【JS逆向破解】爬虫抓取哦oh漫画实例Java/Python实现
目录
- 前言
- oh漫画网站分析
- 功能实现代码[Python/Java]
前言
oh漫画是我非常喜欢的一个漫画网站,里面有很多的漫画,唯一不好的地方就是广告太多了,最近有个需求是制作一个能爬到全网漫画的APP,所以就拿oh漫画为例子尝试制作一下。所以先随便打开一个oh漫画的漫画网址:https://www.ohmanhua.com/12187/2/554.html
广告真的是不堪入目(好康)。。。算了,就别管那么多,直接用requests试试访问能不能得到想要的结果
# -*- coding: utf-8 -*-
import requests
from pprint import pprint
headers = {
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'navigate',
'Referer': 'https://www.ohmanhua.com/',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
html = requests.get("https://www.ohmanhua.com/12214/1/433.html",headers=headers).text
pprint(html)
输出的结果是:
哈哈,不出意外返回的HTML肯定是没有图片的链接的,如果能爬出来我就没有写这篇博客的必要了,好了那我们就进入令人头皮发麻的JS破解,,,奥利给干了
oh漫画网站分析
先打开fiddler抓包,断点设置成之前请求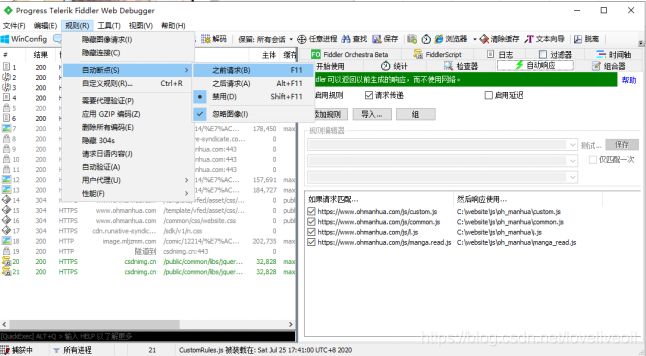
然后ctrl + x清楚fiddler页面所有请求后,重新加载oh漫画网页,慢慢的一步步用fiddler调试网页,然后在运行了四个JS文件后网页的图片就成功加载出来了,说明这个四个JS文件肯定有生成图片链接的函数之类的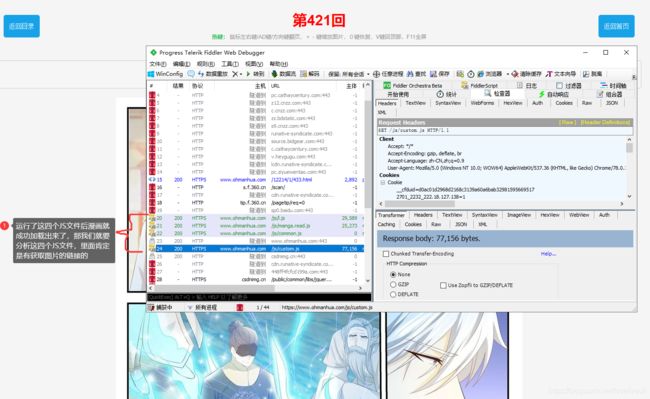
那我们事不宜迟,先关闭fiddler的捕获功能,打开F12控制台再重新加载网页,然后慢慢分析JS文件,得到了像下面这样的网页,划红线的就是我们在fiddler抓到的四个关键JS文件
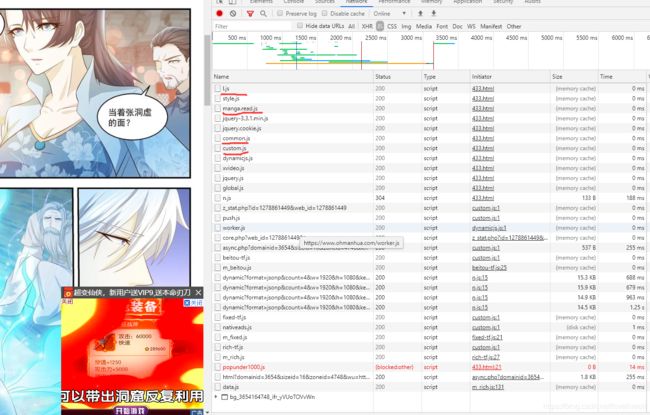
然后我们先把目光放在manga.read.js这个文件上,很明显这个文件肯定是和图片的加载有关系的,那我们就进入文件看看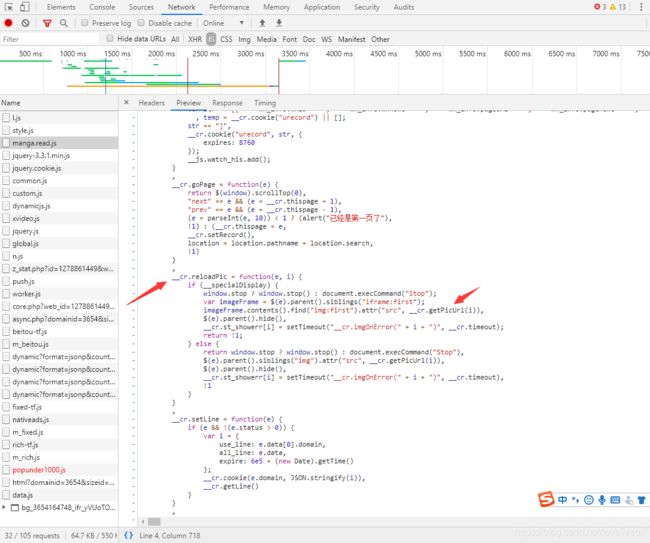
在浏览过程中我刚往下翻了一下下就看到了这个__cr.reloadPic函数,那这个肯定是和图片重新加载有关的函数了,那就看看函数里面的代码,果不其然,有个重大嫌疑的函数__cr.getPicUrl(i),如果那这个肯定就是获取图片链接的函数了,那我们就去这个函数的定义看看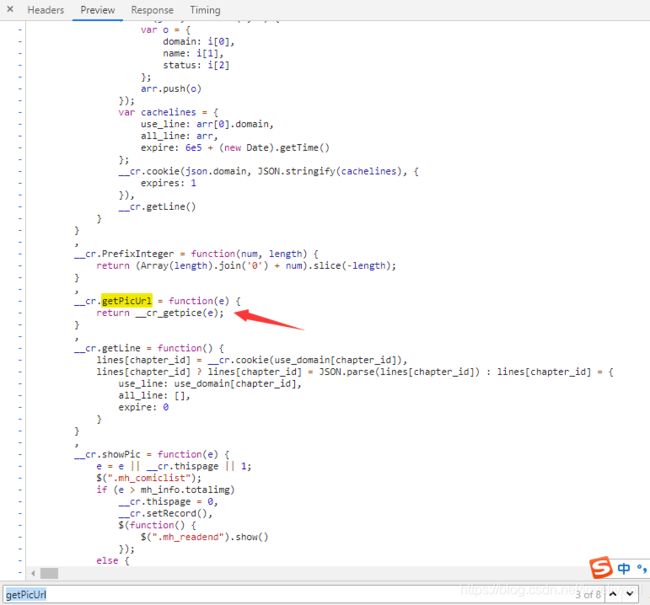
然后找到了这个函数__cr_getpice(e),但是这个函数不是在这个js文件里面定义的,那我们就进入控制台的Source给这一行打上断点看看
不过看起来代码是被压缩了的,那就点击下角的那个大括号,代码就会自动格式化了,那我就翻到断点的位置,打上断点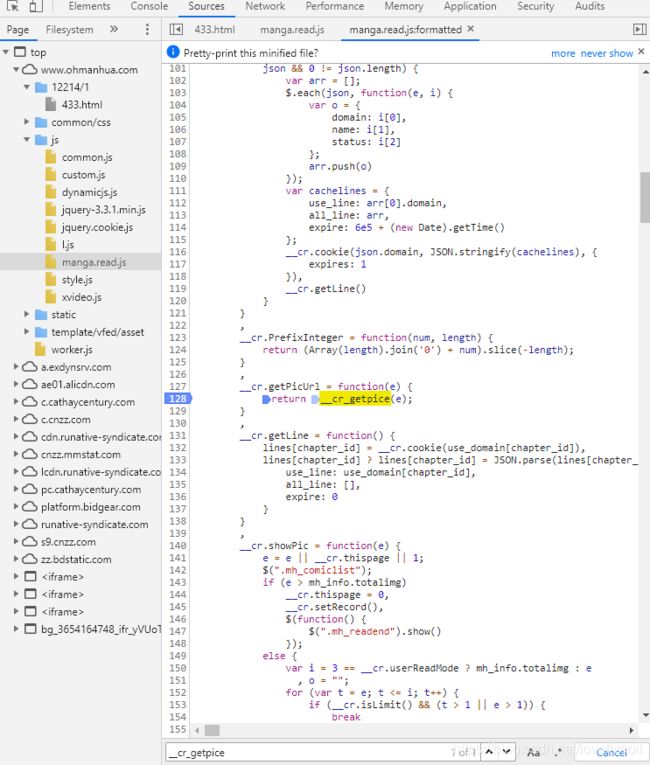
然后刷新页面,JS会在这一行停下来,我们就点击下图右上角的四个键来调试JS,这四个按键的作用网上是有解释,那我就再废话一下吧,第一个是执行到下一个断点;第二个是顺序执行,但是不会执行函数内部的代码,直接到下一行;第三个就是真正意义上的debug了,一步步的执行,会进入函数内部;第四个则是跳出函数,比如你进入了一个父函数里的子函数里面,那你点击这个就从子函数跳出来了直接跑到父函数了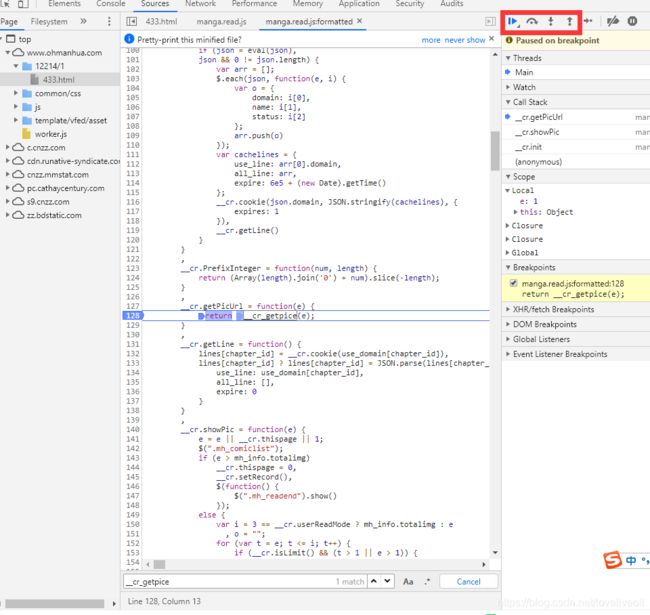
