Python
Python是如何进行内存管理的?
Python得解释器负责的;对python语言来讲,对象的类型和内存都是在运行时确定的。这也是为什么我们称python语言为动态类型的原因。
引用计数为主,标记-清除和分代回收主要是为了处理循环引用的难题。
1.对象的引用计数机制;2.垃圾回收机制;3.内存池
python内部使用引用计数,来保持追踪内存中的对象,Python内部记录了对象有多少个引用,即引用计数,当对象被创建时就创建了一个引用计数,当对象不再需要时,这个对象的引用计数为0时,它被垃圾回收。所有这些都是自动完成
一、对象的引用计数机制
Python内部使用引用计数,来保持追踪内存中的对象,所有对象都有引用计数。
引用计数增加的情况:
1,一个对象分配一个新名称
2,将其放入一个容器中(如列表、元组或字典)
引用计数减少的情况:
1,使用del语句对对象别名显示的销毁
2,引用超出作用域或被重新赋值
sys.getrefcount( )函数可以获得对象的当前引用计数
多数情况下,引用计数比你猜测得要大得多。对于不可变数据(如数字和字符串),解释器会在程序的不同部分共享内存,以便节约内存。
二、垃圾回收
1,当一个对象的引用计数归零时,它将被垃圾收集机制处理掉。
2,当两个对象a和b相互引用时,del语句可以减少a和b的引用计数,并销毁用于引用底层对象的名称。然而由于每个对象都包含一个对其他对象的应用,因此引用计数不会归零,对象也不会销毁。(从而导致内存泄露)。为解决这一问题,解释器会定期执行一个循环检测器,搜索不可访问对象的循环并删除它们。
三、内存池机制
python提供了对内存的垃圾收集机制,但是它将不用的内存放到内存池而不是返回给操作系统。
1,Pymalloc机制。为了加速Python的执行效率,Python引入了一个内存池机制,用于管理对小块内存的申请和释放。
2,Python中所有小于256个字节的对象都使用pymalloc实现的分配器,而大的对象则使用系统的malloc。
3,对于Python对象,如整数,浮点数和List,都有其独立的私有内存池,对象间不共享他们的内存池。
python的内存机制成金字塔形:第-1,-2层主要有操作系统进行操作;第0层是C中的malloc,free等内存分配和释放函数进行操作;第1层和第2层是内存池,有python的接口函数PyMem_Malloc函数实现,当对象小于256字节时由该层直接分配内存;第三层是最上层,也就是我们对python对象的直接操作;
什么是lambda函数?它有什么好处?
匿名函数,利用回调使用;lambda是一个表达式,而并非语句;因为lambda是一个表达式,所以在python语言中可以出现在def语句所不能出现的位置上;lambda与def语句相比较,后者必须在一开始就要将新函数命名;而前者返回一个新函数,可以有选择性的赋值变量名;lambda主体只是单个表达式,并而一个代码块。
“lambda有起到速写函数的作用,允许在使用的代码内嵌入一个函数的定义。在仅需要嵌入一小段可执行代码的情况 下,就可以带来更简洁的代码结构。”
当程序代码很短,且该函数只使用一次,为了程序的简洁,及节省变量内存占用空间,引入了匿名函数这个概念
请写出一段Python代码实现删除一个list里面的重复元素
答:
1,使用set函数,set(list)
2,使用循环,加入另一个列表 if i not in list:newlist.append(i)
[L2.append(i) for i in L1 if i not in L2]
Python里面如何拷贝一个对象?(赋值,浅拷贝,深拷贝的区别)
答:赋值(=),就是创建了对象的一个新的引用,修改其中任意一个变量都会影响到另一个。对象赋值实际上是对象的引用。当创建一个对象,然后把它赋给另一个变量的时候,python并没有拷贝这个对象,而只是拷贝了这个对象的引用
浅拷贝:创建一个新的对象,但它包含的是对原始对象中包含项的引用(如果用引用的方式修改其中一个对象,另外一个也会修改改变){1,完全切片方法;2,工厂函数,如list();3,copy模块的copy()函数}。浅拷贝没有拷贝子对象,所以原对象发生改变,其子对象也发生了改变,
深拷贝:创建一个新的对象,并且递归的复制它所包含的对象(修改其中一个,另外一个不会改变){copy模块的deep.deepcopy()函数};而深拷贝拷贝了子对象,原对象发生改变,其本身也不会改变。
python中copy和deepcopy区别
1、复制不可变数据类型,不管copy还是deepcopy,都是同一个地址当浅复制的值是不可变对象(数值,字符串,元组)时和=“赋值”的情况一样,对象的id值与浅复制原来的值相同。
2、复制的值是可变对象(列表和字典)
浅拷贝copy有两种情况:
第一种情况:复制的 对象中无复杂 子对象,原来值的改变并不会影响浅复制的值,同时浅复制的值改变也并不会影响原来的值。原来值的id值与浅复制原来的值不同。
第二种情况:复制的对象中有复杂子对象 (例如列表中的一个子元素是一个列表), 改变原来的值中的复杂子对象的值 ,会影响浅复制的值。
深拷贝deepcopy:完全复制独立,包括内层列表和字典
介绍一下except的用法和作用?
try…except…except…[else…][finally…]
执行try下的语句,如果引发异常,则执行过程会跳到except语句。对每个except分支顺序尝试执行,如果引发的异常与except中的异常组匹配,执行相应的语句。如果所有的except都不匹配,则异常会传递到下一个调用本代码的最高层try代码中。try下的语句正常执行,则执行else块代码。如果发生异常,就不会执行如果存在finally语句,最后总是会执行。
Python中pass语句的作用是什么?
答:pass语句不会执行任何操作,一般作为占位符或者创建占位程序,whileFalse:pass
介绍一下Python下range()函数的用法?
答:列出一组数据,经常用在for in range()循环中
如何用Python来进行查询和替换一个文本字符串?
答:可以使用re模块中的sub()函数或者subn()函数来进行查询和替换
格式:sub(replacement, string[,count=0])(replacement是被替换成的文本,string是需要被替换的文本,count是一个可选参数,指最大被替换的数量)
import re
p=re.compile(''red|blue|black')
print(p.sub('color','blue shoes and red skirts')
print(p.sub(‘colour’,'blue socks and red shoes’, count=1))
输出:
colour socks and colour shoes
colour socks and red shoes
**subn()方法执行的效果跟sub()一样,不过它会返回一个二维数组,包括替换后的新的字符串和总共替换的数量**
例如:
import re
p = re.compile(‘(blue|white|red)’)
print(p.subn(‘colour’,'blue socks and red shoes’))
print(p.subn(‘colour’,'blue socks and red shoes’, count=1))
输出
(‘colour socks and colour shoes’, 2)
(‘colour socks and red shoes’, 1)
字符串:
.find();.replace()
words = 'Python is a very funny language!'
>>> words.find('Python') # 返回的为0或正数时,为其索引号
0
>>> words.find('is')
7
>>> words.find('dafa') # 返回-1表示查找失败
-1
>>> words.replace('Python', 'Perl') # replace()替换
'Perl is a very funny language!'
Python里面match()和search()的区别?
答:re模块中match(pattern,string[,flags]),检查string的开头是否与pattern匹配。也就是说match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回none
re模块中research(pattern,string[,flags]),在string搜索pattern的第一个匹配值。
用Python匹配HTML tag的时候,<.>和<.?>有什么区别?
答:术语叫贪婪匹配( <.> )尽可能多的匹配和非贪婪匹配(<.?>)匹配少的
例如:
test
<.*> :test
<.*?> :
Python里面如何生成随机数?
答:random模块
随机整数:random.randint(a,b):返回随机整数x,a<=x<=b
random.randrange(start,stop,[,step]):返回一个范围在(start,stop,step)之间的随机整数,不包括结束值。
随机实数:random.random( ):返回0到1之间的浮点数
random.uniform(a,b):返回指定范围内的浮点数。
python中生成随机整数、随机小数、0–1之间小数方法
随机整数:random.randint(a,b),生成区间内的整数
随机小数:习惯用numpy库,利用**numpy.random.randn(5)**生成5个随机小数
0-1随机小数:random.random(),括号中不传参
import random
random.randint(a,b)
random.randrange(start,stop,[,step])
random.random()
random.uniform(a,b)
有没有一个工具可以帮助查找python的bug和进行静态的代码分析?
答:PyChecker是一个python代码的静态分析工具,它可以帮助查找python代码的bug, 会对代码的复杂度和格式提出警告**;PyChecker会导入所检查文件中包含的模块,检查导入是否正确,同时检查文件中的函数、类和方法等。
Pylint是另外一个工具可以进行codingstandard检查,Pylint是一个高阶的Python代码分析工具,它分析Python代码中的错误,查找不符合代码风格标准**(Pylint 默认使用的代码风格是 PEP 8)和有潜在问题的代码。
https://blog.csdn.net/permike/article/details/51026156
如何在一个function里面设置一个全局的变量?
答:解决方法是在function的开始插入一个global声明:
def f()
global x
单引号,双引号,三引号的区别
答:单引号和双引号是等效的,如果要换行,需要符号(),三引号则可以直接换行,并且可以包含注释
如何用Python来发送邮件?
可以使用smtplib标准库。
先初始化SMTPserver,sender,password,定义mailserver=smtplib.SMTP(self.SMTPServer,25),mailserver.login;
定义sendmail方法sendmail(self,message,title, receiver),msg;mailserver.sendmail()
定义exit;mailserver.quit()
import smtplib
from email.mime.text import MIMEText
class sendemail():
def __init__(self,SMTPserver,sender,password):
self.SMTPserver = SMTPserver
self.sender = sender
self.password = password
self.mailserver = smtplib.SMTP(self.SMTPserver,25)
self.mailserver.login(self.sender,self.password)
def sendmail(self,message,title, receiver):
msg = MIMEText(message)
msg['subject']=title
msg['From']=self.sender
msg['To']=receiver
self.mailserver.sendmail(self.sender,receiver,msg.as_string())
def exit(self):
self.mailserver.quit()
sendemail1=sendemail('','','')
sendemail1.sendmail('','','')
sendemail1.exit()
Python如何实现单例模式?
