数据压缩2 | 分析RGB文件&YUV文件三通道概率密度,并计算信息熵
分析RGB文件&YUV文件三通道概率密度,并计算信息熵
- 一、知识储备
- 二、 思路概述
- 三、 具体实现
-
- 1. RGB文件
-
- ① 代码详解
- ② 信息熵和可视化呈现
- 2. YUV文件
-
- ① 代码详解
- ② 信息熵和可视化呈现
- 四、 分析总结
-
- 1. 技术方面
- 2. 心态方面
一、知识储备
磨刀不误砍柴工,在进行此项任务之前,你需要了解以下内容:
问题:对down.rgb和down.yuv分析三个通道的概率分布,并计算各自的熵
- 两个文件的分辨率均为256*256;
- YUV为4:2:0采样空间;
- 存储格式为:1) RGB文件按每个像素BGR分量依次存放;2) YUV文件按照全部像素的Y数据块、U数据块和V数据块依次存放。
拆解
- RGB文件R、G、B数值数各占256*256个,且依次排列;
- YUV文件存储方式应为 YV12,属于YUV420格式之一,是一种Plane模式,将Y、U、V分量分别打包,依次存储。其每一个像素点的YUV数据提取遵循YUV420格式的提取方式,即4个Y分量共用一 组UV。

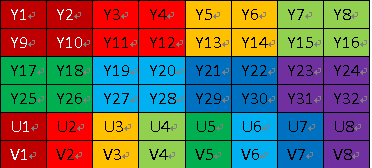
图片来自YUV格式分析详解
视频帧的宽和高分别为w和h,那么一帧YUV420P(即上述YUV12)像素数据一共占用w×h×3/2。其中前w×h存储Y,接着的w×h×1/4存储U,最后w×h×1/4 存储V。
在此问题背景下,可以理解为:
YUV数据的(0~256×256)字节是Y分量值;(256×256~256×256×5/4)字节是U分量;(256×256×5/4~256×256×3/2)字节是V分量。
- 信息熵计算
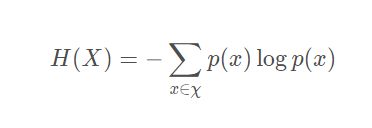
(不会用LaTex,直接word截个图过来了[/扶额],这里比较简单,我就不详细写了,具体可见代码)
二、 思路概述
- 利用
C++分别导入down.rgb,并提取所有数据存在一个Array里面备用,YUV文件处理思路类似,不再赘述; - 按照
背景拆解中的顺序,利用for循环将Array中的数据分别存储到B、G、R数组中; - 再次利用
for循环,统计[0,256]各数值像素个数存入num_r,num_g,num_b,计算H(R ),H(G),H(B),同时将概率freq存入txt文件; - 利用
python处理txt文件,并实现可视化概率分布曲线图。
三、 具体实现
1. RGB文件
① 代码详解
一堆定义
#include② 信息熵和可视化呈现
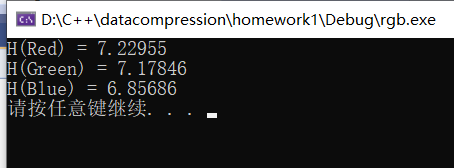
我也是平平无奇的Jupyter选手哈哈(代码在后面,一起写的,懒得切分了):
RGB三通道概率分布图

2. YUV文件
① 代码详解
直接贴不一样的地方吧,其他都差不多:
fread(Array, sizeof(unsigned char), width * height * 3 / 2, Down_yuv);//存储down.rgb中的全部数据到A中
for (int i = 0; i < width * height; i++)
{
Y[i] = Array[i];
}
int m = 0;
for (int i = width * height; i < width * height * 5 / 4; i++)
{
U[m] = Array[i];
m++;
}
int k = 0;
for (int i = width * height * 5 / 4; i < width * height * 3 / 2; i++)
{
V[k] = Array[i];
k++;
}
for (int i = 0; i < 256; i++)
{
for (int j = 0; j < width * height; j++)
{
if (Y[j] == i)
{
num_y[i]++;
}
}
}
for (int i = 0; i < 256; i++)
{
for (int m = 0; m < width * height / 4; m++)
{
if (U[m] == i)
{
num_u[i]++;
}
}
}
for (int i = 0; i < 256; i++)
{
for (int n = 0; n < width * height / 4; n++)
{
if (V[n] == i)
{
num_v[i]++;
}
}
}
//求信息熵
for (int i = 0; i < 256; i++)
{
if (num_y[i] != 0)
{
en_y += (double)num_y[i] / (width * height) * (log(width * height) - log(num_y[i])) / log(2);
}
}
for (int i = 0; i < 256; i++)
{
if (num_u[i] != 0)
{
en_u += (double)num_u[i] / (width * height / 4) * (log(width * height / 4) - log(num_u[i])) / log(2);
}
if (num_v[i] != 0)
{
en_v += (double)num_v[i] / (width * height / 4) * (log(width * height / 4) - log(num_v[i])) / log(2);
}
}
② 信息熵和可视化呈现

YUV三通道概率分布图
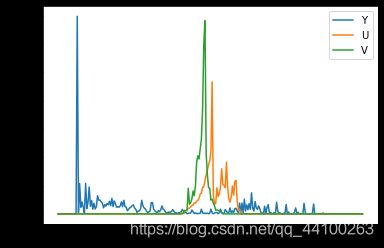
python可视化看下面:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
y_data = pd.read_table("D:\\C++\\datacompression\\homework1\\yuv\\Y_data.txt")
u_data = pd.read_table("D:\\C++\\datacompression\\homework1\\yuv\\U_data.txt")
v_data = pd.read_table("D:\\C++\\datacompression\\homework1\\yuv\\V_data.txt")
dic1 = {
'Y':y_data.freq,'U':u_data.freq,'V':v_data.freq};
yuv_df = pd.DataFrame(dic1)
yuv_df.plot()
plt.show()
# RBG代码不说好像,简直一模一样
四、 分析总结
1. 技术方面
虽然我说要提前准备好,但是实际上自己是边做边学的,写程序和写博客的时间差不多(我的脖子啊……),在上述内容之外,我补充几个自己很生疏的知识点吧(如果有大佬看到了,“别骂了别骂了,在学了在学了”)。:)
fread
fread(void *buffer, size_t size, size_t count, FILE *stream)
buffer 是读取的数据存放的内存的指针(可以是数组,也可以是新开辟的空间,buffer就是一个索引);
size 是每次读取的字节数;
count 是读取次数;
strean 是要读取的文件的指针;
fopen 和 fopen_s
fp = fopen(filename,“w”)。
err = fopen_s(&fp,filename,“w”)
返回值: fopen打开文件成功,返回文件指针赋值给fp,打开失败则返回NULL值; fopen_s打开文件成功返回0,失败返回非0,赋值给err。
2. 心态方面
绝对不要提前看大家的进度!!!
不然真的会崩溃的:哇,大佬好多,做得那么快,还用了各种各样的方法;啊,我就是个小垃圾……
自从老师刚在群里发了正式公告后,我第一次点开云文档的时候就有蓝莹莹的博客链接。在编程中途我又想去瞅两眼,还好理智拉住了我这头牛:看了又如何呢,看了也不可能加快进度,资源虽多,还是需要自己好好辨别的,真酒可贵难得,假酒害人不浅。共勉。
(从完整性和技术性上看,这一篇可能会变成我写的最好的博客)