因为我们肯定是想进入__cr.getPicUrl(e)的子函数__cr_getpice(e)里面的,所以就按第三个键,进入__cr_getpice(e)这个关键函数里面,会发现函数进入了custom.js这个文件里面
那我们就继续顺序执行,大概执行完第1057行的代码后,会在控制台的值发现_0xbb43x7b已经变成了一个图片链接的,而这个这个就是漫画图片的链接了,那我们现在关注的重点就是1057行的变量_0xbb43x7b的赋值代码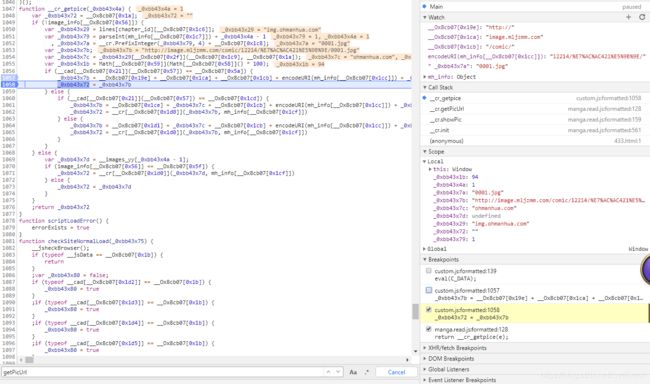
这个赋值的完整代码是:
_0xbb43x7b = __Ox8cb07[0x19e] + __Ox8cb07[0x1ca] + __Ox8cb07[0x1cb] + encodeURI(mh_info[__Ox8cb07[0x1cc]]) + _0xbb43x7a;
我们先在右边的watch里面加上赋值参数里的__Ox8cb07[0x1d1],_0xbb43x7c,__Ox8cb07[0x1cb],encodeURI(mh_info[__Ox8cb07[0x1cc]]),以及_0xbb43x7a,看看这四个值都是多少
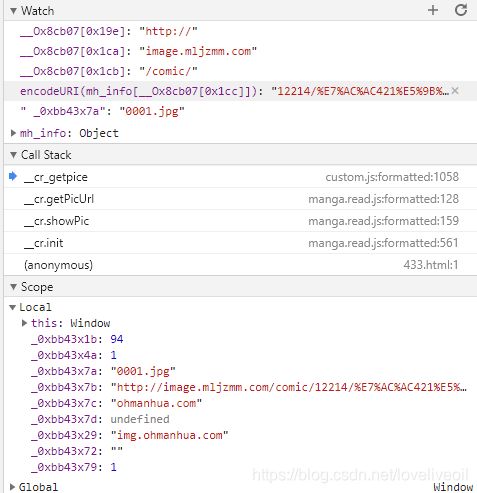
然后能看出除了encodeURI(mh_info[__Ox8cb07[0x1cc]])以外的都应该是固定的常数,因为我通过查看很多的漫画图片链接后分析得出,前三个数是固定的,然后最后一个参数就是_0xbb43x7a是改变图片索引的参数(就是第几张图片啦)。然后呢最关键的encodeURI(mh_info[__Ox8cb07[0x1cc]])是把mh_info[__Ox8cb07[0x1cc]]给解码成url式的编码,那就看看mh_info这个变量在哪执行逻辑的
但令我费解的是我找遍了全文件也没有找到mh_info的定义,当时这个耗费我好大的精力,都快要放弃了,最后我偶然间在217行发现了一个showImg函数
我感觉这个函数肯定也是和图片有关系的,那就关闭其他的断点直接把断点放到这一行并运行
但是呢发现这个函数并不是我需要的,因为这里传入的参数已经是图片的链接了,不过我却发现有个eval的函数好像很有意思,我因为没学过JS就以为是个去除字符串的函数(Python里面的),结果从网上搜原来是执行JS代码的函数,,,在此我为我的学疏才浅道歉,那说明mh_info十有八九就是在这里面定义的,然后我们就再文件里面找eval函数的代码,果不其然,在139行找到了一个很好康的代码
哈哈找到了,mh_info就是在这C_DATA里面定义的![]()
那就直接在这个函数打上打上断点,刷新页面到了下面这一步![]()
可以发现C_DATA本来是个传入值,在函数里被__cdecrypt重新赋值了,而__cdecrypt这个函数传入了两个参数,第一个参数__READKEY就是个常数 JRUIFMVJDIWE569j,第二个参数就很有意思了![]()
可以看出应该是把C_DATA经过加密后的参数,而这个加密函数CryptoJS,是不是很熟悉,我之前写的那个爬取网易云音乐搜索和评论的博客,网易云音乐的参数加密就是用这个CryptoJS,然后我们看看这个是经过CryptoJS某些操作得到的值,但这样写的我们明显看不懂,先watch一下里面的值是多少
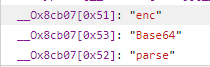 这就对了
这就对了
可以看出这个CryptoJS函数实际是:
CryptoJS.enc.Base64.parse(C_DATA).toString(CryptoJS.enc.Utf8)