单例模式(Singleton Pattern)的主要目的是确保某一个类只有一个实例存在。
实现单例模式的几种方式
1.使用模块:因为模块在第一次导入时,会生成 .pyc 文件,当第二次导入时,就会直接加载 .pyc 文件,而不会再次执行模块代码。因此,我们只需把相关的函数和数据定义在一个模块中,就可以获得一个单例对象了。
2.使用装饰器:@Singleton
单例类本身根本不知道自己是单例的,因为他本身(自己的代码)并不是单例的
函数装饰器
def singleton(cls):
_instance = {}
def inner():
if cls not in _instance:
_instance[cls] = cls()
return _instance[cls]
return inner
@singleton
class Cls(object):
def __init__(self):
pass
类装饰器
class Singleton(object):
def __init__(self, cls):
self._cls = cls
self._instance = {}
def __call__(self):
if self._cls not in self._instance:
self._instance[self._cls] = self._cls()
return self._instance[self._cls]
@Singleton
class Cls2(object):
def __init__(self):
pass
cls1 = Cls2()
cls2 = Cls2()
print(id(cls1) == id(cls2))
3.使用类:为了保证线程安全需要在内部加入锁
4.基于__new__方法实现(推荐使用,方便):实例化一个对象时,是先执行了类的__new__方法(我们没写时,默认调用object.new),实例化对象;然后再执行类的__init__方法,对这个对象进行初始化
实现__new__方法
#并在将一个类的实例绑定到类变量_instance上,
#如果cls._instance为None说明该类还没有实例化过,实例化该类,并返回
#如果cls._instance不为None,直接返回cls._instance
class Single(object):
_instance = None
def __new__(cls, *args, **kw):
if cls._instance is None:
cls._instance = object.__new__(cls, *args, **kw)
return cls._instance
def __init__(self):
pass
single1 = Single()
single2 = Single()
print(id(single1) == id(single2))
5.基于metaclass方式实现:metaclass = Singleton;将 metaclass 指向 Singleton 类,让 Singleton 中的 type 来创造新的 MyClass3实例。
class Singleton(type):
_instances = {}
def __call__(cls, *args, **kwargs):
if cls not in cls._instances:
cls._instances[cls] = super(Singleton, cls).__call__(*args, **kwargs)
return cls._instances[cls]
class MyClass3(object):
__metaclass__ = Singleton
cls1 = Cls4()
cls2 = Cls4()
print(id(cls1) == id(cls2))
python程序中文输出问题怎么解决?
在Python3中,对中文进行了全面的支持,但在Python2.x中需要进行相关的设置才能使用中文。否则会出现乱码。
Python默认采取的ASCII编码,字母、标点和其他字符只使用一个字节来表示,但对于中文字符来说,一个字节满足不了需求。
为了能在计算机中表示所有的中文字符,中文编码采用两个字节表示。如果中文编码和ASCII混合使用的话,就会导致解码错误,从而才生乱码。
解决办法:
1.交互式命令中:一般不会出现乱码,无需做处理
2.py脚本文件中:设置系统默认编码
#!/usr/bin/env python
#coding=utf-8
#!/usr/bin/ env python -*- coding:UTF-8 -*-
3.其次需将文件保存为UTF-8的格式!
4. 最后: s.decode(‘utf-8’).encode(‘gbk’)
用encode和decode
decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode(‘gb2312’),表示将gb2312编码的字符串str1转换成unicode编码。
encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode(‘gb2312’),表示将unicode编码的字符串str2转换成gb2312编码。
python代码得到列表list的交集与差集
交集
b1=[1,2,3]
b2=[2,3,4]
b3 = [val for val in b1if val in b2]
print b3
res=set(b1).intersection(set(b2))
差集
b1=[1,2,3]
b2=[2,3,4]
b3 = [val for val in b1 if val not in b2]
print b3
res=set(b1).difference(set(b2))#b1有b2没有
并集
res=set(b1).union(set(b2))
写一个简单的python socket编程
python 编写server的步骤:
1第一步是创建socket对象。调用socket构造函数。如:socket = socket.socket(family, type )
family参数代表地址家族,可为AF_INET或AF_UNIX。AF_INET家族包括Internet地址,AF_UNIX家族用于同一台机器上的进程间通信。type参数代表套接字类型,可为SOCK_STREAM(流套接字,TCP)和SOCK_DGRAM(数据报套接字,UDP)。
2.第二步是将socket绑定到指定地址。这是通过socket对象的bind方法来实现的:
socket.bind( address )由AF_INET所创建的套接字,address地址必须是一个双元素元组,格式是(host,port)。host代表主机,port代表端口号。如果端口号正在使用、主机名不正确或端口已被保留,bind方法将引发socket.error异常。
3.第三步是使用socket套接字的listen方法接收连接请求。socket.listen( backlog )
backlog指定最多允许多少个客户连接到服务器。它的值至少为1。收到连接请求后,这些请求需要排队,如果队列满,就拒绝请求。
4.第四步是服务器套接字通过socket的accept方法等待客户请求一个连接。
connection, address =socket.accept()
调用accept方法时,socket会时入“waiting”状态。客户请求连接时,方法建立连接并返回服务器。accept方法返回一个含有两个元素的元组(connection,address)。第一个元素connection是新的socket对象,服务器必须通过它与客户通信;第二个元素address是客户的Internet地址。
5. 第五步是处理阶段,服务器和客户端通过send和recv方法通信(传输数据)。服务器调用send,并采用字符串形式向客户发送信息。send方法返回已发送的字符个数。服务器使用recv方法从客户接收信息。调用recv 时,服务器必须指定一个整数,它对应于可通过本次方法调用来接收的最大数据量。recv方法在接收数据时会进入“blocked”状态,最后返回一个字符串,用它表示收到的数据。如果发送的数据量超过了recv所允许的,数据会被截短。多余的数据将缓冲于接收端。以后调用recv时,多余的数据会从缓冲区删除(以及自上次调用recv以来,客户可能发送的其它任何数据)。
6. 传输结束,服务器调用socket的close方法关闭连接。
python编写client的步骤:
1 创建一个socket以连接服务器:socket= socket.socket( family, type )
2 使用socket的connect方法连接服务器。对于AF_INET家族,连接格式如下:socket.connect((host,port) )
host代表服务器主机名或IP,port代表服务器进程所绑定的端口号。如连接成功,客户就可通过套接字与服务器通信,如果连接失败,会引发socket.error异常。
3 处理阶段,客户和服务器将通过send方法和recv方法通信。
4 传输结束,客户通过调用socket的close方法关闭连接。
server.py
import socket
tcpserver=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
tcpserver.bind(('127.0.0.1',9988))#"10.10.153.45",9988
tcpserver.listen(5)#最多收5个客户端
clientconnection,clientaddr=tcpserver.accept() #返回链接,返回地址
while True:
recdata=clientconnection.recv(1024)
print('收到',recdata.decode('utf-8'))
senddata=("hello")
clientconnection.send(senddata)
clientconnection.close()
tcpserver.close()
client.py
import socket
tcpclient=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
tcpclient.connect(('127.0.0.1',9988))
while True:
data=input('输入消息')
tcpclient.send(data.encode('utf-8'))
recserverdata=tcpclient.recv(1024)
print(recserverdata.decode("utf-8"))
tcpclient.close() # 关闭
Python文件操作的面试题
import os
import shutil
python中对文件、文件夹(文件操作函数)的操作需要涉及到os模块和shutil模块。
到当前工作目录,即当前Python脚本工作的目录路径: os.getcwd()
返回指定目录下的所有文件和目录名:os.listdir()
函数用来删除一个文件:os.remove()
运行shell命令: os.system()
重命名:os.rename(old, new)
创建多级目录:os.makedirs(r“c:\python\test”)
创建单个目录:os.mkdir(“test”)
删除多个目录:os.removedirs(r“c:\python”)
复制:
shutil.copyfile(“oldfile”,”newfile”) oldfile和newfile都只能是文件
shutil.copy(“oldfile”,”newfile”) oldfile只能是文件夹,newfile可以是文件,也可以是目标目录
复制文件夹:
shutil.copytree(“olddir”,”newdir”) olddir和newdir都只能是目录,且newdir必须不存在
移动文件(目录)
shutil.move(“oldpos”,”newpos”)
删除目录
os.rmdir(“dir”)只能删除空目录
shutil.rmtree(“dir”) 空目录、有内容的目录都可以删
转换目录
os.chdir(“path”) 换路径
- 如何用Python删除一个文件?
import os
os.remove(filename)
使用os.remove(filename)或者os.unlink(filename);
2. Python如何copy一个文件?
shutil模块有一个copyfile函数可以实现文件拷贝
import shutil
shutil.copyfile('a.py', 'copy_a.py')
https://blog.csdn.net/m0_38059843/article/details/78240835
如何反序的迭代一个序列?how do I iterate over a sequence in reverse order
如果是一个list, 最快的解决方案是:list.reverse()
list.reverse()
try:
for x in list:
“do something with x”
finally:
list.reverse()
如果不是list, 最通用但是稍慢的解决方案是:
for i in range(len(sequence)-1, -1, -1):
x = sequence[i]
有两个序列a,b,大小都为n,序列元素的值任意整形数,无序;要求:通过交换a,b中的元素,使[序列a元素的和]与[序列b元素的和]之间的差最小。 1. 将两序列合并为一个序列,并排序,为序列Source 2. 拿出最大元素Big,次大的元素Small 3. 在余下的序列S[:-2]进行平分,得到序列max,min 4. 将Small加到max序列,将Big加大min序列,重新计算新序列和,和大的为max,小的为min。
Python里面如何拷贝一个对象?
