是链表(可能表述不准确)的数组,当添加一个元素(key-value)时,就首先计算元素key的hash值,以此确定插入数组中的位置,但是可能存在同一hash值的元素已经被放在数组同一位置了,这时就添加到同一hash值的元素的后面,他们在数组的同一位置,但是形成了链表,同一各链表上的Hash值是相同的,所以说数组存放的是链表。而当链表长度太长时,链表就转换为红黑树,这样大大提高了查找的效率。
HashTable和HashMap的区别

Session和Cookie的区别
- cookie数据存放在客户的浏览器上,session数据放在服务器上
- cookie不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗,考虑到安全应当使用session
- session会在一定时间内保存在服务器上,当访问增多,会比较占用你服务器的性能,考虑到减轻服务器性能方面,应当使用cookie
- 单个cookie保存的数据不能超过3K,很多浏览器都限制一个站点最多保存20个cookie
- session保存在服务器,客户端不知道其中的信心;cookie保存在客户端,服务器能够知道其中的信息
- session中保存的是对象,cookie中保存的是字符串
- session不能区分路径,同一个用户在访问一个网站期间,所有的session在任何一个地方都可以访问到,而cookie中如果设置了路径参数,那么同一个网站中不同路径下的cookie互相是访问不到的
如果客户端禁用了cookie怎么使用session
当客户端禁用了cookie时,造成session无法访问,此时我们可以使用URL重写来解决这个问题
response.encodeURL(String url);
//--如果是普通的地址用这个方法
response.encodeRedirectURL(String url);
//--如果地址是用来进行重定向的,用这个方法
数据库的三范式
第一范式
- 第一范式(1NF)要求数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值。
- 若某一列有多个值,可以将该列单独拆分成一个实体,新实体和原实体间是一对多的关系。
- 在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。
第二范式
- 满足第二范式(2NF)必须先满足第一范式(1NF)。
- 第二范式要求实体中没一行的所有非主属性都必须完全依赖于主键;即:非主属性必须完全依赖于主键。
- 完全依赖:主键可能由多个属性构成,完全依赖要求不允许存在非主属性依赖于主键中的某一部分属性。
- 若存在哪个非主属性依赖于主键中的一部分属性,那么要将发生部分依赖的这一组属性单独新建一个实体,并且在旧实体中用外键与新实体关联,并且新实体与旧实体间是一对多的关系。
第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
第三范式
- 满足第三范式必须先满足第二范式。
- 第三范式要求:实体中的属性不能是其他实体中的非主属性。因为这样会出现冗余。即:属性不依赖于其他非主属性。
- 如果一个实体中出现其他实体的非主属性,可以将这两个实体用外键关联,而不是将另一张表的非主属性直接写在当前表中。
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
比如在设计一个订单数据表的时候,可以将客户编号作为一个外键和订单表建立相应的关系。而不可以在订单表中添加关于客户其它信息(比如姓名、所属公司等)的字段。
Spring事务隔离
ISOLATION_DEFAULT: 这是一个 PlatfromTransactionManager 默认的隔离级别,使用数据库默认的事务隔离级别.