很简单了,就是把C_DATA用Base64解密一下,这个才Python和Java里面能轻松实现。接着就是传入的参数C_DATA是多少的的问题,这个经过我的观察,C_DATA就是前言中访问页面得到html代码里面的,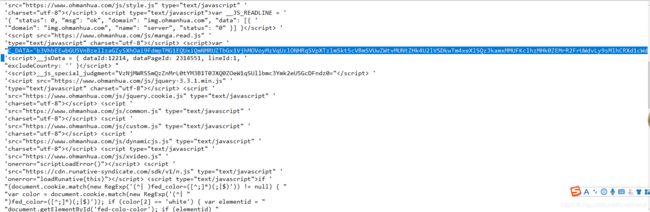
C_DATA问题解决了就直接进入关键函数__cdecrypt()看看里面是什么样的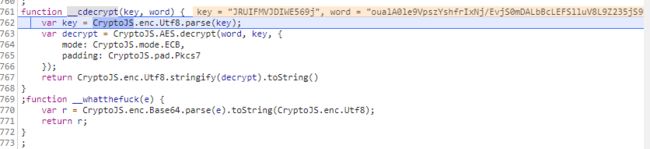
然后这个就好办了,我之前说了网易云音乐就是用这个加密的,而且这个比网易云要简单一点儿网易云的那个是两次加密而且是CBC模式,这个只是ECB加密而且加密一次就行了,这样得到的C_DATA里面就定义了mh_info这个关键参数。那么现在继续我们刚才卡壳的地方,在1049行设断点并刷新网页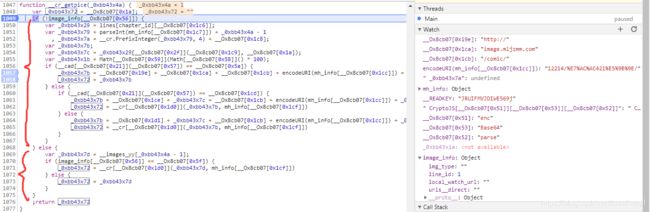
如果你观察仔细,你会发现这个if语句的选择与image_info[__Ox8cb07[0x56]],而if语句执行的不同决定了图片网址的不同,而且更令人头皮发麻的是,if语句里面还有个if_else语句,不过经过我后来的测试,这个里面的if_else语句不影响我们的处理,那我们就钻研一下最外面的if_else语句
先来看看判断条件,![]() 这个实际上是image_info[“img_type”] 值的的判断,如果值为空就进入if函数否则就在else中处理
这个实际上是image_info[“img_type”] 值的的判断,如果值为空就进入if函数否则就在else中处理
这里就是分歧点了,经过我的反复查看不同漫画图片的网址发现,这个oh漫画里面的图片链接有两种格式,一种是http://image.mljzmm.com/comic/ 开头的,还有一种是C_DATA里面的urls__direct对应的值,可能说的有点儿抽象,反正简单来说这个if语句就是决定图片链接格式的,由于不同的漫画传入的C_DATA不同,经过AES解密后的数据也不同,数据不同就体现在image_info[‘img_type’] 的不同,有的漫画是能返回完整链接的,而image_info[‘img_type’] 值为空的,image_info[‘urls__direct’] 值也为空,那这个图片链接经过if语句的处理后变成了http://image.mljzmm.com/comic/ 开头,加上encodeURI(mh_info[“imgpath”]) ,结尾再加上0001.jpg(图片索引);反之,如果image_info[‘img_type’] 值不为空那image_info[‘urls__direct’] 里面的值就是所有的图片链接(当然要separate一下)。
功能实现代码[Python/Java]
老实说,写爬虫肯定还是Python舒服一点,但因为我要做一个APP,那没办法了只能也写个JAVA版的了
Python3版代码
# -*- coding: utf-8 -*-
from Crypto.Cipher import AES
import base64
import re
import requests
from pprint import pprint
from urllib import parse
from Crypto.Util.Padding import pad
headers = {
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'navigate',
'Referer': 'https://www.ohmanhua.com/',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
class AesCrypt:
def __init__(self, model, iv, encode_, key='JRUIFMVJDIWE569j'):