一般来说可以使用**copy.copy()方法或者copy.deepcopy()**方法,几乎所有的对象都可以被拷贝
一些对象可以更容易的拷贝,Dictionaries有一个copy方法
newdict = olddict.copy()
说说你对zen of python的理解,你有什么办法看到它?
Python之禅,Python秉承一种独特的简洁和可读行高的语法,以及高度一致的编程模式,符合“大脑思维习惯”,使Python易于学习、理解和记忆。Python同时采用了一条极简主义的设计理念,了解完整的Python哲学理念,可以在任何一个Python交互解释器中键入import this命令,这是Python隐藏的一个彩蛋:描绘了一系列Python设计原则。“import this”的被定为输出Tim Peter写的《The Zen of Python》——Python编程和设计的指导原则。如今已是Python社区内流行的行话"EIBTI",明了胜于晦涩这条规则的简称. 在Python的思维方式中,明了胜于晦涩,简洁胜于复杂。
说说你对pythonic的看法,尝试解决下面的小问题
所谓Pythonic,就是极具Python特色的Python代码(明显区别于其它语言的写法的代码)
简洁,明了,严谨,灵活
交换变量;[::-1];zip(); .join();
#交换两个变量值
a,b = b,a
#去掉list中的重复元素
old_list = [1,1,1,3,4]
new_list = list(set(old_list))
#翻转一个字符串
s = 'abcde'
ss = s[::-1]
#用两个元素之间有对应关系的list构造一个dict
names = ['jianpx', 'yue']
ages = [23, 40]
m = dict(zip(names,ages))
#将数量较多的字符串相连,如何效率较高,为什么
fruits = ['apple', 'banana']
result = ''.join(fruits)
#python字符串效率问题之一就是在连接字符串的时候使用‘+’号,例如 s = ‘s1’ + ‘s2’ + ‘s3’ + …+’sN’,总共将N个字符串连接起来, 但是使用+号的话,python需要申请N-1次内存空间, 然后进行字符串拷贝。原因是字符串对象PyStringObject在python当中是不可变对象,所以每当需要合并两个字符串的时候,就要重新申请一个新的内存空间 (大小为两个字符串长度之和)来给这个合并之后的新字符串,然后进行拷贝。所以用+号效率非常低。
建议在连接字符串的时候使用字符串本身的方法 join(list),这个方法能提高效率,原因是它只是申请了一次内存空间,因为它可以遍历list中的元素计算出总共需要申请的内存空间的大小,一次申请完。
你调试python代码的方法有哪些?
- 具体IDE都有调试,比如:Pycharm、IDLE, Eclipse+Pydev都可以设置断点调试。
2.pdb模块也可以做调试。https://blog.csdn.net/tuzixini/article/details/79614655
(一)进入pdb调试模式的两种方法:
1.直接在命令行参数指定使用pdb模块启动Python文件
python -m pdb test.py
2.在程序代码中设置断点
首先需要在程序中使用如下语句导入pdb模块:
import pdb
然后再在需要设置断点的地方放置如下断点设置代码:
pdb.set_trace()
(二) 调试程序的方法
进入调试程序后可以使用相应的命令进行指定的操作.
这里介绍几个常用的命令:可以使用命令全称也可以使用缩写
1.使用pdb的命令
next(缩写:n),向下执行一步,
2.直接输入变量名称
还可以直接输入变量的名称查看变量的值
3.使用类的方法查看变量/类的信息(输入表达式)
像数组这种还可以使用类似 i.shape 这样的输入直接调用相关方法,这个拓展就很广了,大家可以自由发挥
- 还有PyChecker和Pylint PyChecker是一个python代码的静态分析工具,它可以帮助查找python代码的bug, 会对代码的复杂度和格式提出警告; Pylint 是另外一个工具可以进行coding standard检查。
你在github上都fork过哪些python库,列举一下你经常使用的,每个库用一句话描述下其功能
http://rogerdudler.github.io/git-guide/index.zh.html #关于git简明指南
http://www.zhihu.com/question/20070065 #关于git的BBS
http://www.techug.com/githug-for-designer #关于github的
简单谈下GIL
Global Interpreter Lock(全局解释器锁)
Python代码的执行由python虚拟机(也叫解释器主循环,CPython版本)来控制,Python在设计之初就考虑到要在解释器的主循环中,同时只有一个线程在执行,即任意时刻,只有一个线程在解释器中运行。对Python虚拟机的访问由全局解释器锁(GIL)来控制,正是这个锁能保证同一时刻只有一个线程在运行。
在多线程环境中,Python虚拟机按以下方式执行:
1.设置GIL
2.切换到一个线程去运行
3.运行:
a.指定数量的字节码指令,或者
b.线程主动让出控制(可以调用time.sleep(0))
4.把线程设置为睡眠状态
5.解锁GIL
6.再次重复以上所有步骤
再调用外部代码(如C/C++扩展函数)的时候,GIL讲会被锁定,直到这个函数结束为止(由于在这期间没有Python的字节码被运行,所以不会做线程切换)。
GIL 是python的全局解释器锁,同一进程中假如有多个线程运行,一个线程在运行python程序的时候会霸占python解释器(加了一把锁即GIL),使该进程内的其他线程无法运行,等该线程运行完后其他线程才能运行。如果线程运行过程中遇到耗时操作,则解释器锁解开,使其他线程运行。所以在多线程中,线程的运行仍是有先后顺序的,并不是同时进行。
多进程中因为每个进程都能被系统分配资源,相当于每个进程有了一个python解释器,所以多进程可以实现多个进程的同时运行,缺点是进程系统资源开销大!
什么是元类(meta_class)?
元类就是用来创建类的“东西”;根据metaclass创建出类,所以:先定义metaclass,然后创建类。
所以,metaclass允许你创建类或者修改类。换句话说,你可以把类看成是metaclass创建出来的“实例”。
而在python中,它们要么是类的实例,要么是元类的实例,除了type。type实际上是它自己的元类。元类主要的用途是用来创建API,比如django的ORM。
Python是一种动态语言,而动态语言和静态语言最大的不同,就是函数和类不是编译时定义的,而是运行时动态创建的。class的定义是运行时动态创建的,而创建class的方法就是使用type()函数。
定义:type(类名, 父类的元组(针对继承的情况,可以为空),包含属性的字典(名称和值))
那么要创建一个class对象,type()函数需要依次传入3个参数:
class的名称;
继承的父类集合,注意Python支持多重继承,如果只有一个父类,别忘了tuple的单元素写法;
class的方法名称与函数绑定,这里我们把函数helloworld_outside绑定到方法名helloworld上。
对比一下dict中items与iteritems?
D.items() #一次性取出所有
D.iteritems() #迭代对象,每次取出一个。用for循环遍历出来;
总结:
- 一般iteritems()迭代的办法比items()要快,特别是数据库比较大时。
- 在Python3中一般取消前者函数
是否遇到过python的模块间循环引用的问题,如何避免它?
这是代码结构设计的问题,模块依赖和类依赖。 循环引用,很可能是模块的分界线划错地方了。可能是把应该在一起的东西硬拆开了,可能是某些职责放错地方了,可能是应该抽象的东西没抽象 。 总之微观代码规范可能并不能帮到太多,重要的是更宏观的划分模块的经验技巧,推荐uml,脑图,白板等等图形化的工具先梳理清楚整个系统的总体结构和职责分工
采取办法,从设计模式上来规避这个问题,比如:
- 使用 “all” 白名单开放接口 ;如果显式声明了 all,import * 就只会导入 all 列出的成员。
- 尽量避免 import
有用过with statement吗?它的好处是什么?
with expression [as variable]:
with-block
with语句的expression是上下文管理器,with语句中的[as variable]是可选的,如果指定了as variable说明符,则variable是上下文管理器expression调用__enter__()函数返回的对象。所以,f并不一定就是expression,而是expression.enter()的返回值,至于expression.enter()返回什么就由这个函数来决定了。with-block是执行语句,with-block执行完毕时,with语句会自动进行资源清理,对应下面例子就是with语句会自动关闭文件。
with语句的作用是通过某种方式简化异常处理,它是所谓的上下文管理器的一种
用法举例如下:
with open(‘output.txt’, ‘w’) as f:
f.write(‘Hi there!’)
当你要成对执行两个相关的操作的时候,这样就很方便,以上便是经典例子,with语句会在嵌套的代码执行之后,自动关闭文件。这种做法的还有另一个优势就是,无论嵌套的代码是以何种方式结束的,它都关闭文件。如果在嵌套的代码中发生异常,它能够在外部exception handler catch异常前关闭文件。如果嵌套代码有return/continue/break语句,它同样能够关闭文件。
方法一:
上下文管理器就是实现了上下文协议的类,而上下文协议就是一个类要实现**enter()和__exit__()两个方法。一个类只要实现了__enter__()和__exit__(),我们就称之为上下文管理器下面我们具体说下这两个方法。
enter():主要执行一些环境准备工作**,同时返回一资源对象。如果上下文管理器open(“test.txt”)的__enter__()函数返回一个文件对象。
exit():完整形式为__exit__(type, value, traceback),这三个参数和调用sys.exec_info()函数返回值是一样的,分别为异常类型、异常信息和堆栈。如果执行体语句没有引发异常,则这三个参数均被设为None。否则,它们将包含上下文的异常信息。*exit()方法返回True或False,分别指示被引发的异常有没有被处理,如果返回False,引发的异常将会被传递出上下文。如果__exit_()*函数内部引发了异常,则会覆盖掉执行体的中引发的异常。处理异常时,不需要重新抛出异常,只需要返回False,with语句会检测__exit__()返回False来处理异常。如果我们要自定义一个上下文管理器,只需要定义一个类并且是实现__enter__()和__exit__()即可。
Python的contextlib模块给我们提供了更方便的方式来实现一个自定义的上下文管理器。contextlib模块包含一个装饰器contex tmanager和一些辅助函数,装饰器context manager只需要写一个生成器函数就可以代替自定义的上下文管理器
需要使用yield先定义一个生成器函数.