JDBC事务隔离
ISOLATION_READ_UNCOMMITTED: 这是事务最低的隔离级别,它允许令外一个事务可以看到这个事务未提交的数据,
这种隔离级别会产生脏读,不可重复读和幻像读。
ISOLATION_READ_COMMITTED: 保证一个事务修改的数据提交后才能被另外一个事务读取。另外一个事务不能读取该事务未提交的数据
ISOLATION_REPEATABLE_READ: 这种事务隔离级别可以防止脏读,不可重复读。但是可能出现幻像读。它除了保证一个事务不能读取另一个事务未提交的数据外,还保证了避免下面的情况产生(不可重复读)。
ISOLATION_SERIALIZABLE 这是花费最高代价但是最可靠的事务隔离级别。事务被处理为顺序执行。
不考虑隔离性会出现的读问题
脏读:在一个事务中读取到另一个事务没有提交的数据
不可重复读:在一个事务中,两次查询的结果不一致(针对的update操作)
虚读(幻读):在一个事务中,两次查询的结果不一致(针对的insert操作)
SpringBoot定时任务注解
基于注解@Scheduled
基于接口SchedulingConfigurer
@Autowire和@Resource的区别
@Autowire默认按照类型(by-type)装配,默认情况下要求依赖对象必须存在。
- 如果允许依赖对象为null,需设置required属性为false,即
@Autowire(required=false)
private InjectionBean beanName;- 如果使用按照名称(by-name)装配,需结合@Qualifier注解使用,即
@Autowire
@Qualifier("beanName")
private InjectionBean beanName;说明
@Autowire按照名称(by-name)装配,则
@Autowire + @qualifier("") = @Resource(name="")
@Resource默认按照名称(by-name)装配,名称可以通过name属性指定。
如果没有指定name
当注解在字段上时,默认取name=字段名称装配。
当注解在setter方法上时,默认取name=属性名称装配。
当按照名称(by-name)装配未匹配时,按照类型(by-type)装配。
当显示指定name属性后,只能按照名称(by-name)装配。
@Resoure装配顺序
如果同时指定name和type属性,则找到唯一匹配的bean装配,未找到则抛异常;
如果指定name属性,则按照名称(by-name)装配,未找到则抛异常;
如果指定type属性,则按照类型(by-type)装配,未找到或者找到多个则抛异常;
既未指定name属性,又未指定type属性,则按照名称(by-name)装配;如果未找到,则按照类型(by-type)装配。

SpringMVC接收Json格式
@RequestBody:接受json格式的参数
public void mian(@RequestBody int a);
@ResponseBody:传递json格式的参数
@ResponseBody
public void mian(int a);
wait和sleep的区别
sleep()使当前线程进入停滞状态(阻塞当前线程),让出CUP的使用、目的是不让当前线程独自霸占该进程所获的CPU资源,以留一定时间给其他线程执行的机会;
sleep方法没有释放锁,而wait方法释放了锁
wait()方法是Object类里的方法;当一个线程执行到wait()方法时,它就进入到一个和该对象相关的等待池中,同时失去(释放)了对象的机锁(暂时失去机锁,wait(long timeout)超时时间到后还需要返还对象锁);可以调用里面的同步方法,其他线程可以访问;
wait()使用notify或者notifyAlll或者指定睡眠时间来唤醒当前等待池中的线程。
深拷贝和浅拷贝
浅拷贝只是复制了对象的引用地址,两个对象指向同一个内存地址,所以修改其中任意的值,另一个值都会随之变化,这就是浅拷贝(例:assign())
深拷贝是将对象及值复制过来,两个对象修改其中任意的值另一个值不会改变,这就是深拷贝
TCP协议的三次握手与四次挥手
来源:https://blog.csdn.net/qq_38950316/article/details/81087809
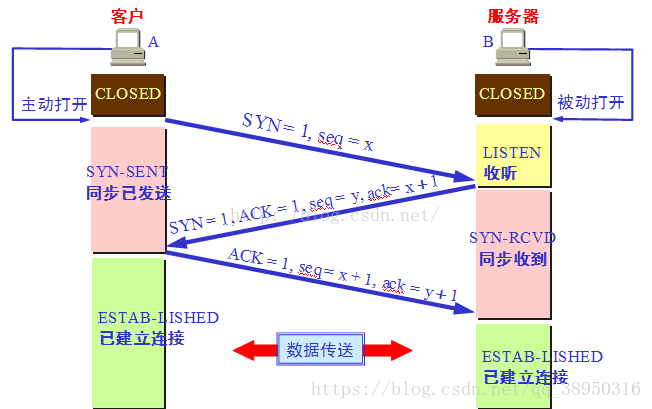
三次握手
第一次握手:在建立连接时,客户端发送syn(Synchronize Sequence Numbers同步序列编号)包到服务器,并进入SYN_SENT状态,等待服务器确认
第二次握手:服务器收到syn包,必须确认客户的SYN,同时自己也发送一个SYN包,即SYN+ACK包,此时服务器进入SYN_RECV状态
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK,包发送完毕后,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手
