利用化合物名称从PubChempy中批量下载化合物信息
利用化合物名称从PubChempy中批量下载化合物信息
已知信息:化合物名称
所用软件及package:python, PubChempy
目的:批量获取化合物的CID, molecular_weight, molecular_mass, CAS等信息。
通过不断的搜索,最终有三种方式进行下载:
第一种:化合物较多
第二种:分次查询单个化合物
第三种:批量下载少量化合物
第一种:批量下载大量化合物
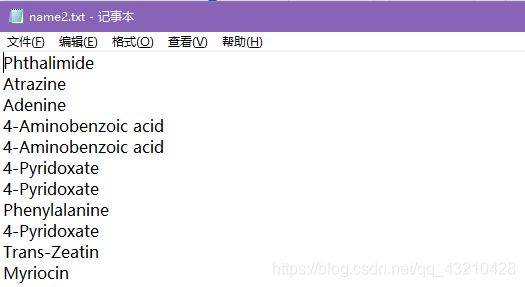
需要先将待下载化合物名称保存为text格式文件。
输入示例:
import urllib
import pubchempy
import pandas as pd
import numpy as np
with open('D:\\name.txt','r',encoding='utf-8-sig') as file1:
file_lines = file1.readlines()
name_list=[]
a=[]
cc=[]
d=[]
e=[]
f=[]
g=[]
#readlines读取的每行是字符串格式,采用以下代码将其转换成列表格式
for i in file_lines:
j=i.strip() #去掉每行头尾空白
name_list.append(str(j))
for k in name_list:
results = pubchempy.get_compounds(k, 'name')
for l in results:
try:
print('CID: {}\tMass: {}\tName: {}\tMolfor: {}\tSmi: {}\tSyn: {}'.format(l.cid,l.exact_mass,l.iupac_name,l.molecular_formula,l.isomeric_smiles,l.synonyms))
MFs=l.molecular_formula
MWs=l.molecular_weight
ISs=l.isomeric_smiles
Sys=l.synonyms
Cis=l.cid
a.append(k)
cc.append(MFs)
d.append(ISs)
e.append(Sys)
f.append(Cis)
g.append(MWs)
except (pubchempy.BadRequestError,TimeoutError,urllib.error.URLError,ValueError):
pass
dataframe=pd.DataFrame({
'name':a,'molecular_formula':cc,'molecular_weight':g,'smiles':d,'synonyms':e,'cid':f})
dataframe.to_csv ("D://imput.csv",index=False,sep=',')
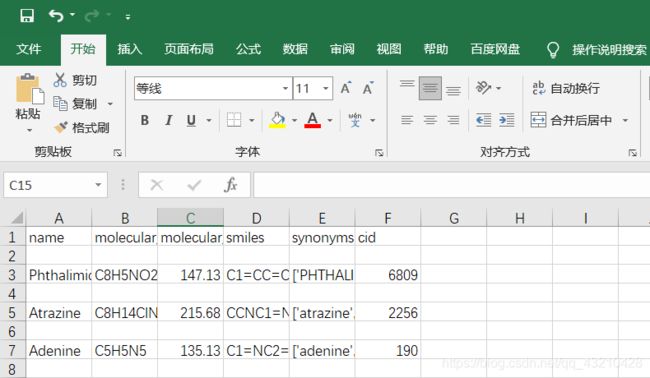
结果输出:
第二种:查询单个化合物的基本信息
1. 直接在python软件中查看输出结果,拷贝使用。
from pubchempy import get_compounds, Compound
for compound in get_compounds('Myriocin-12-en', 'name'):
b1 = compound.cid
c1 = compound.isomeric_smiles
d1 = compound.molecular_formula
e1 = compound.molecular_weight
f1 = compound.iupac_name
print(compound.cid)
print(compound.molecular_weight)
print(compound.molecular_formula)
print(compound.isomeric_smiles)
print(compound.iupac_name)
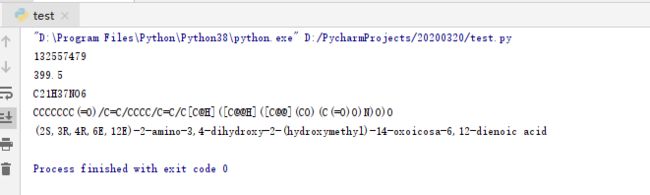
输出结果:
2.输出为excel
from pubchempy import get_compounds, Compound
for compound in get_compounds('Myriocin-12-en', 'name'):
b1 = compound.cid
c1 = compound.isomeric_smiles
d1 = compound.molecular_formula
e1 = compound.molecular_weight
f1 = compound.iupac_name
import pandas as pd
dataframe = pd.DataFrame({
'molecular_weight': e1,
'molecular_formula': d1,
'isomeric_smile': c1,
'iupac_name': f1,
'cid': b1}, index=[0])
dataframe.to_csv("D://1.csv", index=False, sep=',')
#显示所有列
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
#设置value的显示长度为100,默认为50
print(dataframe)
其中,若想同时查看输出结果,可利用print(dataframe)实现,但为了解决输出显示不全,为省略号的情况,可增加“set_option()”功能显示全部输出功能。
第三种:批量下载少量化合物
此种方法代码较多且重复,是起初开始尝试时的做法,需要分别输入化合物名字,故不建议使用,只是做一个记录。
from pubchempy import get_compounds, Compound
