介绍
相信SSD的横空出世委实给了Yolo许多压力。在目标检测准确性上Yolo本来就弱于Faster-RCNN,它的提出之初就主打其能保持一定检测准确性的同时实现更快乃至实时的速度。可同一年SSD的出现表明端到端的单阶段目标检测模型如果善加调理(更激进的data augmentation, multi scales feature maps,更多的default boxes数目,直接使用conv filter来从feature maps中得到位置、类别等信息)在拥有较快速度的同时,一样可以达到与像Faster-RCNN等双阶段目标检测模型类似的准确度。
经过一年的蛰伏之后,Yolo卷土重来,于2016年推出了改进后的Yolo v2。它有效地借鉴了Faster-RCNN/SSD中使用的思想,成功地使Yolo v2模型成为了新的state-of-art端到端目标检测网络。
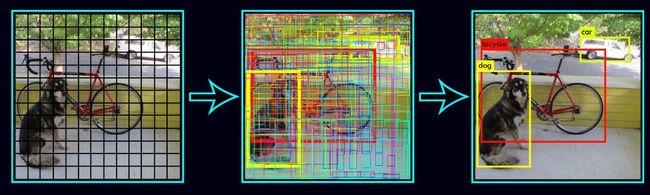
Yolo v2
不多废话,直接说下Yolo v2相对于之前的Yolo v1所多的改进吧。
BN(batch normalization)的引入
BN自提出以来已经在多个视觉领域得到了较好的证明。Yolo v2通过在之前Yolo中用到的所有conv层加入bn,整个模型的检测mAP有效提升了近2%。此外BN的引入也让作者放弃了在新的模型中使用之前用于防止模型过拟合的dropout层。
finetune时高精度分类器的使用
当初Yolo模型在训练时先使用224x224的图片输入来预训练自己的特征提取网络;然后再将输入的图片尺度增大到448x448,进面继续使用检测数据集对其进行finetune。这意味着上述finetune中网络需要重新学习识别大尺度(448)的图片以及学习进行其上的目标检测工作。
在Yolo v2中,在拿到224x224的分类数据集train过的模型后先使用448x448的分类数据集finetune上10个epochs,然后再使用448x448的目标检测数据集进行接下来的目标检测工作的finetune。。
实现表明finetune时高精度分类器的预先finetune操作可带来最终目标检测模型近4%的map提升。
使用卷积操作的Anchor boxes
Yolo v1模型当初直接在特征提取主干网络最后端生成的feature maps上后接FC,然后生成得到预测的目标框的类别、位置等信息。
而在Yolo v2中,像Faster-RCNN的RPN网络或者SSD等一样,开始直接使用conv filters来提取生成prior boxes(又叫Anchor boxes)的位置偏移及类别等信息。与其它网络略不同的是Yolo v2特意选了416x416的image size作为输入,这样经过前端的数个特征提取卷积层与pool层后(stride为32),最终的feature map大小为13x13,恰是个奇数。这样它就可以有效地预测最中心grid位置的目标(这一trick来自于一个数据集常识即一般我们training用的数据集上,目标往往是在图片的中央区域)。
相对于Yolo v1中直接使用FC来预测目标框的类别与位置,使用卷积生成anchor boxes位置与类别的方法会带来mAP约0.3的下降,但会导致较大的召回率(Recall ratio)提升,约7%。这使得这一模型可进一步改良、提升的空间加大。
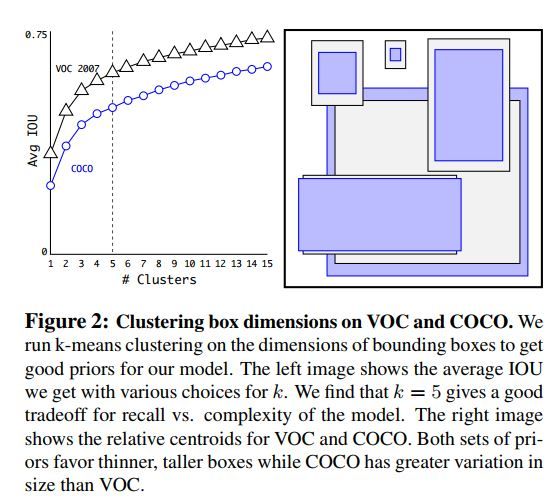
使用K-means cluster来选取anchor boxes
作者直接在目标检测训练数据集上对所有的目标框进行k-means聚类最终得到了Avg IOU与模型复杂度均不错的anchor boxes组合。如下为所使用的k-means中的距离衡量公式:
d(box; centroid) = 1 − IOU(box; centroid)
如下是它在VOC与COCO数据集上的聚类结果。最终在模型训练时选取了k = 5个anchor box。
直接目标框位置检测
Yolo v2同RPN等网络一样使用了卷积来生成anchor boxes的位置信息。但它在使用像Faster-RCNN或SSD中那样来进行位置偏离计算的方法来预测predicted box的位置时发现训练时非常容易出现震荡。如下为RPN网络所用的位置计算公式:
x = (tx ∗ wa) − xa
y = (ty ∗ ha) − ya