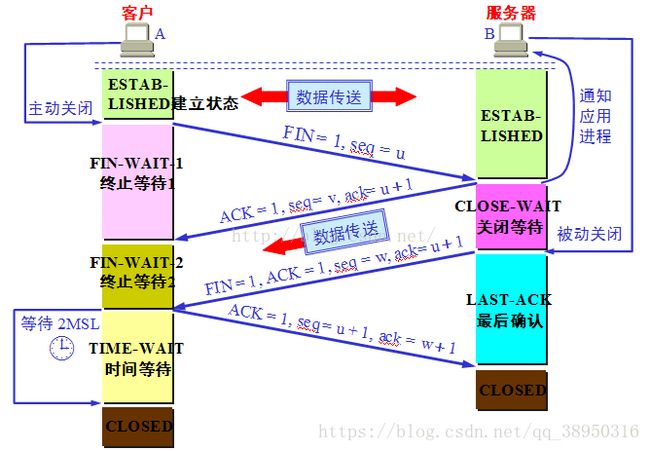
四次挥手
第一次挥手:
TCP发送一个FIN(结束),用来关闭客户到服务端的连接。
客户端进程发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),
此时,客户端进入FIN-WAIT-1(终止等待1)状态。 TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
第二次挥手:
服务端收到这个FIN,他发回一个ACK(确认),确认收到序号为收到序号+1,和SYN一样,一个FIN将占用一个序号。
服务器收到连接释放报文,发出确认报文,ACK=1,ack=u+1,并且带上自己的序列号seq=v,此时,服务端就进入了CLOSE-WAIT(关闭等待)状态。TCP服务器
通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个
状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。
客户端收到服务器的确认请求后,此时,客户端就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最后的数据)。
第三次挥手:
服务端发送一个FIN(结束)到客户端,服务端关闭客户端的连接。
服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,ack=u+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,
此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
第四次挥手:
客户端发送ACK(确认)报文确认,并将确认的序号+1,这样关闭完成。
客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,ack=w+1,而自己的序列号是seq=u+1,此时,客户端就进入了TIME-WAIT(时间等待)状态。注意此时
TCP连接还没有释放,必须经过2∗∗MSL(最长报文段寿命)的时间后,当客户端撤销相应的TCB后,才进入CLOSED状态。
长连接和短连接
来源:https://www.cnblogs.com/0201zcr/p/4694945.html
HTTP/1.0中,默认使用的是短连接。也就是说,浏览器和服务器每进行一次HTTP操作,就建立一次连接,但任务结束就中断连接。如果客户端浏览器访问的某个HTML或其他类型的 Web页中包含有其他的Web资源,如JavaScript文件、图像文件、CSS文件等;当浏览器每遇到这样一个Web资源,就会建立一个HTTP会话。
HTTP/1.1起,默认使用长连接,用以保持连接特性。使用长连接的HTTP协议。在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的 TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接。
短连接对于服务器来说管理较为简单,存在的连接都是有用的连接,不需要额外的控制手段。
但如果客户请求频繁,将在TCP的建立和关闭操作上浪费时间和带宽。
长连接和短连接的产生在于client和server采取的关闭策略,具体的应用场景采用具体的策略,没有十全十美的选择,只有合适的选择。
https如何实现传输安全
来源:https://www.cnblogs.com/-new/p/7663746.html
什么是https协议:https全称是hypertext protocol over secure socket layer,也就是基于ssl的http协议,http的安全版,可以理解为https=http+ssl
https功能
- 内容加密,用对称密钥进行加密
- 身份认证,数字证书验证身份
通信内容用对称加密算法机密,而对称加密的加密密钥通过非对称加密协商
MySql如何让索引失效
来源:https://www.cnblogs.com/shynshyn/p/7887742.html
1.如果条件中有or,即使其中有条件带索引也不会使用(这也是为什么尽量少用or的原因)
要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引
2.对于多列索引,不是使用的第一部分,则不会使用索引
3.like查询以%开头
4.如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
5.如果mysql估计使用全表扫描要比使用索引快,则不使用索引
Redis如何与项目连接
JavaIO模型的NIO
Redis的set和zset的区别
JDK8新特性
函数式接口