self.encrypt_text = ''
self.decrypt_text = ''
self.encode_ = encode_
self.model = {
'ECB': AES.MODE_ECB, 'CBC': AES.MODE_CBC}[model]
self.key = self.add_16(key)
if model == 'ECB':
self.aes = AES.new(self.key, self.model) # 创建一个aes对象
elif model == 'CBC':
self.aes = AES.new(self.key, self.model, iv) # 创建一个aes对象
# 这里的密钥长度必须是16、24或32,目前16位的就够用了
def add_16(self, par):
par = par.encode(self.encode_)
while len(par) % 16 != 0:
par += b'\x00'
return par
# 加密
def aesencrypt(self, text):
text = pad(text.encode('utf-8'), AES.block_size, style='pkcs7')
self.encrypt_text = self.aes.encrypt(text)
return base64.encodebytes(self.encrypt_text).decode().strip()
# 解密
def aesdecrypt(self, text):
text = base64.decodebytes(text.encode(self.encode_))
self.decrypt_text = self.aes.decrypt(text)
return self.decrypt_text.decode(self.encode_).strip('\0').strip("\n")
def get_img_url(C_DATA,__READKEY ="JRUIFMVJDIWE569j"):
try:
decrypt_data = base64.b64decode(C_DATA).decode("utf-8")
except:
decrypt_data = C_DATA
first_result = AesCrypt("ECB", "", "utf-8",'JRUIFMVJDIWE569j')
mh_info = first_result.aesdecrypt(decrypt_data)
#print(mh_info)
C_DATA = re.findall('urls__direct:"(.+?)"', mh_info)[0]
#print(C_DATA)
try:
final_data = base64.b64decode(C_DATA).decode("utf-8")
direct_urls = final_data.split('|SEPARATER|')
except :
final_data = mh_info
total_pages = re.findall('totalimg:(\d+)',final_data)[0]
#print(total_pages)
direct_urls = []
direct_url = 'http://image.mljzmm.com/comic/' + parse.quote(re.findall('imgpath:"(.+/)"',final_data)[0])
for i in range(int(total_pages)+1)[1:]:
if i < 10:
url = direct_url + "000"+str(i) +".jpg"
elif i <100:
url = direct_url + "00"+str(i) +".jpg"