from contextlib import contextmanager
@contextmanager
def some_generator():
try:
yield
finally:
yield之前相当于__enter__,在进入with语句之前执行,yield之后相当于__exit()__,在with语句之后执行
然后便可以用with语句调用contextmanage生成的上下文管理器了,with语句用法如下:
with some_generator() as :
用Python生成指定长度的斐波那契数列
def Fibonacci(n):
# write code here
if n==0:
return 0
if n==1 or n==2:
return 1
else:
return(Fibonacci(n-1)+Fibonacci(n-2))
def Fibonacci(n):
# write code here
if n==0:
return 0
if n==1:
return 1
Fib=[0 for i in range(n+1)]
Fib[0],Fib[1]=0,1
for i in range(2,n+1)://从索引2开始相加
Fib[i]=Fib[i-1]+Fib[i-2]
return Fib[n]
生成器
def fib(n):
a, b = 0, 1
for _ in range(n):
a, b = b, a + b
yield a
def main():
for val in fib(20):
print(val)
if __name__ == '__main__':
main()
Python中如何定义一个函数
def func(arg, *args, **kwagrs): #普通函数
func_body
return
lambda x: x **2 #匿名函数
Python是如何进行类型转换的
函数 描述
int(x [,base]) 将x转换为一个整数
long(x [,base] ) 将x转换为一个长整数
float(x) 将x转换到一个浮点数
complex(real [,imag]) 创建一个复数
str(x) 将对象 x 转换为字符串
repr(x) 将对象 x 转换为表达式字符串
eval(str) 用来计算在字符串中的有效Python表达式,并返回一个对象
tuple(s) 将序列 s 转换为一个元组
list(s) 将序列 s 转换为一个列表
set(s) 转换为可变集合
dict(d) 创建一个字典。d 必须是一个序列 (key,value)元组。
frozenset(s) 转换为不可变集合
chr(x) 将一个整数转换为一个字符
unichr(x) 将一个整数转换为Unicode字符
ord(x) 将一个字符转换为它的整数值
hex(x) 将一个整数转换为一个十六进制字符串
oct(x) 将一个整数转换为一个八进制字符串
如何知道一个Python对象的类型
type()
写一段程序逐行读入一个文本文件,并在屏幕上打印出来
file=open(filename,"rb')
while True:
line=file.readline
if not line:break
print(line.decode('utf-8')
file.close()
Python异常处理介绍一下
-
Python内置异常
Python的异常处理能力是很强大的,它有很多内置异常,可向用户准确反馈出错信息。在Python中,异常也是对象,可对它进行操作。BaseException是所有内置异常的基类,但用户定义的类并不直接继承BaseException,所有的异常类都是从Exception继承,且都在exceptions模块中定义。Python自动将所有异常名称放在内建命名空间中,所以程序不必导入exceptions模块即可使用异常。一旦引发而且没有捕捉SystemExit异常,程序执行就会终止。如果交互式会话遇到一个未被捕捉的SystemExit异常,会话就会终止。
-
用户自定义异常
此外,你也可以通过创建一个新的异常类拥有自己的异常,异常应该是通过直接或间接的方式继承自Exception类。下面创建了一个MyError类,基类为Exception,用于在异常触发时输出更多的信息。
-
异常捕获
当发生异常时,我们就需要对异常进行捕获,然后进行相应的处理。python的异常捕获常用try…except…结构,把可能发生错误的语句放在try模块里,用except来处理异常,每一个try,都必须至少对应一个except。此外,与python异常相关的关键字主要有:
关键字 关键字说明
try/except 捕获异常并处理
pass 忽略异常
as 定义异常实例(except MyError as e)
else 如果try中的语句没有引发异常,则执行else中的语句
finally 无论是否出现异常,都执行的代码
raise 抛出/引发异常
介绍一下Python中的filter方法
filter就像map,reduce,apply,zip等都是内置函数,用C语言实现,具有速度快,功能强大等
filter(function, iterable)
描述:
filter()函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,返回True或False,将返回True的元素放到新列表中。
优点。
用于过滤与函数func()不匹配的值, 类似于SQL中select value != ‘a’
相当于一个迭代器,调用一个布尔函数func来迭代seq中的每个元素,返回一个是bool_seq返 回为True的序列
介绍一下except的用法和作用
try/except: 捕捉由PYTHON自身或写程序过程中引发的异常并恢复
except: 捕捉所有其他异常
except name: 只捕捉特定的异常
except name, value: 捕捉异常及格外的数据(实例)
except (name1,name2) 捕捉列出来的异常
except (name1,name2),value: 捕捉任何列出的异常,并取得额外数据
else: 如果没有引发异常就运行
finally: 总是会运行此处代码
Python判断当前用户是否是root
os.getuid()==0
import os
if os.getuid() != 0: # root账号的uid=0
print os.getuid()
print 'Should run as root account'
else:
print 'Hello, Root!'
介绍一下Python中webbrowser的用法
python的webbrowser模块支持对浏览器进行一些操作
webbrowser模块提供了一个高级接口来显示基于Web的文档,大部分情况下只需要简单的调用open()方法。
webbrowser定义了如下的异常:exception webbrowser.Error, 当浏览器控件发生错误是会抛出这个异常
webbrowser有以下方法:
- webbrowser.open(url[, new=0[, autoraise=1]])
这个方法是在默认的浏览器中显示url, 如果new = 0, 那么url会在同一个浏览器窗口下打开,如果new = 1, 会打开一个新的窗口,如果new = 2, 会打开一个新的tab, 如果autoraise = true, 窗口会自动增长。
- webbrowser.open_new(url)
在默认浏览器中打开一个新的窗口来显示url, 否则,在仅有的浏览器窗口中打开url
- webbrowser.open_new_tab(url)
在默认浏览器中打开一个新的tab来显示url, 否则跟open_new()一样
- webbrowser.get([name]) 根据name返回一个浏览器对象,如果name为空,则返回默认的浏览器
- webbrowser.register(name, construtor[, instance])
注册一个名字为name的浏览器,如果这个浏览器类型被注册就可以用get()方法来获取。
默写尽可能多的str对象的方法
#方法 #描述
S.capitalize() #返回首字母大写的字符串的副本
S.center(width[,fillchar]) #返回一个长度为max(len(S),width),S居中,两侧fillchar填充
S.count(sub[,start[,end]]) #计算子字符串sub的出现次数,可将搜索范围限制为S[start:end]
S.decode([encoding[,error]]) #返回使用给定编码方式的字符串的解码版本,由error指定错误处理方式
S.endswith(suffix[start[,end]]) #检查S是否以suffix结尾,可给定[start:end]来选择匹配的范围
S.expandtabs([tabsize]) #返回字符串的副本,其中tab字符会使用空格进行扩展,可选择tabsize
S.find(sun[,start[,end]]) #返回子字符串sub的第一个索引,不存在则为-1,可选择搜索范围
S.index(sub[,start[,end]]) #返回子字符串sub的第一个索引,不存在则引发ValueError异常.
S.isalnum() #检查字符串是否由字母或数字字符组成
S.isalpha() #检查字符串是否由字母字符组成
S.isdigit() #检查字符串是否由数字字符组成
S.islower() #检查字符串是否由小写字母组成
S.isspace() #检查字符串是否由空格组成
S.istitle() #检查字符串时候首字母大写
S.isupper() #检查字符串是否由大写字母组成
S.join(sequence) #返回其中sequence的字符串元素由S连接的字符串
S.ljust(width[,fillchar]) #返回S副本左对齐的字符串,长度max(len(S),W),右侧fillchar填充
S.lower() #返回所有字符串都为小写的副本
S.lstrip([char]) #向左移除所有char,默认移除(空格,tab,\n)
S.partition(seq) #在字符串中搜索seq并返回
S.replace(old,new[,max]) #将new替换olad,最多可替换max次
S.rfind(sub[,start[,end]]) #返回sub所在的最后一个索引,不存在则为-1,可定搜索范围S[start:end]
S.rindex(sub[,start[,end]]) #返回sub所在的最后一个索引,不存在则会引发ValueError异常。
S.rjust(width[,fillchar]) #返回S副本右对齐的字符串,长度max(len(S),W),左侧fillchar填充
S.rpartition(seq) #同Partition,但从右侧开始查找
S.rstip([char]) #向右移除所有char,默认移除(空格,tab,\n)
S.rsplit(sep[,maxsplit]) #同split,但是使用maxsplit时是从右往左进行计数
S.split(sep[,maxsplit]) #使用sep做为分割符,可使用maxsplit指定最大切分数
S.zfill(width) #在S的左侧以0填充width个字符
S.upper() #返回S的副本,所有字符大写
S.splitlines([keepends]) #返回S中所有行的列表,可选择是否包括换行符
S.startswith(prefix[,start[,end]]) #检查S是否以prefix开始,可用[start,end]来定义范围
S.strip([chars]) #移除所有字符串中含chars的字符,默认移除(空格,tab,\n)
S.swapcase() #返回S的副本,所有大小写交换
S.title() #返回S的副本,所有单词以大写字母开头
S.translate(table[,deletechars]) #返回S的副本,所有字符都使用table进行的转换,可选择删除出现在deletechars中的所有字符
现在有一个dict对象adict,里面包含了一百万个元素,查找其中的某个元素的平均需要多少次比较
O(1) 哈希字典,快速查找,键值映射,键唯一!
有一个list对象alist,里面的所有元素都是字符串,编写一个函数对它实现一个大小写无关的排序
words = ['This','is','a','dog','!']
words.sort(key=lambda x:x.lower())
print words
有一个排好序地list对象alist,查找其中是否有某元素a
alist = ['a','s','d','f']
try:
alist.index('a')
print 'Find it.'
except ValueError:
print 'Not Found.'
