python批量重命名图片并写入txt文件
因为最近开始接触人脸识别,正在拜读林倞老师的《cross domain visual matching via generalized similarity measure and feature learning》,并开始跑这篇论文的caffe代码。由于代码里没有给出cuhk03数据集,以及train_cuhk_domain_1.txt和train_cuhk_domain_2.txt文件,所以我先下载了cuhk03数据集,而且是PNG格式。

然后先在txt文件了写了几行作为测试,发现caffe报错并提示找不到1_001_1_1.jpg。所以我在想是不是林老师的课题组编的底层输入数据的代码只识别jpg格式的图片,另外图片的命名也有一定的讲究。
一、读取文件夹的图片并把图片名写入txt文件
# encoding: UTF-8
import os
import re
def createFileList(images_path, txt_save_path):
# 打开图片列表清单txt文件
fw = open(txt_save_path, "w")
# 查看图片目录下的文件,相当于shell指令ls
images_name = os.listdir(images_path)
# 遍历所有文件名
for eachname in images_name:
# 按照规则将内容写入txt文件中
fw.write(eachname+'\n')
# 打印成功信息
print "生成txt文件成功"
# 关闭fw
fw.close()
# 下面是相关变量定义的路径
if __name__ == '__main__':
# txt存放目录,并且注意这边的路径有中文,所以要做一些变换。
txt_path=u"G:\\研究生研究方向\\人脸识别\\train\\".encode('gbk')
# 图片存放目录
images_path = u'G:\\研究生研究方向\\人脸识别\\cuhk03_detected\\'.encode('gbk')
# 生成的图片列表清单txt文件名
txt_name = '0329.txt'
# 生成的图片列表清单txt文件的保存目录
txt_save_path = txt_path + txt_name
# 生成txt文件
createFileList(images_path, txt_save_path)结果如下:
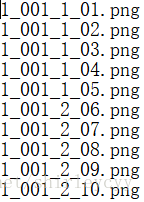
二、批量重命名txt文件(后缀,以及字段的提取、替换)
把txt文件中的png改成jpg
# encoding: UTF-8
#要写入的文件
fp=open(u"G:\\研究生研究方向\\人脸识别\\train\\0329_1.txt".encode('gbk'),'w')
#打开的文件
lines=open(u"G:\\研究生研究方向\\人脸识别\\train\\0329.txt".encode('gbk')).readlines()
for s in lines:
fp.write(s.replace("png","jpg"))#把后缀名替换掉
fp.close()
提取domain1的字段
# encoding: UTF-8
import re
fp=open(u"G:\\研究生研究方向\\人脸识别\\train\\0329_domain1.txt".encode('gbk'),'w')
lines=open(u"G:\\研究生研究方向\\人脸识别\\train\\0329_1.txt".encode('gbk')).readlines()
for s in lines:
#re正则表达式,模式匹配
domain1=re.search('_1_',s)
if domain1 is not None:
fp.write(s)
fp.close()
提取domain2的字段
# encoding: UTF-8
import re
fp=open(u"G:\\研究生研究方向\\人脸识别\\train\\0329_domain2.txt".encode('gbk'),'w')
lines=open(u"G:\\研究生研究方向\\人脸识别\\train\\03291.txt".encode('gbk')).readlines()
for s in lines:
domain1=re.search('_2_',s)
if domain1 is not None:
fp.write(s)
fp.close()
替换1_001_1_01.jpg为1_001_1_1.jpg
# encoding: UTF-8
fp=open(u"G:\\研究生研究方向\\人脸识别\\train\\train_domain1.txt".encode('gbk'),'w')
lines=open(u"G:\\研究生研究方向\\人脸识别\\train\\0329_domain1.txt".encode('gbk')).readlines()
for s in lines:
fp.write(s.replace("_1_0","_1_"))
fp.close()
替换1_001_2_01.jpg为1_001_2_1.jpg
# encoding: UTF-8
fp=open(u"G:\\研究生研究方向\\人脸识别\\train\\train_domain2.txt".encode('gbk'),'w')
lines=open(u"G:\\研究生研究方向\\人脸识别\\train\\0329_domain2.txt".encode('gbk')).readlines()
for s in lines:
fp.write(s.replace("_2_0","_2_"))
fp.close()
至此,txt文件制作完成。
三、批量重命名png图片为jpg图片
#!/usr/bin/python
# -*- coding: UTF-8 -*-
from PIL import Image
from os.path import splitext
import glob
#png图片转换成jpg图片
files=glob.glob(u'G:\\研究生研究方向\\人脸识别\\cuhk03_detected\\*.png'.encode('gbk'))
for png in files:
im=Image.open(png)
jpg=splitext(png)[0]+"."+"jpg"
im.save(jpg)
print(jpg)
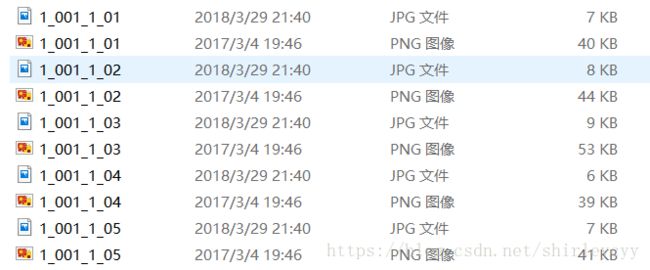
这样子批量生成了jpg格式的图片,然后把他们单独提取出来。
然后把图片的命名改变一下
# -*- coding:utf8 -*-
import os
class BatchRename():
'''
批量重命名文件夹中的图片文件
'''
def __init__(self):
self.path = u'G:\\研究生研究方向\\人脸识别\\test\\'.encode('gbk')
def rename(self):
filelist = os.listdir(self.path)
for item in filelist:
if "_1_0" in item:
s=item.replace("_1_0","_1_")
src = os.path.join(os.path.abspath(self.path), item)
dst = os.path.join(os.path.abspath(self.path), s)
os.rename(src,dst)
print(s)
if __name__ == '__main__':
demo = BatchRename()
demo.rename()这样子图片的命名也符合了之前的生成的txt文件里的命名。
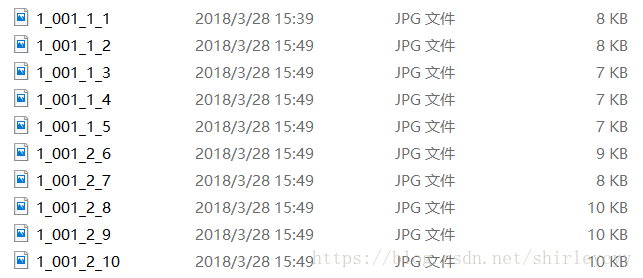
当然也可以先对图片的格式,命名进行转换,然后再写入txt文件。