elif i <1000:
url = direct_url + "0"+str(i) +".jpg"
direct_urls.append(url)
return direct_urls
if __name__ == '__main__':
html = requests.get("https://www.ohmanhua.com/10136/2/483.html",headers=headers).text
C_DATA = re.findall('C_DATA=\'(.+?)\'',html)[0]
print(C_DATA)
pprint(get_img_url(C_DATA))
img = requests.get(get_img_url(C_DATA)[0], headers=headers)
img = img.content
with open( './a.jpg','wb' ) as f:
f.write(img)
JAVA版代码
package love;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.net.URL;
import java.net.URLConnection;
import java.net.URLEncoder;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import javax.crypto.Cipher;
import javax.crypto.spec.SecretKeySpec;
import org.apache.commons.codec.binary.Base64;
import org.jsoup.Jsoup;
/**
*
* @author Administrator
*
*/
public class AES {
// 加密
public static String Encrypt(String sSrc, String sKey) throws Exception {
if (sKey == null) {
System.out.print("Key为空null");
return null;
}
// 判断Key是否为16位
if (sKey.length() != 16) {
System.out.print("Key长度不是16位");
return null;
}
byte[] raw = sKey.getBytes("utf-8");
SecretKeySpec skeySpec = new SecretKeySpec(raw, "AES");
Cipher cipher = Cipher.getInstance("AES/ECB/PKCS5Padding");//"算法/模式/补码方式"
cipher.init(Cipher.ENCRYPT_MODE, skeySpec);
byte[] encrypted = cipher.doFinal(sSrc.getBytes("utf-8"));
return new Base64().encodeToString(encrypted);//此处使用BASE64做转码功能,同时能起到2次加密的作用。
}
// 解密
public static String Decrypt(String sSrc, String sKey) throws Exception {
try {
// 判断Key是否正确
if (sKey == null) {
System.out.print("Key为空null");
return null;
}
// 判断Key是否为16位
if (sKey.length() != 16) {
System.out.print("Key长度不是16位");
return null;
}