请用Python写一个获取用户输入数字,并根据数字大小输出不同信息的脚本
num = input('Enter number: ')
if num > 100:
print 'The number is over 100'
elif 0 < num <= 100:
print 'The number is between 0~100'
elif num < 0:
print 'The number is negative.'
else:
print 'Not a number'
打乱一个排好序的list对象alist
random.shuffle(alist)
# random模块中的shuffle(洗牌函数)
import random
alist = [1, 2, 3, 4]
random.shuffle(alist)
print alist
有二维的list对象alist,假定其中的所有元素都具有相同的长度,写一段程序根据元素的第二个元素排序
def sort_lists(lists, sord, idx):
if sord == ‘desc’:
lists.sort(key=lambda x:x[idx], reverse=True)
else:
lists.sort(key=lambda x:x[idx])
return lists
lists = [[‘cd’,‘ab’],[‘ef’,‘ac’]]
sort_lists(lists,‘desc’,1)
print lists
inspect模块有什么用
inspect模块主要提供了四种用处:
(1). 对是否是模块,框架,函数等进行类型检查。
is{module|class|function|method|builtin}(obj): 检查对象是否为模块、类、函数、方法、内建函数或方法。
isroutine(obj): 用于检查对象是否为函数、方法、内建函数或方法等等可调用类型。
(2). 获取源码
get{file|sourcefile}(object): 获取object的定义所在的模块的文件名|源代码文件名(如果没有则返回None)。
get{source|sourcelines}(object): 获取object的定义的源代码,以字符串|字符串列表返回。
(3). 获取类或函数的参数的信息
getargspec(func): 仅用于方法,获取方法声明的参数,返回元组,分别是(普通参数名的列表, *参数名, **参数名, 默认值元组)。
(4). 解析堆栈
Python处理命令行参数示例代码
# 最简单、最原始的方法就是手动解析了
import sys
for arg in sys.argv[1:]:
print(arg)
介绍一下Python getopt模块
专门处理命令行参数的getopt模块,里面的提供了2个函数和一个类,我们主要使用getopt函数。
getopt这个函数 就是用来抽取 sys.argv 获得的用户输入来确定执行步骤。
getopt是个模块,而这个模块里面又有getopt 函数,所以getopt需要这样这样用。
getopt.getopt( [命令行参数列表], "短选项", [长选项列表] )
该函数返回两个值. opts 和args
opts 是一个存有所有选项及其输入值的元组.当输入确定后,这个值不能被修改了.
args 是去除有用的输入以后剩余的部分.
使用getopt模块分析命令行参数大体上分为三个步骤:
1.导入getopt,sys模块。
2.分析命令行参数。
3**.处理结果**。
mport sys
import getopt
try:
options, remainder = getopt.getopt(sys.argv[1:], 'o:v', ['output=', 'verbose', 'version=',])
except getopt.GetoptError as err:
print 'ERROR:', err
sys.exit(1)
解释如下:
1. 处理所使用的函数叫getopt() ,因为是直接使用import 导入的getopt 模块,所以要加上限定getopt 才可以。
2. 使用sys.argv[1:] 过滤掉第一个参数(它是执行脚本的名字,不应算作参数的一部分)。
3. 使用短格式分析串"ho:" 。当一个选项只是表示开关状态时,即后面不带附加参数时,在分析串中写入选项字符。当选项后面是带一个附加参数时,在分析串中写入选项字符同时后面加一 个":" 号 。所以"ho:" 就表示"h" 是一个开关选项;"o:" 则表示后面应该带一个参数。
4. 使用长格式分析串列表:["help", "output="] 。长格式串也可以有开关状态,即后面不跟"=" 号。如果跟一个等号则表示后面还应有一个参数 。这个长格式表示"help" 是一个开关选项;"output=" 则表示后面应该带一个参数。
5. 调用getopt 函数。函数返回两个列表:opts 和args 。opts 为分析出的格式信息。args 为不属于格式信息的剩余的命令行参数。opts 是一个两元组的列表。每个元素为:( 选项串, 附加参数) 。如果没有附加参数则为空串'' 。
6. 整个过程使用异常来包含,这样当分析出错时,就可以打印出使用信息来通知用户如何使用这个程序。
总结下getopt的特点:
- getopt是从前到后解析
- getopt不检查额外参数的合法性,需要自行检查
- 短命令行和长命令行是分开解析的
Python列表与元组的区别是什么?分别在什么情况下使用?
Python中列表和元祖都是序列。但列表是可变对象,元祖是不可变对象。
元祖主要用于函数赋值,字符串格式化等。但列表中的方法更多些,也是PYTHON中更常用的数据结构。
有一个长度是101的数组,存在1~100的数字,有一个是重复的,拿重复的找出来
# Python中,主要是拿count(i) ==2的找出来即可,再利用列表推导式
>>> l = [1, 2, 3, 4, 2]
>>> tmp = []
>>> [tmp.append(i) for i in l if l.count(i) == 2]
[None, None]
>>> tmp
[2, 2]
>>> set(tmp)
set([2])
set是在哪个版本成为build-in types的?举例说明,并说明为什么当时选择了set这种数据结构
python的set和其他语言类似, 是一个无序不重复元素集, 基本功能包括关系测试和消除重复元素. 集合对象还支持union(联合), intersection(交), difference(差)和sysmmetric difference(对称差集)等数学运算.
sets 支持 x in set, len(set),和 for x in set。作为一个无序的集合,sets不记录元素位置或者插入点。因此,sets**不支持 indexing, slicing, 或其它类序列(sequence-like)**的操作。
集合支持一系列标准操作,包括并集、交集、差集和对称差集,例如:
a = t | s # t 和 s的并集
b = t & s # t 和 s的交集
c = t – s # 求差集(项在t中,但不在s中)
d = t ^ s # 对称差集(项在t或s中,但不会同时出现在二者中)
说说decorator的用法和它的应用场景,如果可以的话,写一个decorator
装饰器是将一个函数镶嵌在另一个函数中进行重复使用的目的,增加函数的使用方式,但是不用写过多冗余的代码。
所谓装饰器就是把函数包装一下,为函数添加一些附加功能,装饰器就是一个函数,参数为被包装的函数,返回包装后的函数:
功能:
引入日志
函数执行时间统计
执行函数前预备处理
执行函数后的清理功能
权限校验等场景
缓存
def a(func):
print(1)
def b(*args,**kwargs):
print(2)
func(*args,**kwargs)
print(3)
return b
@a
def c(a,b):
print(a+b)
c(3,4)
说一说你见过比较cool的python实现
cool的概念,角度不同,看法可能也就不同,个人觉得更Pythonic的代码就是最酷的代码。
Python自动连接ssh的代码
1.使用pexpect模块
Pexpect 的使用范围很广,可以用来实现与 ssh、ftp 、telnet 等程序的自动交互;可以用来自动复制软件安装包并在不同机器自动安装;还可以用来实现软件测试中与命令行交互的自动化。
pexpect 的使用围绕3个关键命令做操作:
首先用 spawn 来执行一个程序
然后用 expect 来等待指定的关键字,这个关键字是被执行的程序打印到标准输出上面的
最后当发现这个关键字以后,根据关键字用 send 方法来发送字符串给这个程序。
import pexpect
def ssh_cmd(host, user,passwd, cmd):
ret = -1
ssh = pexpect.spawn('ssh user@%s "%s"' % (host, cmd))
try:
i = ssh.expect(['password:', 'continue connecting (yes/no)?'], timeout=5) //等待指定关键字
if i == 0 :
ssh.sendline(passwd) //发送密码
elif i == 1:
ssh.sendline('yes\n')
ssh.expect('password: ')
ssh.sendline(passwd)
ssh.sendline(cmd) //发送命令
res = ssh.read()
print res
ret = 0
except pexpect.EOF:
print "EOF"
ssh.close()
ret = -1
except pexpect.TIMEOUT:
print "TIMEOUT"
ssh.close()
ret = -2
return ret
2.使用pxshh
针对ssh远程登录,pexpect又派生出了pxssh类,在ssh会话操作上再做一层封装
其常用方法是:
login() #建立ssh连接
logout() #断开ssh连接
prompt() #等待系统提示符,用于等待命令执行结束
from pexpect import pxssh
def ssh_cmd(host,username,password,cmd):
try:
s = pxssh.pxssh() #实例化一个对象
s.login(host,username,password) #登录
s.sendline(cmd) #执行命令
s.prompt() #匹配cmd执行后的下一步操作的命令提示符
print s.before #输出命令提示符之前的内容
s.logout() #登出
except :
print "pxssh failed on login."