为了消除此一问题,作者使用如下公式直接对目标框位置进行预测。其中tx, ty, tw, th, 和to为网络预测得到的值,而cx与cy表示anchor box对图片的相对位置,pw与ph是anchor box的长与宽。
bx = σ(tx) + cx
by = σ(ty) + cy
bw = pwet~w~
bh = phet~h~
Pr(object) ∗ IOU(b; object) = σ(to)
下图中可看到更详细的解释。

细粒度特征的使用
SSD在目标检测时通过使用多尺度的feature maps特征,最终能够cover尺度广泛的目标,从而获得了较高的检测mAP。Yolo v2也吸取了此一优点。但它并不像SSD那样分别在不同的feature maps之上对不同尺度大小的anchor box进行预测,而是将拥有较细粒度特征的层变形后(使得与后面粗粒度的特征层有着一样的size,有些类似于用于super resolution的subpixel层;比如若其细粒度特征层为26x26x512,而最后一层粗粒度特征层的size则为13x13,于是这里会将它变形为13x13x1024从而与最后一个特征层有着一样的size,进行能在channel level上进行合并)与后面粗粒度的特征层结合在一起用于后续的anchor box预测。
多尺度训练
之前Yolo v1的固定图片输入大小为448x448,而Yolo v2因为Anchor box的引入从而将输入变为了416x416。进一步为了使得模型能够对各种尺度的图片进行有效检测,作者在训练Yolo v2时不再固定image size,而是每训练10个epochs随机地从一个组合{320; 352; :::; 608}中选取(注意它们都是32的倍数,因为darknet网络的步长为32)一个数作为输入的image size。此种训练方法被证明可有效地使得网络学会去自动识别各种尺度大小的图片。
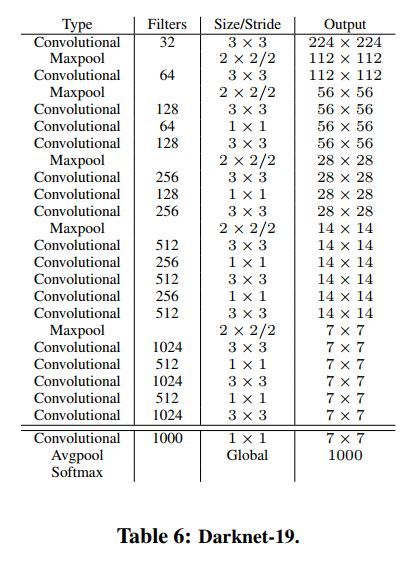
Darknet-19
Yolo v2还采用了有着19个Conv 层与5个maxpooling层的darknet-19作为模型的特征提取前端网络。在此网络中引入了BN用于稳定训练,加快收敛,同时防止模型过拟合。
下图为darknet-19网络的组成。
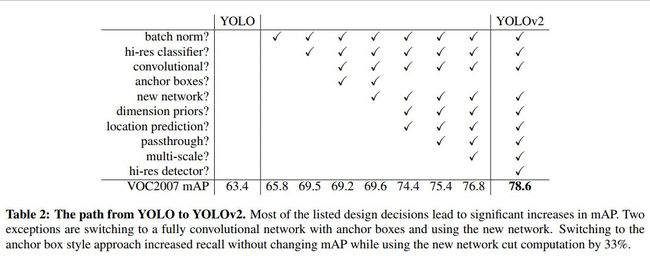
总结
自下表中我们可以清楚看到Yolo v2相对于Yolo v1共作出了哪些改变以及这些改变分别对模型性能提升所发挥的作用。
实验结果
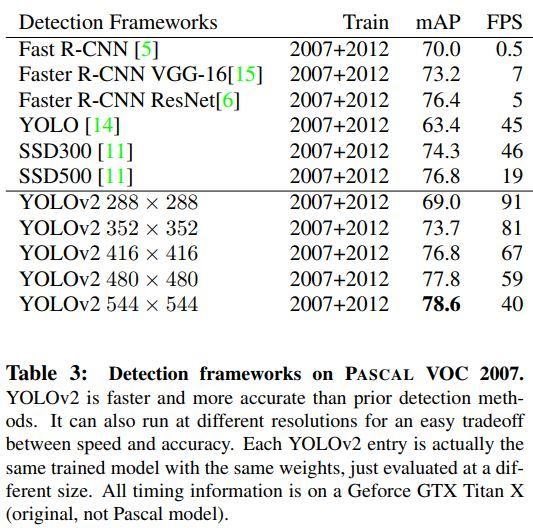
下表为Yolo v2与其它目标检测网络在VOC2007上的结果比较。有些小置疑,不明白为何Yolo v2甚至能够胜得了Faster-RCNN。笔者曾使用一个16 nodes的普通机群训练过SSD,可以在VOC07+12数据集上得到78.2%的test mAP精度。。所以作者的结果值得怀疑啊,呵呵。。
代码分析
以下为它的输入及训练时的超参配置。
[net]
# Testing
batch=1
subdivisions=1
# Training
# batch=64
# subdivisions=8
width=416
height=416
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.001
burn_in=1000
max_batches = 500200
policy=steps
steps=400000,450000
scales=.1,.1
以下为Anchor层的选择及设置参数。当然还有最终的模型loss计算及设置。
[region]
anchors = 0.57273, 0.677385, 1.87446, 2.06253, 3.33843, 5.47434, 7.88282, 3.52778, 9.77052, 9.16828
bias_match=1
classes=80
coords=4
num=5
softmax=1
jitter=.3
rescore=1
object_scale=5
noobject_scale=1
class_scale=1
coord_scale=1
absolute=1
thresh = .6
random=1
参考文献
- YOLO9000:Better, Faster, Stronger
- https://pjreddie.com/darknet/yolov2/