byte[] raw = sKey.getBytes("utf-8");
SecretKeySpec skeySpec = new SecretKeySpec(raw, "AES");
Cipher cipher = Cipher.getInstance("AES/ECB/PKCS5Padding");
cipher.init(Cipher.DECRYPT_MODE, skeySpec);
byte[] encrypted1 = new Base64().decode(sSrc);//先用base64解密
try {
byte[] original = cipher.doFinal(encrypted1);
String originalString = new String(original,"utf-8");
return originalString;
} catch (Exception e) {
System.out.println(e.toString());
return null;
}
} catch (Exception ex) {
System.out.println(ex.toString());
return null;
}
}
public static void main(String[] args) throws Exception {
/*
* 此处使用AES-128-ECB加密模式,key需要为16位。
*/
String manga_html = Jsoup.connect("https://www.ohmanhua.com/10136/2/483.html")
.cookie("UM_distinctid", "173758ac0ae7de-0c2d06dbac42fc-7711a3e-1fa400-173758ac0afbf6")
.cookie("CNZZDATA1278861449", "711021447-1595403451-%7C1595403451")
.header("Referer", "https://www.ohmanhua.com/")
.header("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36")
.get().toString();
String REGEX = "C_DATA='(\\S+?)'";
Pattern p = Pattern.compile(REGEX);
Matcher m = p.matcher(manga_html); // 获取 matcher 对象
String new_url="";
if(m.find()) {
String[] urls = get_Decrypt(m.group(1)).split("\\|SEPARATER\\|");
for (int i=0;i<urls.length;i++) {
System.out.println(urls[i]);
}
//此时的链接不能直接访问,因为可能有中文名(但在python里用requests倒可以) ,所以要用下面的函数转化成url编码我这里只转化了一个并把图片下载到本地
new_url=URLEncoder.encode(urls[0],"UTF-8").replaceAll("\\+", "%20").replaceAll("%2F", "/").replaceAll("%3A", ":");
System.out.println("可访问的链接是:"+new_url);
}
//把图片下载到本地
URL url1 = new URL(new_url);
URLConnection uc = url1.openConnection();
InputStream inputStream = uc.getInputStream();