介绍一下Python Date Time方面的类
Python提供了多个内置模块用于操作日期时间,像calendar,time,datetime。
一.time模块
time模块提供各种操作时间的函数
一般有两种表示时间的方式:
第一种: 是时间戳的方式(相对于1970.1.1 00:00:00以秒计算的偏移量),时间戳是惟一的
第二种: 以数组的形式表示即(struct_time),共有九个元素,分别表示,同一个时间戳的struct_time会因为时区不同而不同
二.datetime模块
相比于time模块,datetime模块的接口则更直观、更容易调用。
datetime模块定义了下面这几个类:
datetime.date:表示日期的类。常用的属性有year, month, day;
datetime.time:表示时间的类。常用的属性有hour, minute, second, microsecond;
datetime.datetime:表示日期时间。
datetime.timedelta:表示时间间隔,即两个时间点之间的长度。
datetime.tzinfo:与时区有关的相关信息。
datetime中,表示日期时间的是一个datetime对象
datetime中提供了strftime方法,可以将一个datetime型日期转换成字符串:
Tkinter的ToolTip控件
Tooltip控件是一个简单,但非常有用的控件。它能够为我们的软件提供非常漂亮的提示信息,提高软件的可用性,给用户比较好的体验。 提供提示信息。
解释一下python的and-or语法
0 and * 不需要再考虑*是0还是1,结果是0
1 and * 需要考虑*是0还是1来决定结果。
1 or * 不需要考虑后面的*,结果为1
0 or * 需要考虑后面的*来决定结果
?Python里关于“堆”这种数据结构的模块是哪个?“堆”有什么优点和缺点
实现一个stack
通过list来实现,初始化self._items=list(),然后对list进行操作
class Stack :
def __init__( self ):
''''' Creates an empty stack. '''
self._items = list()
def isEmpty(self):
''''' Returns True if the stack is empty or False otherwise. '''
return len(self) == 0
def __len__(self):
''''' Returns the number of items in the stack. '''
return len(self._items)
def peek(self):
''''' Returns the top item on the stack without removing it. '''
assert not self.isEmpty(), "Cannot peek at an empty stack"
return self._items[-1]
def pop(self):
''''' Removes and returns the top item on the stack. '''
assert not self.isEmpty(), "Cannot pop from an empty stack"
return self._items.pop()
def push(self,item):
''''' Push an item onto the top of the stack. '''
self._items.append( item )
?编写一个简单的ini文件解释器
src = “security/afafsff/?ip=123.4.56.78&id=45”,请写一段代码用正则匹配出IP
ip地址的正则表达式:(2(5[0-5]{1}|[0-4]\d{1})|[0-1]?\d{1,2})(\.(2(5[0-5]{1}|[0-4]\d{1})|[0-1]?\d{1,2})){3}
import re
src = "security/afafsff/?ip=123.4.56.78&id=45"
rr=re,compile('(2(5[0-5]{1}|[0-4]\d{1})|[0-1]?\d{1,2})(\.(2(5[0-5]{1}|[0-4]\d{1})|[0-1]?\d{1,2})){3}')
m = re.serach(rr, src) # re.S 改变'.'的行为
print m
已知仓库中有若干商品,以及相应库存,类似: 袜子,10 鞋子,20 拖鞋,30 项链,40 要求随机返回一种商品,要求商品被返回的概率与其库存成正比。请描述实现的思路或者直接写一个实现的函数
random.sample()
# -*- coding: utf-8 -*-
import random
Wa_Zi = ['WZ'] * 100
Xie_Zi = ['XZ'] * 200
Tuo_Xie = ['TX'] * 300
Xiang_Lian = ['XL'] * 400
All_Before = Wa_Zhi + Xie_Zi + Tuo_Xie + Xiang_Lian
All_After = random.sample(All_Before, 100) //从指定的序列中,随机的截取指定长度的片断,不作原地修改
print All_After.count('WZ')
print All_After.count('XZ')
print All_After.count('TX')
print All_After.count('XL')
list = [a,a,a,1,2,3,4,5,A,B,C]提取出”12345”
这个考点考了python的解压赋值的知识点,即 a,b,c,*middle, e,f,g = list, *middle = [1,2,3,4,5]。注意,解压赋值提取出来的是列表。
python的面向对象?
类是对象的蓝图和模板,而对象是类的实例。类是抽象的概念,而对象是具体的东西。在面向对象编程的世界中,一切皆为对象,对象都有属性和行为,每个对象都是独一无二的,而且对象一定属于某个类(型)。当我们把一大堆拥有共同特征的对象的静态特征(属性)和动态特征(行为)都抽取出来后,就可以定义出一个叫做“类”的东西。面向对象有三大支柱:封装、继承和多态。
类的初始化:new() 和 init()?
new()方法用来实例化最终的类对象,在类创建之前被调用,它在类的主体被执行完后开始执行。
init()方法是在类被创建之后被调用,用来执行其他的一些输出化工作
当我们构造元类的时候,通常只需要定一个init()或new()方法,但不是两个都定义。但是,如果需要接受其他的关键词参数的话,这两个方法就要同时提供,并且都要提供对应的参数签名。
__init__方法做的事情是在对象创建好之后初始化变量。真正创建实例的是__new__方法。__new__方法用于创建对象并返回对象,当返回对象时会自动调用__init__方法进行初始化。
1、new至少要有一个参数cls,代表当前类,此参数在实例化时由Python解释器自动识别
2、__new__必须要有返回值,返回实例化出来的实例,这点在自己实现__new__时要特别注意,可以return父类(通过super(当前类名, cls))__new__出来的实例,或者直接是object的__new__出来的实例
3、init有一个参数self,就是这个__new__返回的实例,__init__在__new__的基础上可以完成一些其它初始化的动作,__init__不需要返回值
4、如果__new__创建的是当前类的实例,会自动调用__init__函数,通过return语句里面调用的__new__函数的第一个参数是cls来保证是当前类实例,如果是其他类的类名,;那么实际创建返回的就是其他类的实例,其实就不会调用当前类的__init__函数,也不会调用其他类的__init__函数。
多线程?
多线程可以共享进程的内存空间,因此要实现多个线程之间的通信相对简单,比如设置一个全局变量,多个线程共享这个全局变量。但是当多个线程共享一个资源的时候,可能导致程序失效甚至崩溃,如果一个资源被多个线程竞争使用,那么对临界资源的访问需要加上保护,否则会处于“混乱”状态,比如银行存100块钱,最终很可能存不到一百块多个线程得到的余额状态都是0,所有操作都是在0上面加1,从而导致错误结果。这种情况下,锁就可以得到用处了。多线程并不能发挥cpu多核特性,因为python解释器有一个gil锁,任何线程执行前必须获得GIL锁,然后每执行100条字节码,解释器就会自动释放GIL锁让别的线程有机会执行
给定一串字典(或列表),找出指定的(前N个)最大值?最小值?
这道题的考点是python内的heapq模块的nlargest() 和 nsmallest()
import heapq
nums=[1,8,2,23,7,-4,18,23,42,37,2]
print(heapq.nlargest(3,nums))
[42, 37, 23]
>>> print(heapq.nsmallest(3,nums))
[-4, 1, 2]
portfolio = [
{'name': 'IBM', 'shares': 100, 'price': 91.1},
{'name': 'AAPL', 'shares': 50, 'price': 543.22},
{'name': 'FB', 'shares': 200, 'price': 21.09},
{'name': 'HPQ', 'shares': 35, 'price': 31.75},
{'name': 'YHOO', 'shares': 45, 'price': 16.35},
{'name': 'ACME', 'shares': 75, 'price': 115.65}
]
# 参数3为最大的3个值(最小的3个值)
cheap = heapq.nsmallest(3, portfolio, key=lambda s: s['price'])
expensive = heapq.nlargest(3, portfolio, key=lambda s: s['price'])
# 上面代码在对每个元素进行对比的时候,会以price的值进行比较。
使用字符串拼接达到字幕滚动效果?
os、time
import os
import time
def main():
content = '曹查理的python面试集-基础篇'
while True:
# 清理屏幕上的输出
os.system('cls') # os.system('clear')
print(content)
# 休眠200毫秒
time.sleep(0.2)
content = content[1:] + content[0]
if __name__ == '__main__':
main()
设计一个函数返回给定文件名的后缀?
def get_suffix(filename, has_dot=False):
"""
获取文件名的后缀名
:param filename: 文件名
:param has_dot: 返回的后缀名是否需要带点
:return: 文件的后缀名
"""
pos = filename.rfind('.')#rfind()的使用
if 0 < pos < len(filename) - 1:
index = pos if has_dot else pos + 1
return filename[index:]
else:
return ''
大数据的文件读取
利用生成器generator
迭代器进行迭代遍历:for line in file
迭代器和生成器的区别
迭代器是一个更加抽象的概念,任何对象,如果它的类有next方法和iter方法返回自身。对于string、list、dict、tuple等这类容器对象,使用for循环遍历是很方便的。在后台for语句对容器对象调用iter()函数,iter()是Python的内置函数。iter()会返回一个定义了next()方法的迭代器对象,它在容器中逐个访问容器内元素,next()也是python的内置函数。在没有后续元素时,next()会抛出一个StopIterration的异常。
生成器(Generator)在循环的过程中不断推算出后续的元素,这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制。)是创建迭代器的简单而强大的工具。它们写起来就像是正规的函数,只是在返回数据的时候需要使用yield语句。每次next()被调用时,生成器会返回它脱离的位置(它记忆语句最后一次执行的位置和所有的数据值)
区别:
1.通过实现迭代器协议对应的__iter__()和next()方法,可以自定义迭代器类型。对于可迭代对象,for语句可以通过iter()方法获取迭代器,并且通过next()方法获得容器的下一个元素。
2.生成器是一种特殊的迭代器,内部支持了生成器协议,不需要明确定义__iter__()和next()方法。
3.生成器通过生成器函数产生,生成器函数可以通过常规的def语句来定义,但是不用return返回,而是用yield一次返回一个结果。
生成器能做到迭代器能做的所有事,而且因为自动创建了__iter__()和next()方法,生成器显得特别简洁,而且生成器也是高效的,使用生成器表达式取代列表解析可以同时节省内存。除了创建和保持程序状态的自动生成,当发生器终结时,还会自动跑出StopIterration异常。
如何提高python的运行效率
使用生成器;
关键代码使用外部功能包(Cython,pylnlne,pypy,pyrex);
针对循环的优化–尽量避免在循环中访问变量的属性
描述数组、链表、队列、堆栈的区别?
数组和链表是数据存储方式的概念,数组在连续的空间中存储数据,而链表可以在非连续的空间中存储数据;
队列和堆栈是描述数据存取方式的概念,队列是先进先出,而堆栈是后进先出;队列和堆栈可以用数组来实现,也可以用链表实现。
is 和 == 的区别
is 是检查两个对象是否指向同一块内存空间,而 == 是检查他们的值是否相等。可以看出,is 是比 == 更严格的检查,is 返回True表明这两个对象指向同一块内存,值也一定相同。
Python里和None比较时,为什么是 is None 而不是 == None 呢?