for compound in get_compounds('4-Pyridoxate', 'name'):
b1 = compound.cid
c1 = compound.isomeric_smiles
d1 = compound.molecular_formula
e1 = compound.molecular_weight
f1 = compound.iupac_name
for compound in get_compounds('Phenylalanine', 'name'):
b2 = compound.cid
c2 = compound.isomeric_smiles
d2 = compound.molecular_formula
e2 = compound.molecular_weight
f2 = compound.iupac_name
for compound in get_compounds('4-Pyridoxate', 'name'):
b3 = compound.cid
c3 = compound.isomeric_smiles
d3 = compound.molecular_formula
e3 = compound.molecular_weight
f3 = compound.iupac_name
for compound in get_compounds('Trans-Zeatin', 'name'):
b4 = compound.cid
c4 = compound.isomeric_smiles
d4 = compound.molecular_formula
e4 = compound.molecular_weight
f4 = compound.iupac_name
for compound in get_compounds('Myriocin', 'name'):
b5 = compound.cid
c5 = compound.isomeric_smiles
d5 = compound.molecular_formula
e5 = compound.molecular_weight
f5 = compound.iupac_name
for compound in get_compounds('Inosine', 'name'):
b6 = compound.cid
c6 = compound.isomeric_smiles
d6 = compound.molecular_formula
e6 = compound.molecular_weight
f6 = compound.iupac_name
for compound in get_compounds('Indole', 'name'):
b7 = compound.cid
c7 = compound.isomeric_smiles
d7 = compound.molecular_formula
e7 = compound.molecular_weight
f7 = compound.iupac_name
for compound in get_compounds('Anthranilic acid', 'name'):
b8 = compound.cid
c8 = compound.isomeric_smiles
d8 = compound.molecular_formula
e8 = compound.molecular_weight
f8 = compound.iupac_name
for compound in get_compounds('Indole-3-carboxyaldehyde', 'name'):
b9 = compound.cid
c9 = compound.isomeric_smiles
d9 = compound.molecular_formula
e9 = compound.molecular_weight
f9 = compound.iupac_name
#for compound in get_compounds('Indole-3-carboxylic_acid', 'name'):
#b10 = compound.cid
#c10 = compound.isomeric_smiles
#d10 = compound.molecular_formula
# e10 = compound.molecular_weight
#f10 = compound.iupac_name
# 输出数据
import pandas as pd
# dataframe=pd.DataFrame({'molecular_weight':e,'molecular_formula':d,'isomeric_smile':c,'iupac_name':f,'cid':b},
# index = [0])
#上述代码为仅有一个化合物时的输出方法,作为参考
dataframe = pd.DataFrame({
'molecular_weight': [e1, e2, e3, e4, e5, e6, e7, e8, e9],
'molecular_formula': [d1, d2, d3, d4, d5, d6, d7, d8, d9],
'isomeric_smile': [c1, c2, c3, c4, c5, c6, c7, c8, c9],
'iupac_name': [f1, f2, f3, f4, f5, f6, f7, f8, f9],
'cid': [b1, b2, b3, b4, b5, b6, b7, b8, b9]}, index=[1, 2, 3, 4, 5, 6, 7, 8, 9])
dataframe.to_csv("D://1.csv", index=False, sep=',')
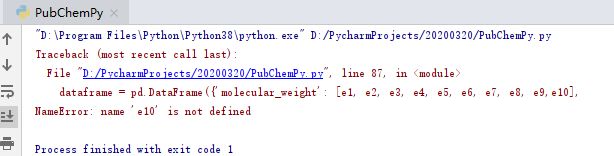
第三种方法还有一个问题就是容易出现下述情况,此种情况只能手动输入进行单独查询了。
参考内容:
链接: link.