FileOutputStream out = new FileOutputStream("a.jpg");
int j = 0;
while ((j = inputStream.read()) != -1) {
out.write(j);
}
inputStream.close();
out.close();
}
public static String get_Decrypt(String C_DATA) throws Exception {
String cKey = "JRUIFMVJDIWE569j";
byte[] decoded = java.util.Base64.getDecoder().decode(C_DATA);
String content = new String(decoded);
String DeString = AES.Decrypt(content, cKey);
//System.out.println("转换的结果是:"+DeString);
String REGEX = "urls__direct:\"(.*?)\"";
Pattern p = Pattern.compile(REGEX);
Matcher m = p.matcher(DeString); // 获取 matcher 对象
if(m.find()) {
if (m.group(1).length() != 0) {
decoded = java.util.Base64.getDecoder().decode(m.group(1));
content = new String(decoded, "UTF-8");
return content;
}else {
String domain = "http://image.mljzmm.com/comic/";
REGEX = "imgpath:\"(.+)\".*totalimg:(\\d+).*";
p = Pattern.compile(REGEX);
m = p.matcher(DeString); // 获取 matcher 对象
if(m.find()) {
//int page_count = Integer.parseInt(m.group(1));
System.out.println();
int pic_count = Integer.parseInt(m.group(2));
String url = domain + URLEncoder.encode(m.group(1),"UTF-8").replaceAll("\\+", "%20").replaceAll("%2F", "/").replaceAll("%3A", ":");
String urls="";
for (int i=1;i <= pic_count;i++) {
if (i<10){
urls = urls + url + "000" + i + ".jpg" + "|SEPARATER|";
}else if (i<100) {
urls = urls + url + "00" + i + ".jpg" + "|SEPARATER|";
}else {
urls = urls + url + "0" + i + ".jpg" + "|SEPARATER|";
}
}
return urls;
}
}
}
return null;
}
}
要用的库有Jsoup和commons-codec-1.14,下载链接:
jsoup-1.13.1.jar
commons-codec-1.14.jar
PS:可能有用java8人运行这个程序可能会报这样的错: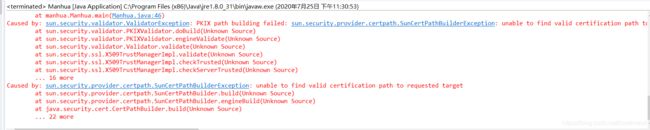
这个应该只在极少数人的电脑中才会报错,当然我就中招了,这个是因为jre版本的问题,可以下载这个Java8版本的jre:jdk1.8.zip