这是因为None在Python里是个单例对象,一个变量如果是None,它一定和None指向同一个内存地址。而 == None背后调用的是__eq__,而__eq__可以被重载
可变对象和不可变对象
Python中有可变对象和不可变对象之分。可变对象创建后可改变但地址不会改变,即变量指向的还是原来的变量;不可变对象创建之后便不能改变,如果改变则会指向一个新的对象。
切片操作相当于浅拷贝,会生成一个新的对象,因此c指向的对象不再是b所指向的对象,对c的操作不会改变b的值。
join的性能明显好于+。这是为什么呢?
原因是这样的,上一篇Python面试之可变对象和不可变对象中讲过字符串是不可变对象,当用操作符+连接字符串的时候,每执行一次+都会申请一块新的内存,然后复制上一个+操作的结果和本次操作的右操作符到这块内存空间,因此用+连接字符串的时候会涉及好几次内存申请和复制。而join在连接字符串的时候,会先计算需要多大的内存存放结果,然后一次性申请所需内存并将字符串复制过去,这是为什么join的性能优于+的原因。所以在连接字符串数组的时候,我们应考虑优先使用join。
https://blog.csdn.net/weixin_41666747/article/details/79942847
一行代码实现1–100之和
利用sum()函数求和
sum([i for i in range(1,101)])
如何在一个函数内部修改全局变量
利用global 修改全局变量
列出5个python标准库
os:提供了不少与操作系统相关联的函数
sys: 通常用于命令行参数
re: 正则匹配
math: 数学运算
datetime:处理日期时间
字典如何删除键和合并两个字典
del 和 update
del dict["key1]
dixt1.update(dict2)
fun(args,**kwargs)中的args,**kwargs什么意思?
*args:非键值对可变数量的参数列表
**kwargs:不定长度的键值对参数,生成dict{}形式
python2和python3的range(100)的区别
python2返回列表,python3返回迭代器,节约内存
一句话解释什么样的语言能够用装饰器?
函数可以作为参数传递的语言,可以使用装饰器
python内建数据类型有哪些
整型–int
布尔型–bool
字符串–str
列表–list
元组–tuple
字典–dict
列表[1,2,3,4,5],请使用map()函数输出[1,4,9,16,25],并使用列表推导式提取出大于10的数,最终输出[16,25]
def fn(x):
return x**2
list=[1,2,3,4,5]
res=map(fn,list)
finalre=[i for i in res if i>10]
map()函数第一个参数是fun,第二个参数是一般是list,第三个参数可以写list,也可以不写,根据需求
避免转义给字符串加哪个字母表示原始字符串?
r , 表示需要原始字符串,不转义特殊字符
中国
,用正则匹配出标签里面的内容(“中国”),其中class的类名是不确定的
. 任意;*0或多次;+1或多次;?0或一次
Import re
str=""
pattern=re.compile(r'(.*?)')
result=pattern.findall(str)
python中断言方法举例
assert()方法,断言成功,则程序继续执行,断言失败,则程序报错
python2和python3区别?列举5个
1、Python3 使用 print 必须要以小括号包裹打印内容,比如 print(‘hi’)
Python2 既可以使用带小括号的方式,也可以使用一个空格来分隔打印内容,比如 print ‘hi’
2、python2 range(1,10)返回列表,python3中返回迭代器,节约内存
3、python2中使用ascii编码,python3中使用utf-8编码
4、python2中unicode表示字符串序列,str表示字节序列
python3中str表示字符串序列,byte表示字节序列
5、python2中为正常显示中文,引入coding声明,python3中不需要
6、python2中是raw_input()函数,python3中是input()函数
列出python中可变数据类型和不可变数据类型,并简述原理
不可变数据类型:数值型、字符串型string和元组tuple
不允许变量的值发生变化,如果改变了变量的值,相当于是新建了一个对象,而对于相同的值的对象,在内存中则只有一个对象(一个地址),如下图用id()方法可以打印对象的id
可变数据类型:列表list和字典dict;
允许变量的值发生变化,即如果对变量进行append、+=等这种操作后,只是改变了变量的值,而不会新建一个对象,变量引用的对象的地址也不会变化,不过对于相同的值的不同对象,在内存中则会存在不同的对象,即每个对象都有自己的地址,相当于内存中对于同值的对象保存了多份,这里不存在引用计数,是实实在在的对象。
用lambda函数实现两个数相乘
res=lambda x,y:x*y
print(res(3,4)
字典根据键从小到大排序dict={“name”:“zs”,“age”:18,“city”:“深圳”,“tel”:“1362626627”}
list=sorted(dict.items(),key=lambda x:x[0])
newdict={}
for i in list:
newdict[i[0]]=i[1]
利用collections库的Counter方法统计字符串每个单词出现的次数"kjalfj;ldsjafl;hdsllfdhg;lahfbl;hl;ahlf;h"
from collections import Counter
string=""
res=Counter(string)
字符串a = “not 404 found 张三 99 深圳”,每个词中间是空格,用正则过滤掉英文和数字,最终输出"张三 深圳"
import re
list=str.split()
res=re.findall(r'\d+|[a-zA-Z]+',str)
for i in res:
if i in list:
list.remove(i)
newstr=" ".join(list)
filter方法求出列表所有奇数并构造新列表,a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,然后返回 True 或 False,最后将返回 True 的元素放到新列表
def fn(x):
return x%2==1
res=filter(fn,a)
newlist=[i for i in res]
列表推导式求列表所有奇数并构造新列表,a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
[i for i in a if i%2==1]
正则re.complie作用
re.compile是将正则表达式编译成一个对象,加快速度,并重复使用
两个列表[1,5,7,9]和[2,2,6,8]合并为[1,2,2,3,6,7,8,9]
extend可以将另一个集合中的元素逐一添加到列表中,区别于append整体添加
用python删除文件和用linux命令删除文件方法
python:os.remove(文件名)
linux: rm 文件名
***?log日志中,我们需要用时间戳记录error,warning等的发生时间,请用datetime模块打印当前时间戳 “2018-04-01 11:38:54” 顺便把星期的代码也贴上了
import datetime
a=str(datetime.datetime.now().strftime('%Y-%M-%D %H:%M:%S') +"星期:"+datetime.datetime.now().isoweekday())
print(a)
数据库优化查询方法
外键、索引、联合查询、选择特定字段等等
请列出你会的任意一种统计图(条形图、折线图等)绘制的开源库,第三方也行
pychart、matplotlib
写一段自定义异常代码
自定义异常用raise抛出异常
**简述Django的orm
ORM,全拼Object-Relation Mapping,意为对象-关系映射
实现了数据模型与数据库的解耦,通过简单的配置就可以轻松更换数据库,而不需要修改代码只需要面向对象编程,orm操作本质上会根据对接的数据库引擎,翻译成对应的sql语句,所有使用Django开发的项目无需关心程序底层使用的是MySQL、Oracle、sqlite…,如果数据库迁移,只需要更换Django的数据库引擎即可

39、[[1,2],[3,4],[5,6]]一行代码展开该列表,得出[1,2,3,4,5,6]
列表推导式
[j for i in list for j in i]
将列表转成numpy矩阵,通过numpy的flatten()方法
import numpy
b=numpy.array(list).flatten().tolist()
x=“abc”,y=“def”,z=[“d”,“e”,“f”],分别求出x.join(y)和x.join(z)返回的结果
join()括号里面的是可迭代对象,x插入可迭代对象中间,形成字符串,结果一致,有没有突然感觉字符串的常见操作都不会玩了
顺便建议大家学下os.path.join()方法,拼接路径经常用到,也用到了join,和字符串操作中的join有什么区别
dbaceabcf
举例说明异常模块中try except else finally的相关意义
try…except…else没有捕获到异常,执行else语句
try…except…finally不管是否捕获到异常,都执行finally语句
举例说明zip()函数用法
zip()函数在运算时,会以一个或多个序列(可迭代对象)做为参数,返回一个元组的列表。同时将这些序列中并排的元素配对。
zip()参数可以接受任何类型的序列,同时也可以有两个以上的参数;当传入参数的长度不同时,zip能自动以最短序列长度为准进行截取,获得元组。
a=“张明 98分”,用re.sub,将98替换为100
import re
re.sub(r'\d+','100',a)
写5条常用sql语句
show databases;
show tables;
desc 表名;#显示表结构
select * from 表名;
delete from 表名 where id=5;
update students set gender=0,hometown=“北京” where id=5
a="hello"和b="你好"编码成bytes类型
b'hello'
b.encode()
[1,2,3]+[4,5,6]的结果是多少?
两个列表相加,等价于extend
提高python运行效率的方法
1、使用生成器,因为可以节约大量内存
2、循环代码优化,避免过多重复代码的执行
3、核心模块用Cython PyPy等,提高效率
4、多进程、多线程、协程
5、多个if elif条件判断,可以把最有可能先发生的条件放到前面写,这样可以减少程序判断的次数,提高效率
简述mysql和redis区别
redis: 内存型非关系数据库,数据保存在内存中,速度快
mysql:关系型数据库,数据保存在磁盘中,检索的话,会有一定的Io操作,访问速度相对慢
遇到bug如何处理
打印;查看官方文档和技术博客,bug总结,借用工具;
1、细节上的错误,通过print()打印,能执行到print()说明一般上面的代码没有问题,分段检测程序是否有问题,如果是js的话可以alert或console.log
2、如果涉及一些第三方框架,会去查官方文档或者一些技术博客。
3、对于bug的管理与归类总结,一般测试将测试出的bug用teambin等bug管理工具进行记录,然后我们会一条一条进行修改,修改的过程也是理解业务逻辑和提高自己编程逻辑缜密性的方法,我也都会收藏做一些笔记记录。
4、导包问题、城市定位多音字造成的显示错误问题
正则匹配,匹配日期2018-03-20
url=‘https://sycm.taobao.com/bda/tradinganaly/overview/get_summary.json?dateRange=2018-03-20|2018-03-20&dateType=recent1&device=1&token=ff25b109b&_=1521595613462’
提取一段特征语句,用(.*?)匹配即可
import re
re.findall(r'dateRange=(.*?)%7C(.*?)$')
list=[2,3,5,4,9,6],从小到大排序,不许用sort,输出[2,3,4,5,6,9] 利用min()方法求出最小值,原列表删除最小值,新列表加入最小值,递归调用获取最小值的函数,反复操作
def getmin(list):
x=min(list)
list.remove(x)
newlist.append(x)
if len(list)>0:
getmin(list)
return newlist
写一个单列模式 因为创建对象时**__new__方法执行,并且必须return 返回实例化出来的对象所cls.__instance是否存在,不存在的话就创建对象,存在的话就返回该对象**,来保证只有一个实例对象存在(单列),打印ID,值一样,说明对象同一个
class Singleton(cls):
_instance=None
def __new__(cls,*args,**kwargs):
if not cls.__instance:
return cls._instance=object.__new__(cls)
return cls.__instance
保留两位小数
题目本身只有a="%.03f"%1.3335,让计算a的结果,为了扩充保留小数的思路,提供round方法(数值,保留位数)
round(a,2)
求三个方法打印结果
fn(“one”,1)直接将键值对传给字典;
fn(“two”,2)因为字典在内存中是可变数据类型,所以指向同一个地址,传了新的额参数后,会相当于给字典增加键值对
fn(“three”,3,{})因为传了一个新字典,所以不再是原先默认参数的字典

分别从前端、后端、数据库阐述web项目的性能优化
前端优化:
1、减少http请求、例如制作精灵图
2、html和CSS放在页面上部,javascript放在页面下面,因为js加载比HTML和Css加载慢,所以要优先加载html和css,以防页面显示不全,性能差,也影响用户体验差
后端优化:
1、缓存存储读写次数高,变化少的数据,比如网站首页的信息、商品的信息等。应用程序读取数据时,一般是先从缓存中读取,如果读取不到或数据已失效,再访问磁盘数据库,并将数据再次写入缓存。
2、异步方式,如果有耗时操作,可以采用异步,比如celery
3、代码优化,避免循环和判断次数太多,如果多个if else判断,优先判断最有可能先发生的情况
数据库优化:
1、如有条件,数据可以存放于redis,读取速度快
2、建立索引、外键等
使用pop和del删除字典中的"name"字段,dic={“name”:“zs”,“age”:18}
dic.pop('name')
del dic['name']
简述any()和all()方法
any():只要迭代器中有一个元素为真就为真
all():迭代器中所有的判断项返回都是真,结果才为真
python中什么元素为假?
答案:(0,空字符串,空列表、空字典、空元组、None, False)
IOError、AttributeError、ImportError、IndentationError、IndexError、KeyError、SyntaxError、NameError分别代表什么异常
IOError:输入输出异常
AttributeError:试图访问一个对象没有的属性
ImportError:无法引入模块或包,基本是路径问题
IndentationError:语法错误,代码没有正确的对齐
IndexError:下标索引超出序列边界
KeyError:试图访问你字典里不存在的键
SyntaxError:Python代码逻辑语法出错,不能执行
NameError:使用一个还未赋予对象的变量
sort 和sorted排序的区别
sort无返回值,sorted有返回值
利用lambda排序
对list排序foo = [-5,8,0,4,9,-4,-20,-2,8,2,-4],使用lambda函数从小到大排序
res=sorted(list,key=lambda x:x)
*?使用lambda函数对list排序foo = [-5,8,0,4,9,-4,-20,-2,8,2,-4],输出结果为 [0,2,4,8,8,9,-2,-4,-4,-5,-20],正数从小到大,负数从大到小
foo=[-5,8,0,4,9,-4,-20,-2,8,2,-4]
res=sorted(foo,key=lambda x:(x<0,abs(x)))
print(res)
列表嵌套字典的排序,分别根据年龄和姓名排序
foo = [{“name”:“zs”,“age”:19},{“name”:“ll”,“age”:54},
{“name”:“wa”,“age”:17},{“name”:“df”,“age”:23}]
res=sorted(foo,key=lambda x:x['name'])
res=sorted(foo,key=lambda x:x['age'])
列表嵌套元组,分别按字母和数字排序
res=sorted(foo,key=lambda x:x[0]) #元组索引
列表嵌套列表排序,年龄数字相同怎么办?

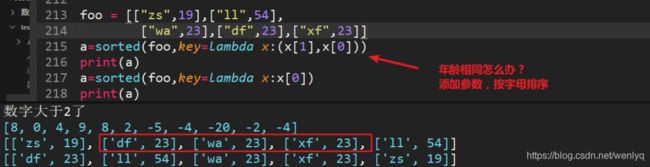
res=sorted(foo,key=lambda x:(x[0],x[1]))
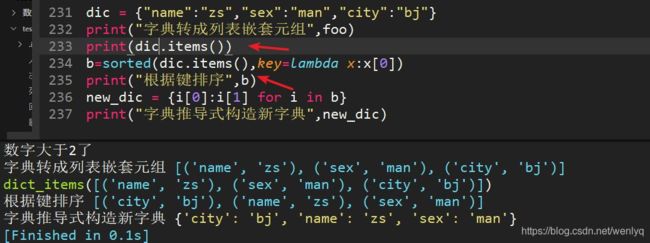
根据键对字典排序
法一:.items()获得键对元组,然后lamda x:x[0]

res=sorted(dict.items(),key=x:x[0])
newdict=[i[0]:i[1] for i in res]
法二:zip()构建键对元组列表,再排序
foo=zip(dict.keys(),dict.values())
foo=[i for i in foo]
res=sorted(foo,key=lambda x:x[0])
根据字符串长度排序
res=sorted(list,key=lambda x:len(x))
list.sort(key=len)
列表推导式、字典推导式、生成器
list=[i for i in range(10)]
dict={key:random.randint(1,6),for key in ['a','b','c','d']}
listgenerator=(i for i in range(10))
*举例说明SQL注入和解决办法
SQL注入:当以字符串格式化方式书写的时候,如果用户的输入含有 ;+SQL语句,后面的SQL语句会执行,导致SQL注入
inputname=input()
sql='select * from students where name=%s' %inputname
cursor.execute(sql)
如输入 yamonica;drop database students;则sql语句为select * from students where name=yamonica;drop database students
会执行删除数据库的命令,导致注入
解决方法:通过传参方式解决
parameter=[inputname]
sql='select * from students where name=%s'
cursor.execute(sql,parameter)
s=“info:xiaoZhang 33 shandong”,用正则切分字符串输出[‘info’, ‘xiaoZhang’, ‘33’, ‘shandong’]
res=s.split(':| ')
正则
正则匹配以163.com结尾的邮箱
emaillist=[ ]
for email in emaillist:
res=re.findall(r'[\w]{4,20}@163.com$',email)
if res:
print(email)
正则匹配不是以4和7结尾的手机号
re,match(r'1\d{9}[0-3,5-6,8-9]$',phonrnum)
正则表达式匹配第一个URL
findall结果无需加group(),search需要加group()提取
res=re.findall(r'http://(.*?).jpg',str)
res=re.search(r'http://(.*?).jpg',str)
res.group()
正则匹配中文
pattern=re.compile(r'[\u4e00-\u9fa5]')
result=pattern.findall(str)
正则表达式匹配出
www.itcast.cn
前面的<>和后面的<>是对应的,可以用此方法
<\w*><\w*>(.*?)
递归求和
def sum(n):
if n<1:
return 0
else:
return n+sum(n-1)
?python字典和json字符串相互转化方法
json.dumps()字典转json字符串,json.loads()json转字典

用两种方法去空格
法一:replace
str.replace(' ','')
法二:按空格split()成列表,再join
strlist=str.split(' ')
res=''.join(strlist)
列举3条以上PEP8编码规范
1、顶级定义之间空两行,比如函数或者类定义。
2、方法定义、类定义与第一个方法之间,都应该空一行
3、三引号进行注释
4、使用Pycharm、Eclipse一般使用4个空格来缩进代码
search 和match
search()函数会在整个字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。
简述乐观锁和悲观锁
悲观锁, 就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
乐观锁,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制,乐观锁适用于多读的应用类型,这样可以提高吞吐量
r、r+、rb、rb+文件打开模式区别
r\rb:只读
r+\rb+:读写
b:二进制格式
python传参数是传值还是传址?
Python中函数参数是引用传递(注意不是值传递)。对于不可变类型(数值型、字符串、元组),因变量不能修改,所以运算不会影响到变量自身;而对于可变类型(列表字典)来说,函数体运算可能会更改传入的参数变量。
python中读取Excel文件的方法
应用数据分析库pandas
import pandas
res=pandas.read_excel('aa.xls')
简述多线程、多进程
进程:
1、操作系统进行资源分配和调度的基本单位,多个进程之间相互独立
2、稳定性好,如果一个进程崩溃,不影响其他进程,但是进程消耗资源大,开启的进程数量有限制
线程:
1、CPU进行资源分配和调度的基本单位,线程是进程的一部分,是比进程更小的能独立运行的基本单位,一个进程下的多个线程可以共享该进程的所有资源
2、如果IO操作密集,则可以多线程运行效率高,缺点是如果一个线程崩溃,都会造成进程的崩溃
应用:
IO密集的用多线程,在用户输入,sleep 时候,可以切换到其他线程执行,减少等待的时间
CPU密集的用多进程,因为假如IO操作少,用多线程的话,因为线程共享一个全局解释器锁,当前运行的线程会霸占GIL,其他线程没有GIL,就不能充分利用多核CPU的优势
python常见的命令行交互自动化模块有哪些?
a)Import module
b) Import module1,module2
c) From module import *
d) Frommodule import m1,m2,m3
e) From module import logger asmodule_logger
python的底层网络交互模块有哪些?
答案:socket, urllib,urllib3 , requests, grab, pycurl
python网络交互时,二进制打包解包的模块有哪些
答案:打包:pack(), 解包:upk()
python的测试框架有哪些?试列出常用的3个或更多
答案:unittest, nose,unittest2, doctest, pytest